



- 收藏
- 加入书签

基于数据融合和近红外光谱技术对芥菜品种的CARS-SPA-MLR模型研究
 打开文本图片集
打开文本图片集
摘要:为了探索可见近红外光谱技术(VIS-NIRS)对于鉴别芥菜品种的可行性,提出一种利用计算机数据处理技术及VIS-NIRS对芥菜品种快速无损检测识别的方法。(1)采用近红外光谱仪对三种品种的芥菜样本进行光谱采集,提取325nm-1075nm的光谱反射率。(2)利用标准正态变量(Standard normal variate,SNV)、多元散射校正(Multiplicative scatter correction, MSC)、卷积平滑(Savitzky Golay,SG)等算法对一些反射率不在记录点位置的光谱数据进行校正以及对散射较严重的变量进行剔除,同时也进行除噪、平移等处理。为证实不同品种的芥菜种子具有较大的差异性,利用主成分分析(PCA)对样本进行聚类分析,并采用竞争自适应重加权抽样算法(competitive adaptive reweighted sampling,CARS)和连续投影算法(successive projections algorithm,SPA)提取出9个最优特征波长。(3)对CARS-SPA挑选出的最优特征波长作为建模输入,建立多元线性回归(MLR)、偏最小二乘回归(PLSR)、支持向量机(SVM)等模型。(4)结果表明,从PCA聚类图中可以看出,前两个主成分就能够对芥菜的品种得到很好的聚类作用。而基于特征波长的CARS-SPA-MLR模型和MSC-PLSR模型对芥菜种子的品种辨别率要优于基于全波段PLSR建模和另外两种预处理后的建模结果。其中基于CARS-SPA-MLR模型的效果最优,并从校正集和预测集结果可以看出,其对芥菜品种的辨别率均达到了99.5%。因此,基于近红外光谱技术对于芥菜品种的鉴别是可行的,从而为芥菜种子快速无损检测的设备研发提供了方法与理论基础。
关键词:可见近红外光谱;芥菜;连续投影算法;偏最小二乘回归;多元线性回归
Abstract: In order to explore the feasibility of VIS-NIRS in identifying Chinese mustard varieties, a method of rapid nondestructive testing and identifying Chinese mustard varieties using computer data processing technology and VIS-NIRS was proposed. (1)Near-infrared spectroscopy was used to collect the spectra of three varieties of Chinese mustard, and the spectral reflectance of 325nm - 1075nm was extracted. (2)Standard normal variate(SNV), multiplicative scatter correction(MSC), Savitzky Golay(SG) and other algorithms were used to correct some spectral data whose reflectivity was not at the recorded point, eliminate the variables with severe scattering, and perform noise elimination, translation and other processing. In order to prove that Chinese mustard seeds of different varieties have great differences, the principal component analysis(PCA) was used to conduct cluster analysis on the samples, and competitive adaptive reweighted sampling(CARS) and successive projections algorithm(SPA) were used to extract nine optimal characteristic wavelengths. (3)The optimal characteristic wavelengths selected by CARS-SPA was used as input in modeling to establish models, including multiple linear regression(MLR), partial least squares regression(PLSR), support vector machine(SVM). (4)The results showed that, from the PCA clusters, the first two principal components were good enough for cluster analysis on Chinese mustard varieties. Moreover, CARS-SPA-MLR models and MSC-PLSR models based on characteristic wavelength can better distinguish varieties of Chinese mustard seeds than those based on full-band PLSR modeling and the other two results of modeling after pre-processing. Between the two models mentioned above, MSC-PLSR models had the best effect. In addition, from the results of the calibration set and prediction set, their recognition rate for Chinese mustard varieties all reached 99.9%. Therefore, it is feasible to use near-infrared spectroscopy to identify Chinese mustard varieties, thus providing a method and theoretical basis for the research and development of equipment for rapid nondestructive testing of Chinese mustard seeds.
Keywords: visible near-infrared spectroscopy; Chinese mustard; successive projections algorithm; partial least squares regression; multiple linear regression
1 引言
现如今,人们对蔬菜品质的要求日益增加,选择营养丰富的蔬菜就尤为重要,芥菜中含有丰富的维生素和矿物质元素,同时含有大量的蔬菜纤维,满足人们对高品质蔬菜的需求。但是不同品种的芥菜种子的质量和发芽率都有较大的差别,而目前市场上检测芥菜种子的方法有传统法和现代技术检测,但都不能做到实时、便捷、低成本的特性要求,故在实际应用中受到了一定的限制。
光谱技术是目前在农作物以及食品检测中能够做到分析速度快、测量精度高、低成本无损耗的检测技术[1],近年来被研究者广泛应用,其与计算机数据处理技术结合已经再某些品种检测中得到了应用。Song等[2]人对草莓品质的快速检测进行了研究;Hu、Zhang等[3, 4]人应用近红外漫反射光谱法对猕猴桃品质进行识别;Li等[5]利用近红外光谱对稻谷千粒质量进行无损检测。其次还有在辣椒[6]、番茄[7]、黄瓜[8]、玉米[9, 10]等邻域的研究。但目前在芥菜品种检测中利用近红外光谱技术的研究几乎没有,芥菜种子中有机物丰富,而有机物中含有氢基团,近红外光谱对其吸收效果明显。因此,芥菜种子在采集过程中的光谱特性反射率存在明显差异,利用NIR技术来辨别芥菜种子的品种是有探索可行性的。
本研究为弥补现有研究现状的欠缺及NIR在芥菜品种辨别中的合理性,以三种品种的芥菜为研究对象,采集样本的近红外光谱信息,对其采集图像进行数据提取,结合计算机数据处理技术进行光谱分析,建立建立多元线性回归(MLR)、偏最小二乘回归(PLSR)、支持向量机(SVM)模型评价,提出了一种快速无损的芥菜品种检测方法。
2 材料与方法
2.1 样品制备
芥菜样本:购自南昌(江西省)当地种子市场。样本于2小时内送至实验室,然后对所购样本进行分类标记,共分成3类,每类分别挑选30颗(共90颗)作为样本,所有样品在实验室环境温度为22摄氏度,相对湿度为60%的实验室条件下放置24小时,为进一步的实验做准备。
2.2 光谱数据采集
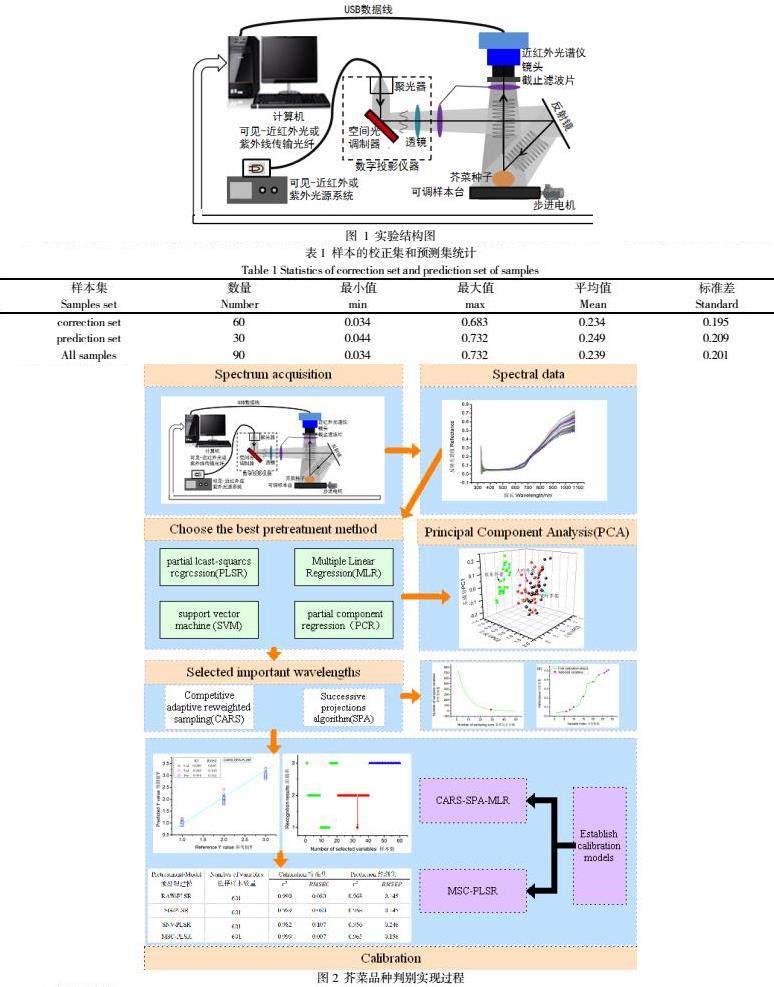
光谱采集设备主要包括近红外光谱仪、移动平台、光源(卤素灯、或者LED光源)和计算机等几个组成部分。通过计算机控制步进电机转动来控制移动平台的移动,本研究通过不断的改变采集设备参数,进而选择最优的数值设置:调焦镜头距测量种子25CM,种子光照时间20ms,电机转动速率0.2mm/s。其结构图如图1所示。
全部样本按2:1的比例随机分成两部分进行校正和预测,其中60粒作为校正集,剩下的30粒作为预测集。为了使采集的样本数据更加精确,每个样品扫描3次,将3次采集数据的平均值作为最终光谱数据。表1为数据采集统计结果。
2.3 实验过程
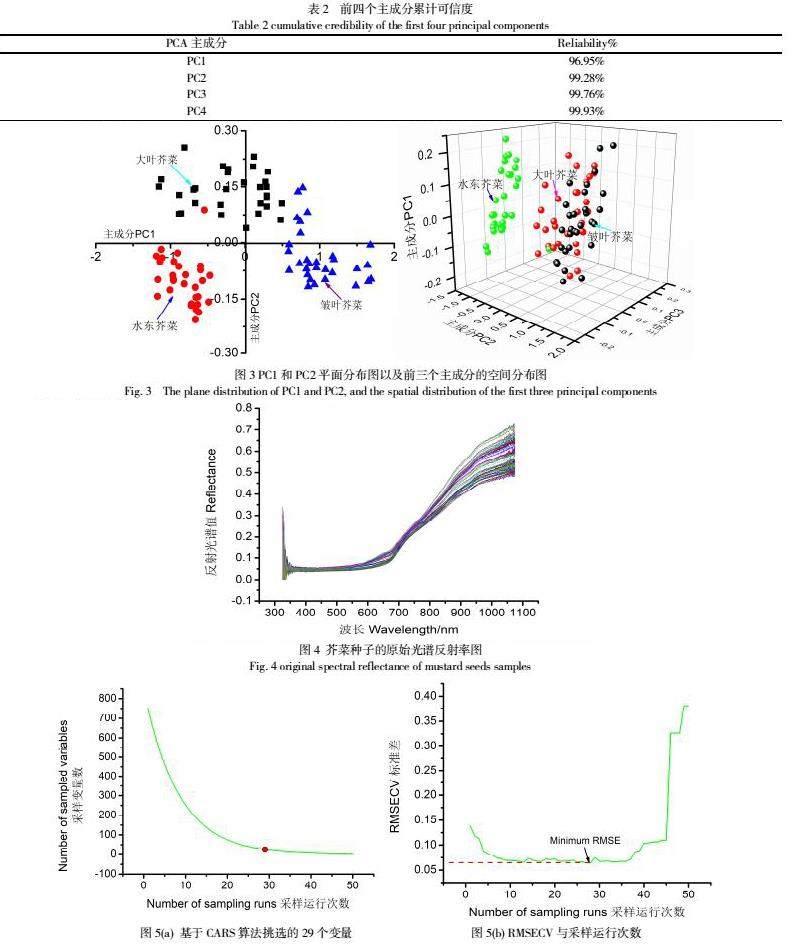
本研究基于可见近红外光谱技术提取不同品种芥菜种子光谱特征,利用三种预处理方法对光谱数据进行处理后建模,且通过CARS与SPA算法提取的特征波长,建立PLSR、MLR、SVM等数据模型。利用校正集和预测集寻求相关数值,然后对芥菜品种进行比较判断分类。具体实验方法思路如图2所示。
2.4数据预处理
由于在芥菜光谱数据提取过程中存在很多不确定的干扰因素,为了获取更有效的光谱数据信息,通常需要在建模前对光谱数据采用一定的预处理来消除光谱信息中的高频电子噪声、特异性散射、谱线平移等干扰的影响[11, 12]。标准正常变量(SNV)通过对单个变量的频谱进行集中处理和缩放,实现了处理原始频谱的目的。它可以消除散射效应,降低多点线性、转换和曲率。乘法散射校正(MSC)利用平均光谱进行回归运算可以消除原始光谱的散射效应。卷积平滑(Savitzky Golay,SG)处理可以使数据流平滑去噪,可以使原始数据更好拟合。
通过上述不同的方法进行数据预处理,在保留了原有光谱信息完整性的同时减小了后期建模所带来的误差影响。
2.5 有效特征变量的选择
由于近红外光谱特征吸收区域不明确,为了得到芥菜种子的有效数据信息,本实验一共获取了751个特征波长,但获取的光谱信息中含有大量重复和连锁关系的信息特征,对光谱信息的有效性带来了很大的影响,且基数过大的光谱数据也不利于后期的运算和建模,故通过CARS和SPA算法来选择最优的特征波长。
竞争自适应重加权抽样算法(competitive adaptive reweighted sampling,CARS)是一种对无信息和权重较小的波长点进行有效去除的同时,选择出RMSECV值最低、信息量较多的变量,最终则优提取出所需信息最为重要的变量,但CARS的缺点是它之后还保留了许多变量[13-15]。
连续投影算法(successive projections algorithm,SPA)可以消除变量中重复的光谱信息,在全波段光谱信息中找出连锁关系最小的特征波长[16, 17]。同时也能很大程度上降低用于建模所需的变量个数,进而达到模型的优化,但SPA选择的特征波长在样本数较少时代表性不强,这将使建模预测能力结果不理想。
为了结合两种算法的优点,本研究采用竞争自适应重加权抽样算法结合连续投影算法来选取最优特征波长点,该算法在MatlabR2010a中实现。
2.6 模型的建立
2.6.1 主成分分析
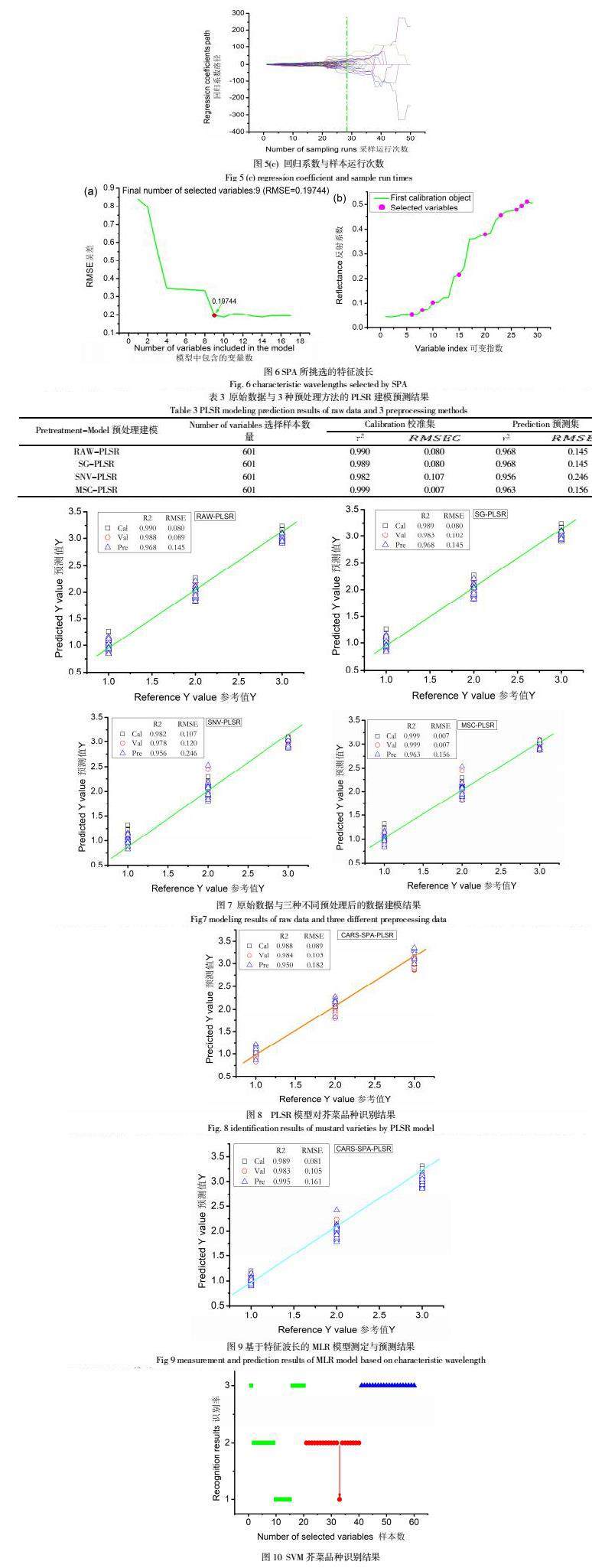
主成分分析(Principal Component Analysis,PCA)作用之一是作为一种特征重建,常用于大数据集的降维和聚类[18-20],它可以把一个大数据变量集转化为几个包含了大部分有效信息的变量集,去除了大量的无关变量,更易于数据分析的快速性和容易性,以提高分类能力[21]。本实验在The Unscrambler X 10.1中对原始光谱数据进行聚类分析,得到前四个主成分对光谱信息的累计和百分比如表2所示。从表中可以看出PC1包含了原始数据的主要有效信息,PC2中包含了剩余的大部分信息,以此类推累计。
由于前两个主成分已经累计占了全部信息量的99.28%,故只用PC1和PC2对90个芥菜种子样本进行分类。图3所示的是主成分一和主成分二数值下的种子平面分布图以及前三个主成分的空间分布图,从图中可以看出,3种不同品种的芥菜种子被明显的分为三类,其中水东芥菜的聚类和分布效果最好,在平面图中只有一个样本没有聚集在同一现象。而大叶芥菜和皱叶芥菜两个品种也均匀的分布在两个象限内。从以上结果可以看出前两个主成分对芥菜种子有很好的聚类作用,从而可以得到三种不同品种芥菜种子的特征差异,以达到区分的作用。但三种不同品种的芥菜相邻部分少数样本出现重叠现象,为了达到完全区分,实现最优的检测效果,还需要对样本数据进一步的处理。
2.6.2 PLSR建模
偏最小二乘回归(PLSR)建模是将高度相关共线性的变量线性组合,在数据建模时只需要更少的成分来融合因变量。尤其是当不同样本数据集合存在较高相关性时,此时用PLSR进行建模分析最为可靠[22, 23]。
2.3.3 MLR建模
而多元线性回归(MLR)是分析通过一个以上自变量(X)之间的线性组合来反映一个因变量(Y)关系的建模方法,适用于波长数小于样本数的建模分析[22, 24]。
2.3.3 SVM建模
支持向量机SVM是在一个空间平面中,把样本数据通过标准算法函数反映在两个最大间隔边距的超平面中,增强了其稳定性。从而对一些量大的数据具有更好的分类和识别作用[25-27]。
本实验通过以上三种方法建立不同的数据模型,通过对比选择出最优的建模方式。
3 结果与分析
3.1 芥菜种子的原始光谱曲线
本研究采取了芥菜种子325-1075nm波长范围内的751个近红外光谱数据,其光谱曲线图如图4所示。
从图4中可以看出,在光谱图的前后端都有较严重的噪声干扰,为了减少对后面建模的影响,去除前后端明显干扰的波段,采用波长为400-1000nm波段共601个光谱数据进行建模分析。同时,可以看出3个不同品种的芥菜种子的光谱图之间趋势大致一样,没有明显的特征差异。
3.2 CARS算法挑选特征波长
在MatlabR2010a中,把原始光谱作为输入,通过CARS算法中的标准差选择出29个最有效的特征波长。其变化曲线如图5(a、b、c)所示。
从图5(a)中可以看出采样运行次数和选择变量数之间的关系,在开始阶段,选择的变量数快速下降,这是由于开始变量基数大,低效信息量的数据快速被剔除,通过不断的选择剔除,渐渐变得相对稳定;在图5(b)中RMSECV值随着采样运行次数的增加开始缓慢降低,随后又开始增加,降低是因为无效变量的剔除,而后面RMSECV增加则是因为变量数过少时,有效变量也被一起滤除了。图5(c)表示了在不同采样运行次数下所反映出不同波段线的回归系数。因此,为了得到最小的RMSECV,本实验选择的29个波长。分别是59nm、71nm、86nm、170nm、171nm.......
3.3 SPA算法挑选波长
由于CARS算法挑选后还保留了许多变量,为了使模型更加简化,把CARS选择出来的29个变量当作SPA的输入来进一步获取更为重要的特征波长,把均方根误差的高低作为挑选的依据,其变化曲线如图6(a-b-c)所示。
由图6(a)可知,随着RMSE从开始的急剧减小到最后趋于平稳,最终在RMSE=0.19744处选择了9个最优变量数用于建模。而图6(b)则表示的是选择出来的9个特征波长在29个输入中所对应的变量索引位置。
3.3 PLSR建模分析
在PLS建模中,将去除首末端干扰变量的601个光谱数据作为建模输入变量X,三种不同品种的芥菜种子类型作为输出变量Y来建立模型。为了使预测模型的准确率最高,本研究基于三种不同的预处理方法对其原始数据进行处理后建立模型与原始数据的PLSR模型进行比较,其建模结果如表3所示。
从表3中我们可以看出,采用中值滤波平滑法处理后所得模型比原始光谱数据建模效果提高的不是很明显,这是因为在预处理之前原始数据就已经去除了首尾较多的噪声干扰,而滤波法的主要作用就是去除高频噪声,所以处理结果没有提高。而SNV处理后的建模结果与未处理数据结果相比较反而降低了,这是因为SNV主要用来降低样本形状及表面不均匀所带来的非特异性散射影响[9],同时在处理时把某些信息量高的样本数据滤除了。其中,多元散射校正MSC-PLSR预测结果最优,不但提高了确定系数,还降低了均方根误差。
如上图7所示,我们可以看出,在以上四幅结果图中,所有的校准均方根确定系数都达到的0.98以上,其中MSC-PLSR模型的校准集的确定系数(RC2)的值为0.9998且交叉验证集的确定系数(RP2)值也达到了0.9998,而校准均方根误差(RMSEC)值仅有0.0070,以及验证均方根误差(RMSEP)值0.0074。一般来说,一个好的模型应该有较高的RC,RP,较低的RMSEC和RMSEP。
3.4 CARS-SPA-PLSR模型
在PLSR模型中,采用交叉验证法,设置权重系数为1,对所提取的特征波长作为建模输入,其模型对芥菜品种辨别率结果如下图8所示。
从图8中可以看出,在CARS-SPA-PLSR模型中,只有个别的样本识别出现了错误,其校正集和预测集识别率分别为98.8%和95%,平均识别率达到了97%。
3.4 CARS-SPA-MLR模型
在MLR模型中,对于样本数较少的数据尤为适用,从图9中我们可以看出,CARS-SPA不仅大大简化了模型,而且还有很好的预测结果,其中校准集的确定系数和预测集的识别率都能达到98%以上,均方根误差值都在0.1左右。此外,较少的波长更方便实际应用,因为可以节省模型的训练和预测时间。
3.5 CARS-SPA-SVM模型
在SVM模型建立中,采用Unscrambler X 10.1自带的程序函数,权重设置为1的交叉验证,找出最优的2 两个参数,从而使模型最优化。 SVM模型对芥菜品种识别结果如图10所示。
由图10可知,类别为1的品种出现了许多的识别错误,而品种2和3都得到了很好的识别效果,仅有一个样本识别错误。但由于1号品种的识别率低,导致整体的校正集和预测集的平均识别率只有70.5%。
4 结论
(1)在芥菜品种识别模型中,通过SG、SNV、MSC预处理后建立的PLSR模型中,所有模型的校正集识别率都达到了98%。其中基于MSC-PLSR模型和RAW-PLSR模型的识别率达均到了99%。而对于CAPS-SPA提取最优特征波长所建立的PLSR、MLR、SVM模型中,PLSR模型的平均识别率达到了97.4%,MLR模型的平均识别率达到了99.2%,而SVM模型的平均识别率仅有70.5%。
(2)总体来说,基于MSC-PLSR模型和CARS-SPA-MLR模型的效果最优,但通过CARS-SPA提取特征波长后所建立的MLR模型可以很大程度上节省模型的训练和预测时间,简化了模型。
(3)以上结果表明,利用可见近红外光谱鉴别芥菜种子品种可行的,本研究为芥菜品种的快速无损检测分类鉴别提供了切实可行的方法。其研究结果也为基于可见近红外光谱快速无损检测芥菜品种的设备研发提供了理论基础。
(4)往后的研究可从以下几点出发:1.建立更多的预测模型,优化模型预测效果;2.本研究将芥菜作为研究对象,后续可以采用白菜等其他菜品作为研究对象;3.可以考虑研发便携式蔬菜品种检测仪器。
参考文献
[1] 王冬, 王坤, 吴静珠, 等. 基于光谱及成像技术的种子品质无损速测研究进展[J]. 光谱学与光谱分析, 2021,41(01): 52-59.
[2] 宋雪健, 王洪江, 钱丽丽, 等. 基于近红外光谱技术对草莓品质的快速检测研究[J]. 黑龙江八一农垦大学学报, 2020,32(03): 35-43.
[3] 胡晓峰, 林敏, 刘辉军, 等. 应用近红外漫反射光谱法的猕猴桃品质无损检测[J]. 理化检验(化学分册), 2018,54(01): 8-12.
[4] WEN Z, AICHEN W, ZHENZHEN L, et al. Nondestructive measurement of kiwifruit firmness, soluble solid content (SSC), titratable acidity (TA), and sensory quality by vibration spectrum[J]. Food Science & Nutrition, 2020,8(2).
[5] 王新忠, 卢青, 张晓东, 等. 基于高光谱图像的黄瓜种子活力无损检测[J]. 江苏农业学报, 2019,35(05): 1197-1202.
[6] 李翠玲, 姜凯, 马伟, 等. 基于荧光光谱的辣椒种子品种识别[J]. 蔬菜, 2020(09): 9-13.
[7] 彭彦昆, 赵芳, 李龙, 等. 利用近红外光谱与PCA-SVM识别热损伤番茄种子[J]. 农业工程学报, 2018,34(05): 159-165.
[8] 於海明, 李石, 吴威, 等. 稻谷千粒质量近红外光谱预测模型的波长选择方法[J]. 农业机械学报, 2015,46(11): 275-279.
[9] LI H, WU J, LIU C, et al. Study on Pretreatment Methods of Terahertz Time Domain Spectral Image for Maize Seeds[J]. IFAC PapersOnLine, 2018,51(17).
[10] JIAN Z, JI M H, XI C, et al. A Preprocessing Algorithm of Corn Infrared Spectrum Based on MSC and DOSC[J]. Advanced Materials Research, 2013,2482.
[11] 王欣. 近红外分析中光谱预处理方法的研究与应用进展[J]. 科技资讯, 2013(15): 2.
[12] 李尚科, 杜国荣, 李跑, 等. 基于近红外光谱技术和优化预处理方法的豆浆粉无损鉴别研究[J]. 食品研究与开发, 2020,41(17): 144-150.
[13] LIU Y, PENG Q W, YU J C, et al. Identification of tea based on CARS‐SWR variable optimization of visible/near‐infrared spectrum[J]. Journal of the Science of Food and Agriculture, 2020,100(1).
[14] CAI L D J. Wavelet transformation coupled with CARS algorithm improving prediction accuracy of soil moisture content based on hyperspectral reflectance[J]. Cai Lianghong Ding Jianli? 2017,33(16).
[15] 高升, 徐建华. 基于可见/近红外光谱技术的红提成熟度的判别模型[J]. 现代食品科技, 2022: 1-7.
[16] TIECHENG B, YOUQI C, MERCATORIS B T. The Contrast of Selecting Wavelength Capability of SPA and GA for Soil EC Detecting Model[J]. IOP Conference Series: Materials Science and Engineering, 2018,392(4).
[17] 郭文川, 朱德宽, 张乾, 等. 基于近红外光谱的掺伪油茶籽油检测[J]. 农业机械学报, 2020,51(09): 350-357.
[18] ZHOU L, CHENG S, YU H. Detection of Chlorophyll Content of Rice Leaves by Chlorophyll Fluorescence Spectrum Based on PCA-ANN, 中国湖南长沙, 2016.
[19] 乔宁, 刘韬, 饶敏, 等. 一种基于近红外光谱快速鉴别染色橙的新方法[J]. 食品工业科技, 2019,40(01): 225-228.
[20] 罗微, 杜焱喆, 章海亮. PCA和SPA的近红外光谱识别白菜种子品种研究[J]. 光谱学与光谱分析, 2016,36(11): 3536-3541.
[21] 赵芷岚, 董怡青, 苏光林, 等. 基于便携式近红外光谱技术的假冒茯苓块无损鉴别研究[J]. 中国果菜, 2022,42(10): 41-44.
[22] PAO L, GUORONG D, YANJUN M, et al. A novel multivariate calibration method based on variable adaptive boosting partial least squares algorithm[J]. Chemometrics and Intelligent Laboratory Systems, 2018,176.
[23] JIAHUA W, YIFANG W, JINGJING C, et al. Enhanced cross-category models for predicting the total polyphenols, caffeine and free amino acids contents in Chinese tea using NIR spectroscopy[J]. LWT, 2018,96.
[24] LUO W, TIAN P, FAN G Z, et al. Non-destructive determination of four tea polyphenols in fresh tea using visible and near-infrared spectroscopy[J]. INFRARED PHYSICS & TECHNOLOGY, 2022,123.
[25] 黄平捷, 李宇涵, 俞巧君, 等. 基于SPA和多分类SVM的紫外-可见光光谱饮用水有机污染物判别方法研究[J]. 光谱学与光谱分析, 2020,40(07): 2267-2272.
[26] 张伏, 王新月, 崔夏华, 等. 可见/近红外光谱结合GWO-SVM对千禧番茄的分类鉴别[J]. 光谱学与光谱分析, 2022,42(10): 3291-3297.
[27] 朱向荣, 李高阳, 江靖, 等. 基于多类别的镉稻米近红外光谱识别分析[J]. 中国食品学报, 2019,19(05): 263-269.

 京公网安备 11011302003690号
京公网安备 11011302003690号


