



- 收藏
- 加入书签

成人高等教育对企业用人单位员工绩效的影响研究
 打开文本图片集
打开文本图片集



摘要:本研究首先采用问卷调查的形式,重点针对国内25家典型的中型企业进行调研分析,深入了解了相关企业的成人高等教育和员工绩效情况。经过检验,本问卷的克隆巴赫系数为0.89证明问卷准确合理。运用了t检验和描述性统计,对25家企业的高等教育程度进行分析,得出了25家企业之间高等教育程度具有显著性差异的结论;为了探究成人高等教育与企业员工绩效的相关性,采用了灰色关联分析,求解了四个衡量成人高等教育指标与员工绩效的关联系数,得到了“高等教育比例”和“校企合作频率”对企业用人单位的员工绩效影响相对较大的结论;利用了基于主成分分析的多元回归分析,求解出了成人高等教育指标于企业员工绩效的量化关系和具体的多元回归方程。
关键词:描述性统计;t检验;灰色关联;主成分分析;多元回归分析
一、引言
成人高等教育作为终身学习的一种形式,为广大在职人员提供了继续学习和提升自身素质的机会。在当前竞争激烈的职场环境中,企业用人单位越来越重视员工的综合素质和能力。因此,本研究旨在探讨成人高等教育对企业用人单位员工绩效的影响,以期为企业和员工提供相关的决策依据和建议。
二、研究对象与研究方法
2.1研究对象
本研究针对成人高等教育对企业用人单位员工绩效的影响进行研究,为了确保研究结果的准确性,选取了国内25家具有代表性的中型企业作为研究对象,并利用整群随机抽样法进行问卷调查。这次问卷调查发放问卷200份,回收问卷117份,回收率为58.5%。为了进一步提升研究的可信度,再针对这117家企业进行逐个访谈,最终选取25家真实性高的问卷作为研究数据。
本次研究选取受高等教育比例、学历结构、员工继续教育情况、校企合作频率四个指标来衡量企业的成人高等教育程度;选取企业人均利润、资产回报率、生产效率三个指标衡量企业用人单位绩效。经过检验,本问卷的克隆巴赫系数α为0.89,说明问卷的内部可信度高,问卷调查结果可靠,可以作为研究数据。
研究所选取的25家企业依次用1到25的序号表示。
2.2研究方法
(1)t检验(t-test):t检验是一种统计方法,用于比较两个样本的均值是否显著不同。它适用于具有连续性数据的研究。基本原理是通过计算两个样本的均值差异相对于它们的变异程度来确定差异的显著性。如果计算得到的t值大于临界t值,就可以得出结论,即两个样本的均值差异是显著的。
(2)灰色关联分析(Grey Relational Analysis):是一种用于研究变量之间关联性的方法,特别适用于数据有限或不完整的系统。它通常用于处理样本较小、存在非线性关系或数据存在不确定性的系统。通过比较数据序列之间的关联程度来揭示变量之间的相似性和重要性。它提供了一种有效的分析工具,可以在数据有限或不完整的情况下探索变量之间的关系,为决策提供有价值的洞察和指导。
(3)主成分分析(Principal Component Analysis):一种常用的统计方法,用于降低数据集的维度并保留大部分原始信息。它旨在将一组相关变量转化为一组无关变量,称为主成分。这些主成分是原始变量的线性组合,并按照它们在数据中解释的方差大小进行排序。
(4)多元回归分析(Multiple Regression Analysis):通过建立一个回归模型来描述自变量与因变量之间的关系。回归模型基于线性假设,即自变量与因变量之间存在线性关系。模型的目标是找到最佳拟合的回归系数,使得模型能够最好地解释观察到的因变量的变异。
(5)描述性统计(Descriptive Statistics):通过计算中心趋势和变异程度,总结和描述数据的特征、模式和分布。它的目标是通过使用各种统计指标和图表来提供对数据集的定量和定性的描述,以便更好地理解和解释数据。
三、研究过程与结果
3.1利用t检验和描述性统计比较不同企业之间的高等教育程度差异
3.1.1描述性统计过程与求解
(1)收集数据:首先,需要收集相关的数据。数据可以通过实地观察、实验、调查问卷、文献研究等方式获取。
(2)数据清理:对收集到的数据进行清理和处理,包括检查数据的完整性、准确性和一致性。在这一步骤中,需要处理缺失值、异常值和错误数据。
(3)归一化处理:将原始数据线性地映射到一个指定的最小值和最大值之间的范围,通常是0到1之间。
(4)描述性统计指标计算:根据数据的性质和研究目的,计算各种描述性统计指标来总结和描述数据的特征。常见的描述性统计指标包括平均值、中位数、众数、方差、标准差、极差、百分位数等。
(5)数据可视化:使用图表和图形将数据可视化,以便更好地理解数据的分布和关系。常见的数据可视化方法包括直方图、箱线图、散点图、折线图、饼图等。
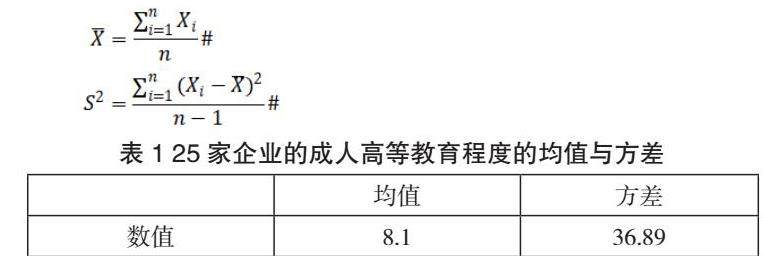
(6)计算样本均值和方差:对受高等教育比例、学历结构、员工继续教育情况、校企合作频率四个因子进行加权平均,得到一个新的指标来衡量不同公司总的成人高等教育程度,并依次计算均值与方差。
由表1可知,25家企业的成人高等教育程度相差较大。
3.1.2 t检验过程与求解
t检验通常用于比较两组样本均值之间的显著差异,而不是用于验证数据的可靠性。数据量的大小对t检验的适用性没有直接的影响。在数据统计领域,t检验和F检验是两种常用的假设检验方法,用于比较不同样本或处理之间的差异。它们具有一些区别和使用条件,同时也有一些共同点。
t检验用于比较两个样本均值之间的差异是否显著。它基于分布来计算统计量,考察样本均值之间的差异是否大于我们可以在随机误差范围内期望的差异。t检验有两种主要形式:独立样本t检验和配对样本F检验。
1)建立假设、确定检验水平α:
其中为零假设,代表25家企业的受高等教育程度没有差异。;为备择假设,代表25家企业的受高等教育程度存在差异。μ为总体均值,μ0为样本均值,检验水准取值为α=0.05。
2)计算检验统计量:
其中、分别为第一、第二组的样本方差,、分别为第一、第二组的样本容量。
3)将、代入,计算得
4)查相应界值表,判断是否具有显著性差异。
若,接受假设,无显著性差异;,拒绝假设,有显著性差异。。
所以,,说明25家企业的成人高等教育程度具有显著差异。
3.1.3小结
通过描述性统计和t检验的结果可知,25家企业之间的成人高等教育程度具有显著性差异。
3.2成人高等教育与企业绩效的相关性分析
3.2.1灰色关联分析
灰色关联分析(Grey Relational Analysis)是一种用于处理灰色系统的分析方法,用于研究多个变量之间的关联程度。它可以帮助我们找到不同变量之间的相对关联性,并识别出对预测变量最有影响的因素。灰色关联分析的基本思想是通过比较序列之间的灰色关联度来刻画它们之间的关联程度。它基于灰色系统理论,该理论是一种介于确定性和随机性之间的不确定系统,常用于处理数据样本量小、信息不完全或不确定的问题。
总的来说,灰色关联分析是一种简单而有效的多变量关联分析方法,通过比较序列之间的关联度来揭示变量之间的相互关系。它能够在数据不完全或不确定的情况下提供有用的分析结果,并为决策提供参考。
由于灰色关联度的计算不依赖于数据的全面性,即使数据存在缺失值或者样本量较小,也能够给出合理的关联度结果,同时综合多个影响因素进行关联度计算和排序,可从多个角度对问题进行评估,具体步骤如下:
(1)将原始数据进行归一化处理,将各个变量的取值范围统一到相同的区间,通常进行区间缩放或正态化处理。
其中,n为因素个数,m为每个因素的数据维度
(2)将标准化后的数据组成一个评价矩阵B,其中每一行表示一个变量,每一列表示一个观测值。
然后计算每个观测值与其他观测值之间的关联度,通常使用灰色关联度计算公式来计算灰色关联系数。
灰色关联系数的计算公式为:
其中,为比较数列对参考数列在第j个指标上的关联系数,为分辨系数,式中、分别为两级最小差及两级最大差
(3)从关联度矩阵中选择一个作为参考序列,用于与其他序列进行比较。通常选择具有更多信息、更具代表性或更感兴趣的序列作为参考序列。
这里,即参考数列相当于一个虚拟的最好评价对象的各指标值。
(4)使用灰色关联度计算公式,将参考序列与其他序列进行比较,计算它们之间的关联度。
灰色关联度的计算公式为
其中,为第j个指标xj的权重,ri为第i个评价对象对理想对象的灰色关联度。
(5) 根据计算得到的关联度值,对序列进行排序,确定它们与参考序列的关联程度。根据排序结果,可以进行进一步的分析和决策。
灰色关联分析在实践中具有广泛的应用,特别是在多变量分析和预测中。它可以用于确定多个变量之间的重要性和相互影响程度,帮助辨识出对目标变量具有最大影响的因素。
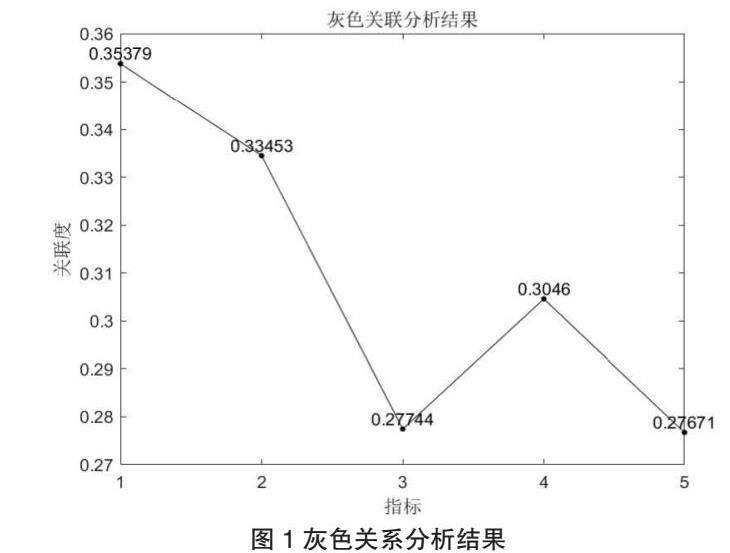
其中横坐标的序号1到5依次代表“高等教育比例”,“学历结构”,“继续教育情况”,“校企合作”,“绩效”。结果显示衡量高等教育程度的四个因子中与企业绩效的关联度从高到低的因子依次为“高等教育比例”,“校企合作频率”,“学历结构”,“继续教育情况”。
3.2.2小结
通过上文的分析与求解可以得知,“高等教育比例”和“校企合作频率”对企业用人单位的员工绩效影响相对较大。
3.3运用基于主成分分析的多元回归分析求解出绩效的量化关系
3.3.1主成分分析过程与求解
主成分分析(Principal Component Analysis,PCA)是一种常用的多元统计方法,用于降低数据维度并揭示数据中的主要变化模式。它是一种数据降维技术,可以减少数据集的维度并保留数据中的主要信息。通过选择适当的主成分数目,可以实现对数据的压缩和简化,并帮助减少变量之间的相关性。它在数据探索、可视化和预测建模等领域具有广泛的应用。
下面是主成分分析的建立步骤:
(1)数据准备:收集和整理需要进行主成分分析的数据集。确保数据集中的变量是数值型的,并且数据已经进行了标准化处理(均值为0,方差为1),以消除变量之间的量纲差异。
(2)协方差矩阵计算:计算数据集中各个变量之间的协方差矩阵。协方差矩阵描述了变量之间的线性关系。
(3)特征值与特征向量计算:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征值表示主成分的方差解释程度,特征向量表示主成分的方向。
(4)特征值排序:将特征值按照从大到小的顺序进行排序。特征值较大的特征向量对应的主成分解释了数据中较多的方差。
(5)主成分选择:根据特征值排序结果,选择解释方差较高的前k个主成分作为新的变量集。一般选择的主成分个数k可以通过设定解释方差的阈值或者根据经验来确定。
(6)主成分计算:将原始数据集投影到选取的主成分上,得到降维后的数据集。这可以通过将数据点与所选主成分的特征向量相乘来实现。
(6)解释方差分析:计算每个主成分所解释的方差比例,以评估主成分的贡献程度。通常,可以通过累计解释方差比例来确定选择的主成分个数。
(7)结果解释:根据主成分的特征向量和解释方差比例,解释主成分所代表的特征和变量之间的关系。这有助于理解主成分的含义和数据的结构。
通过对主成分分析法的计算,决定选取“高等教育比例”,“校企合作频率”以及“学历结构”三个自变量作为预测员工绩效自变量的因子。
3.3.2基于主成分分析的多元回归方程的建立与求解
(1)数据收集和准备:收集与研究问题相关的数据,并进行数据清洗和预处理。确保数据的完整性、准确性,并处理缺失值或异常值。
(2)确定因变量和自变量:“高等教育比例”,“校企合作频率”以及“学历结构”作为自变量,选取企业用人单位员工绩效作为因变量。
(3)建立模型假设:根据研究问题和数据特点,确定多元回归模型的假设。这包括线性关系假设、变量间独立性假设、残差的正态性假设等。
(4)模型拟合:使用统计软件,将多元回归模型应用于数据集,拟合模型并估计模型的系数。这可以通过最小二乘法等方法来实现。
(5)模型评估:评估多元回归模型的拟合优度和统计显著性。常用的评估指标包括决定系数(R²)、调整决定系数(Adjusted R²)、F统计量、残差分析等。
(6)变量选择和解释:根据统计显著性、变量相关性和实际意义,选择对因变量有显著解释能力的自变量,并解释它们与因变量的关系。可以使用变量的系数、假设检验和置信区间等来解释自变量的影响。
(7)模型诊断:对多元回归模型进行诊断,检查模型是否满足前提假设和模型的合理性。常见的诊断方法包括异常值检测、多重共线性检验、残差分析和影响度量等。
(8)模型应用和预测:使用已建立的多元回归模型进行预测和推断。可以通过输入新的自变量值来预测因变量的值,并进行置信区间估计或假设检验。
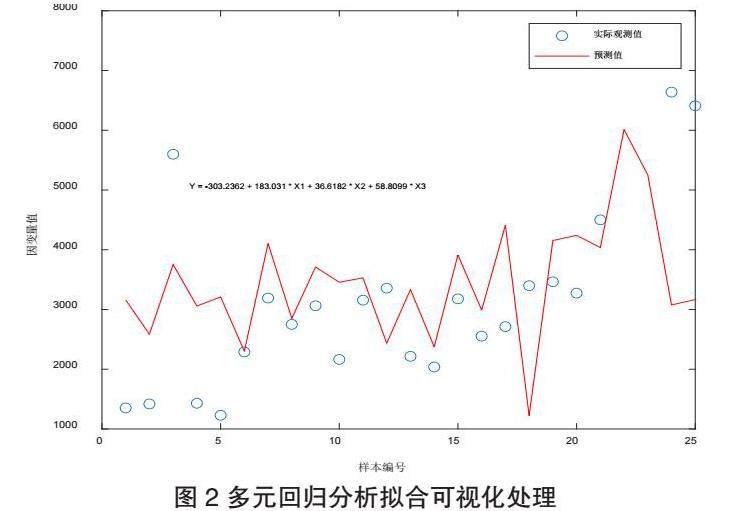
X1,X2,X3依次代表“高等教育比例”,“校企合作频率”以及“学历结构”,Y代表企业用人单位员工绩效,拟合后的多元回归方程为:
3.3.3小结
通过主成分分析,得知在多个自变量中 “高等教育比例”,“校企合作频率”以及“学历结构”三个自变量对企业用人单位员工的绩效影响最大。再通过多元回归分析求解出了自变量与因变量(绩效)的多元回归关系,实现了量化处理。
四、总结
本研究旨在探讨成人高等教育对企业用人单位员工绩效的影响。通过对25家具有代表性的中型企业进行问卷调查和访谈,研究采用了多种统计分析方法,包括t检验、灰色关联分析、主成分分析和多元回归分析。
研究结果表明,25家企业之间的成人高等教育程度具有显著性差异;“高等教育比例”和“校企合作频率”对企业用人单位的员工绩效影响相对较大;在衡量成人高等教育的多个指标中,“高等教育比例”,“校企合作频率”以及“学历结构”三个自变量对绩效影响较大,并量化求解出了自变量与因变量之间的多元回归方程。
参考文献:
[1]曲广雷,闫宗伟,郑木莲等.基于神经网络与回归分析的多孔混凝土性能预测[J/OL].吉林大学学报(工学版):1-13[2023-09-23].
[2]施海娜,刘哲,梁万鹏等.庆阳驴体尺指标的相关性、聚类和主成分分析[J].中国草食动物科学,2023,43(05):29-35.
[3]韩岳麒,李亚娟,王丽平.工作幸福感与员工创新绩效的关系研究[J].云南财经大学学报,2023,39(09):98-110.
1.姓名:曾少芳,性别:女,民族:汉 出生年月:1979年01月,广州市从化区人,本科,研究方向:教育管理,单位:广州城建职业学院
2.姓名:谭飞,性别:男,民族:汉 出生年月:1996年04月,湖南省邵阳人,本科,研究方向:车辆工程,单位:广州城建职业学院
3.姓名:邓炬洪,性别:男,民族:汉 出生年月:1993年02月,广州市从化区人,硕士研究生,研究方向:企业管理与发展,单位:广州城建职业学院

 京公网安备 11011302003690号
京公网安备 11011302003690号


