



- 收藏
- 加入书签

基于深度学习模型的图像分辨率提升方法研究
 打开文本图片集
打开文本图片集



摘要:随着近年来信息技术的不断发展,当前的数据传输能力得到了飞速的提高。图像是现阶段常见的信息传递方式,超过一般的信息传递都以图像的形式开展。图像的质量受成像设备的影响较大,低质量的成像设备会限制图像的分辨率,因此再加上网络宽带中图像格式等因素影响下,高分辨率受到一定的限制条件在传输过程中需要降低图像的分辨率。为了有效满足当前社会发展对图像分辨率的要求,推动各行各业的进步以及人们生活水平的提高,本文研究了基于深度学习的DCT上采样方式,并借助网络传输和空间域的处理,有效克服传统DCT上采样中去相关性的特点,利用后处理卷积网络重构图像。对于本文提出的深度学习方法,利用峰值信噪比和结构相似度等两种方式表明在同等参数量级上进行对此测试,可以发现本文提出的DCT域深度学习方法具有较高的实用性,能有效提高图像的分辨率,进而达到良好的视觉效果。
关键词:深度学习;图像分辨率;提升策略
引言:
图像的分辨率往往会受到成像设备的影响,采用优化成像设备的方式提高图像分辨率的方式,往往需要浪费大量的资金在设备更新和改装等方面,并不具经济性。图像分辨率的提升原理是对分辨率较低的图像进行细节方面的补充和重建,进而提高图像的分辨率,因此也可以利用成本相对较低的算法或模型等方式对图像的分辨率进行补充,进而成功给降低技术使用的成本。近年来随着社会经济的不断发展,提高图像的分辨率在各行各业的应用场景也越来越广泛,例如医学图像、城市测绘、工程建设、汽车领域、卫星遥感等。在此背景下,研究图像的分辨率提升技术对推动社会生产,提高人们生活质量有着极其重要的意义。
有关提升图像分辨率的技术最早的研究是Harris等(1964)提出的频谱外推法概念,此后关于图像分辨率的提升技术受到国内外学者的广泛研究[1]。频谱外推法所需要的全局平移模型在实际的使用过程中,由于实现的条件过于严格而不能得到广泛推广。Tsai和Huang(1984)正式提出了提升图像分辨率的概念,利用算法对图像中低分辨率部分进行填补,进而提升图像的分辨率[2]。在后期的发展中,关于利用算法提高图像分辨率的研究逐渐形成三个主要方向即利用插值、重建、学习等方式进行分辨率的提升。本文重点研究基于学习的图像分辨率提升方法,主要通过大量的训练样本利用一定算法学习图像的低分辨率和高分辨率之间的映射添加,随后将训练出的映射函数应用在低分辨力的图像中,以此填补低分辨率图像的细节,提升图像的分辨率。关于基于学习的图像分辨率提升方式,Freeman(2002)等提出了利用马尔科夫随机场训练低分辨率图像和高分辨率图像的映射函数[3]。Chang(2004)等提出采用邻域嵌入算法利用原图中相似部分的特征补充低分辨率图像的分辨率[4]。
Yang(2008)等提出利用深度学习的稀疏表示的算法综合分析低分辨率和高分辨率图像块的信息库,提升图像的分辨率。深度学习主要是指模仿人脑学习的方式,结合神经网络对数据库样本的规律和特征等进行学习,以此形成具有相关学习和计算能力的算法,在一定程度上能取代人工思考和分析的流程,提高相关研究和工作的效率[5]。深度学习和神经网络特征提取之间最大的区别是深度学习能获取更多更精确的学习信息。将其应用在图像分辨率的提升方面,深度学习能通过大量的样本训练获取图像最根本的特征,并以此作为预测的依据。
尽管基于深度学习的图像分辨率提升策略具有较高的应用优势,但在实际使用中依旧存在一定的缺陷,例如算法的计算流程复杂、分辨率的提升质量和计算能力之间存在较大的关联性、随着计算参数的不断增加,分辨力提升时计算的时间也不断增加,降低了深度学习图像分辨率提升当时的实用性和实时性。因此克服深度学习计算模型中计算参数的问题,成为当前深度学习技术的重要突破方向。
基于此本文提出了离散余弦变换(DiscreteCosineTransform,DCT)的方式,以提高参数的压缩率。利用DCT对图像进行采样,结合深度学习的方式对低分辨率的图样进行分步采样,进而提升图像的分辨率。通过实验可以证明,本文研究的DCT深度学习技术不仅具有良好的计算性能,还具备准确的分辨率提升技术。
1基于DCT深度学习技术的图像分辨率提升算法设计
1.1算法流程
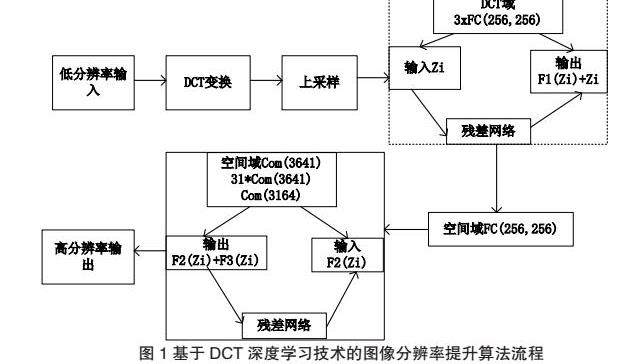
基于DCT深度学习技术的图像分辨率提升算法需要利用三维深度对需要补充的低分辨率细节进行计算和分析,随后对其进行重建。这一计算方式主要涉及以下环节:DCT域的残差全连接,主要用于处理DCT域流程和空间域流程之间的转换,以及对空间域的卷积网络进行后处理。此过程需要将图像转化为DCT相关的系数,按照算法流程将其输入。具体为首先利用DCT域的残差与整个网络相连,对高分辨率的系数进行计算,完成计算后输入相关的结果。再利用DCT域和空间域之间的转换网络蒋计算后的结果转化到空间域中,通过空间与域对残差卷积进行处理,进一步提升图像的分辨率,最后输出成功提高分辨率后的优质图像(如图1)。
在此流程中,代表低分辨率图像利用DCT变换生成的图片系数;代表DCT域中的残差网络全输出;代表进行DCT域转换至空间域时,通过转换流程输出的空间域图像,则代表对图片进行高分辨率优化处理后的残差网络输出结果。
1.2 DCT域的残差网络
在利用卷积网络对图像特征进行提取和监督学习训练之前,首先需要在DCT域中对空间域所需要的高频系数进行估算。在这一阶段,DCT域的残差全连接网络将需要处理的低分辨率图像以DCT系数的形式输入至DCT域的残差网络中,随后通过深度学习得到DCT域高频系数和低频系数之间存在的映射关系,借助映射关系估计所需要的DCT高频系数,最后估算出高分辨率结果(如图2)。
1.3 DCT域与空间域的网络转换流程
DCT域与空间域之间的转换同样需要一定的流程,实现将DCT域内的估算出的残差网络高分辨系数转换至空间域中。本研究利用全连接层进行转换:
全连接层转换网络能将DCT域的残差全连接网络中估算出的高分辨率系数转化至空间域,以便后期空间域对其进行处理,提升图像的分辨率。
1.4空间域深度学习和处理
要想利用本文研究的算法实现图像分辨率的提升,还需要利用空间域对输出的图像系数进行处理。采用的图像后处理方式为卷积网络后处理(CNN)。
卷积网络后处理实现对复杂的图像特征进行学习和重建。卷积神经网络的结构主要有输入层、卷积层、池化层、全连接层以及输出层。其中卷积层中主要通过对人类视觉的特征进行模拟以提取影响的特征;池化层对图像进行尺度化处理,进而保证在一系列平移、旋转等过程中重要尺度特征不变;全连接层主要通过对卷积层和池化层中的数据进行整合,形成对图像像素的提升。
在本文研究中,为了提高各个梯度在网络中的传播能力,采用了密集连接技术拓宽了梯度的传播路径。除此之外,采用密集连接技术还能降低梯度出现爆炸和消失等出现的可能性,增强网络收敛的速度。在密集连接技术中,卷积层之间存在着较大的联系性:
2 实验验证
2.1 研究区概况及数据来源
为了验证本文研究的图像像素提升技术的适用性,进一步开展了对比试验。基于深度学习的图像分辨率提升方法在多个行业领域中得到广泛的应用,结合某地区城市化进程不断加快,需要对地区的城市地貌进行重新采集,进一步对图像的清晰度进行优化,提高道路、广场、居民地、植被、江河等流域等图像数据的准确和清晰度。首先利用高分二号卫星遥感影像作为实验的重要数据,在高分二号卫星中装置2台1m的全色波段和4m的多光谱相机,使高分二号卫星遥感能具备亚米级的空间分辨率,高定位精度以及快速姿态机动能力等方面的特点。随后对影像进行预处理,克服遥感影像中的相关干扰信息如辐射定标、大气校正等,并利用高分二号卫星中自带的有理函数模型以sem数据对其进行校正,尽可能保证图像的光谱和纹理特性[6]。
随后整理不同的影像共计9820张,将其进行转化,成为320*240的灰度分辨率图像,以此作为训练的材料。利用Caffe作为相关的训练平台,采取MATLAB编写代码测试网络的性能,保证深度学习训练的效果。将本文提出的算法与当前常规应用的线性插值、补零法、补叠补零法、混合维纳滤波器、自适应k-NN算法、ANR-DCT算法等进行对比。最后对图像质量的评估主要采用PSNR与SSIM两项指标。训练网络的参数,训练图像主要为16*16的大图像块,随后将其分割为8*8的DCT块。训练时首先对16*16图像块转化为DCT系数,随后将系数输入到网络中。随后将全连接的网络输出作为网络输入的系数,用以训练DCT域和空间域的转换网络。最后,采用32*32的图像块作为空间域中卷积网络的输入。
2.2对比实验
将本文提出的算法和线性插值、非零法、补叠补零法、混合维纳滤波器、自适应k-NN算法、ANR-DCT算法等进行对比,采用的图像质量评估方式为PSNR与SSNM作为评估的指标,分别利用本文研究的方法和现有的方法对测试集进行分析。
通过对表格进行分析,可以看出本文研究的DCT深度学习算法在PSNR与SSIM两种训练方式上都具有较好的优势。通过对结果的分析可以发现基于DCT深度学习的算法在PSNR以及SSIM两种测试方式下都能起到良好的图像像素提升效果。根据实验结果进行分析可以发现本文研究的方法能更为高效地完成采样任务,并且在重建过程中能有效提高图像的分辨率,在图像领域中具有较好的应用效果[7]。
3 结束语
传统的DCT域上采样算法尽管运行的时间以及运行的速度较快,但在实际应用中对不同图像之间的相关性缺乏科学的认知,因此并不能达到预期的图像像素提升效果。结合基于学习的DCT域上采样方法利用字典学习的方式,本文将神经网络应用于基于学习的 DCT域上采样方法中,能有效提高网络深度学习的效率,达到良好的图像重建和像素提升效果。通过将本文提出的像素提升方式和已有的基于深度学习的分辨率提升方式进行对比,可以发现本文研究的DCT域残差网络深度学习方式具有较高的实用性。
参考文献
[1]Harris J.L. Diffraction and resolving power . Journal of the Optical Society of America.1964,54(7):931-936.
[2]Huang T. Multi-frame image restoration and registration J. Advances in computer visionand Image Processing.19841(7):317-319
[3]Baker S, Kanade T. Limits on super-resolution and how to break them J. IEEE Transactionson Pattern Analysis and Machine Intelligence,2002,24(9): 1167-1183.
[4]FreemWT,JonesTR,PasztorEC.Exampled-basedsuper-resolution[J].IEEEComputergraphicsandApplications.2002,22(2):56-65.
[5]Chang H, Yeung D.Y Xiong Y Super-resolution through neighbor embedding [C]. IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). 2004.
[6]Yang J, Wright J, Huang T, et al. Image super-resolution as sparse representation of rawimage patches CJ. IEEE Conference on Computer Vision and Pattern Recognition (CVPR).2008.
[7]叶利华,王磊,张文文等.高分辨率光学遥感场景分类的深度度量学习方法[J].测绘学报,2019,48(06):698-707.

 京公网安备 11011302003690号
京公网安备 11011302003690号


