


- 收藏
- 加入书签
基于Python的网络爬虫技术在审计数据采集中的运用
 打开文本图片集
打开文本图片集
 < a rel="example_group" title="Custom title" href="http://img.resource.qikan.cn/qkimages/juaz/juaz202212/juaz202212520-3-l.jpg">
< a rel="example_group" title="Custom title" href="http://img.resource.qikan.cn/qkimages/juaz/juaz202212/juaz202212520-3-l.jpg">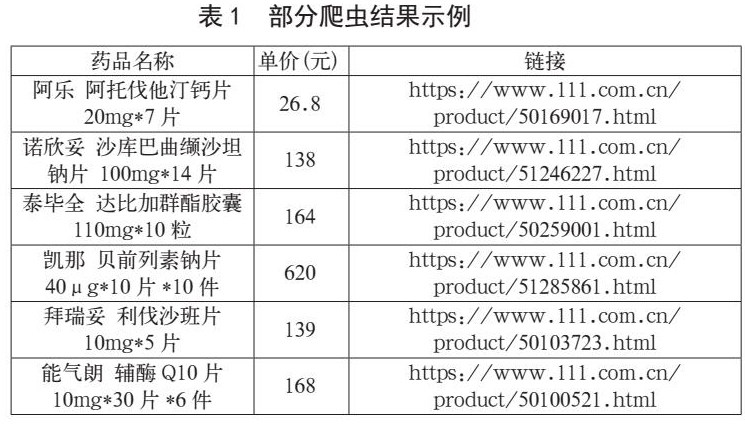
摘要:数据是大数据时代背景下开展审计分析的重要前提,本文将结合Python语言,探讨审计人员如何利用网络爬虫技术从网络渠道获取所需审计的外部数据,从而为审计工作服务。
关键词:网络爬虫;大数据审计;数据采集
一、引言
随着大数据时代的到来,大数据成为各界研究的重点和热点,对大数据的研究和应用逐渐上升到了战略层次。大数据具有数据体量巨大、处理速度快、数量种类多和潜在价值高的特点,许多被审计单位的数据也越来越呈现出海量化趋势。陈雄智(2017)[1]认为,审计信息化“一数一源”是关键,审计数据包括通用数据、基础数据、审计业务数据、系统管理数据等,并提出了构建数据中心和交换中心体系的思路。陈伟、孙梦蝶(2018)[2]总结分析了大数据审计采集过程中存在的问题,提出通过网络爬虫技术获取外部审计外部数据的思路。吴则建、王鹏虎等(2019)[3]认为,大数据审计的前提及首要条件就是获取数据,并探索了主题网络爬虫在商业银行内部审计中的实践应用。
数据是审计分析的重要前提,在审计实践中如何快速有效获取审计数据,将大量的、散落的、无序的数据进行集中化、结构化,使其变成能够方便获得可读取的审计数据,并通过审计分析方法发现清晰有效的审计线索,是当前大数据审计工作面临的重要课题。本文将结合Python语言,探讨审计人员应当如何利用网络爬虫技术从网络渠道获取所需审计的外部数据,从而扩充审计数据的范围,获得更多的审计线索,提高审计分析效果。
二、基于Python的网络爬虫技术概述
(一)Python语言简介
Python是一种跨平台的计算机程序设计语言,是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python不仅简单易学,而且还有丰富的第三方程序库和相应完善的管理工具。自从20世纪90年代公开发布以来,经过二十多年的发展,Python以其语法简洁而高效、类库丰富而强大、适合快速开发、应用领域广等原因,成为当下比较流行的脚本语言之一。同时也广泛应用在数据分析处理、统计、计算可视化、图像处理、网站开发等许多专业领域。
(二)网络爬虫技术基本原理
网络爬虫(web crawler)是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。开展审计需要各类相关数据,因此,网络爬虫技术对获得开展大数据审计的相关数据非常有帮助。基于网络爬虫技术的大数据审计方法主要是充分利用被审计单位外部的公共数据,通过对这些数据和从被审计单位获得以及从其他单位获得的相关数据进行对比分析,从而更充分地发现相关审计线索,相对目前常用的方法,这种方法的优点是能扩展数据分析范围,更充分地发现相关审计线索。采用网络爬虫技术获取相关数据的过程如下:
(1)确定目的。用于确定抓取目标网站哪些网页上的哪些数据。
(2)分析页面结构。为了抓取上述的数据,需要对相应的网页页面进行分析。
(3)实现爬虫,获得所需数据。根据以上分析,采用相关网络爬虫软件,如Python等,实现以上数据的抓取功能。
(4)对获得的数据进行分析。针对获得的数据,在审计大数据集成和预处理的基础上,采用大数据可视化工具对相关数据进行分析,审计人员通过对可视化的分析结果进行观察,快速从被审计大数据信息中发现异常数据,获得审计线索。另外,审计人员可以根据需要,对异常数据做细化分析,从不同的方面获得对被审计数据的理解,从而全面地分析被审计数据。在可视化分析结果的基础上,审计人员可以借助SQL查询方法和审计软件对被审计数据进行建模和分析,进一步获得相关证据。在此基础上,通过对这些结果数据做进一步的延伸审计和审计事实确认,最终获得审计证据。
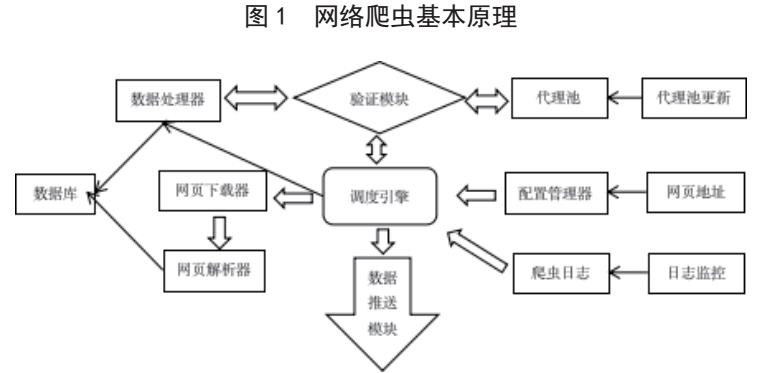
目前,常用的网络爬虫技术包括Python爬虫、Java爬虫、C++爬虫、C#爬虫、PHP爬虫等。相对于其他网络爬虫技术,基于Python的网络爬虫技术具有以下优点:一是简洁方便。Python语言最大的特点就是只需要一个简单的编辑器就能满足大部分用户的网络爬虫技术需求,可以让操作人员很快的适应环境,而不用花费过多的精力;二是具有框架技术。如果所需要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强大的模板来实现爬虫,仅仅需要按照需求进行简单的修改就可以使用,而不是去进行重新的开发。具体如图1所示。
三、基于网络爬虫技术的审计数据采集应用案例
(一)审计背景
近期,Q审计中心派出审计组,对D医院财经管理情况实施审计。2015年,医院通过公开招标选定A公司承担该医院部分药品供应任务。在审计过程中,审计人员初步比对,发现该药品供应商部分药品价格存在同一时期价格不同的现象,审计人员初步判断该供应商供应的部分药品价格可能存在虚高。由于涉及药品数量多、品种杂,审计人员采取对比分析方式,收集了药品供应价,以及政府限价、市场价等外部数据,经大量分析,最终核实了该医院存在药品价格虚高的问题。
(二)应用过程
1.确定目标
为核实是否存在药品价格虚高的问题,审计人员只能考虑从外部获得信息数据进行比较分析,具体包括药品名称、单价及具体链接,从而判断采购价格的合理性。如果考虑从官方网站逐条查询获得具体价格数据,审计人员将面临工作量巨大的问题。此时,网络爬虫技术能够为这一难题提供很好的解决方案,提高工作效率。
2.网页分析
从需要收集的外部数据看,审计人员主要结合“1药网”“药交网”等多个官方渠道进行数据采集。由于篇幅限制,本文以爬取“1药网”相关数据为例。打开“1药网”官方网站并进入检查页面,通过分析HTTP请求方式、网页源代码等,发现采用比较简单的Request库即可实现爬取药价信息。确定爬取方式后,通过搜索尝试,可以找到相关商品的具体代码。以磷酸奥司他韦颗粒为例,可以看出其商品品名和价格所在的具体标签位置,该标签是爬取药品数据的重要依据。
3.代码实现
根据网页分析结果,选取种子URL地址,结合页面链接特征和页面内容中的关键字特征,编写的部分核心源代码示例如下:
def get_text(text):
if text:
return text[0]
return ''
def parse_page(html_str):
tree = etree.HTML(html_str)
li_list = tree.xpath('//ul[@id="itemSearchList"]/li')
for li in li_list:
price=get_text(li.xpath('.//div[@isrecom="0"]/p[1]/textarea/span/text()|.//div[@isrecom="0"]/p[1]/span/text()|.//div[@isrecom="0"]/p[1]/
span/u/text()')).strip()
name = li.xpath('.//div[@isrecom="0"]/p[2]/a/text()')[1].strip()
url=get_text(li.xpath('.//div[@class="itemSearchResult
Con"]/a[1]/@href')).strip()
item = {}
item['price'] = price
item['name'] = name
item['url'] = 'https:' + url
print(item)
infos.append(item)
4.数据分析
审计人员通过Python实现了网络爬虫,从“1药网”上获取相关药品的价格信息,部分药品爬虫结果如表1 所示。结合药品供应价和政府限价,审计人员运用SQL数据库对涉及的药品进行了比对分析,最终核实了该医院60余种药品存在价格虚高的问题,审计组对该问题在审计报告中予以了披露,并建议追回损失以及对相关责任人进行处理。
四、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。通过运用Python网络爬虫技术,可以帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计分析奠定了基础。但同时也可以看出,网络爬虫仅解决了部分数据获取问题,面对实际工作中复杂的审计任务,还需要灵活运用数据挖掘、机器学习算法、数学建模等方法,结合审计人员的专业判断,对多源数据进行细致、专业的分析,这样才能更好地发挥审计监督作用。
参考文献
[1]陈雄智.军队审计信息化教程[M].北京:金盾出版社,2007.
[2]陈伟,孙梦蝶.基于网络爬虫技术的大数据审计方法研究[J].中国注册会计师,2018(07):76-80.
[3]吴则建,王鹏虎,庞瑞江,黄永平.主题网络爬虫在商业银行内部审计中的应用[J].中国内部审计,2019(11):50-53.
作者简介
廖智玮(1992.1-)女,土家族,贵州思南人,硕士研究生学历,中国人民解放军成都资金收付管理中心第二结算室,助理会计师,研究方向:会计。
袁静(1989.05-)男 ,汉族,四川眉山人,硕士研究生学历,军委审计署重庆审计中心,助理工程师,研究方向:军队审计。

 京公网安备 11011302003690号
京公网安备 11011302003690号

