



- 收藏
- 加入书签

基于标签传播网络的社交机器人检测方法
摘要:人工智能和自然语言技术的突破性发展,催生了更加拟人化的社交机器人,给在线通信和网络安全带来了新的挑战。当前主流方法通过图神经网络(GNN)聚合社交网络图结构信息进行检测,但传统GNN 易受“过平滑”问题影响,且现有基于符号注意力机制的方法,虽然在一定程度上解决了“过平滑”问题,但仍局限于节点特征的聚合,忽视了不同特征维度的差异化影响。针对上述方法存在的局限性,本文提出一种基于标签传播网络的社交机器人检测方法,通过整合邻居节 检测。首先, 设计元素级符号 算正负注意力权重,实现邻居节点预测标签的差异化聚合;其次,构建多特征融合模块,采用注意力 本特征、 征及分类 应加权融合, 关键 0 数据集上的实验表明,本文方法在准确率与 F1 值上均显著优于现有基线模型:其中在 MGTAB 数据集上准确率达 9 1 . 2 7 % 、F1 值达 8 3 . 6 9 % ,对比基准方法分别提升 0.81、1.57 个百分点;在 TwiBot-20 数据集上准确率达 8 7 . 4 5 % 、F1 值达 8 8 . 9 4 % ,分别提升 0.21、0.2 个百分点。
关键词:社交机器人检测;标签传播网络;符号注意力机制
0 引言
在社交平台普及和发展过程中,社交平台上逐渐出现了一些社交机器人账户,这些账户由自动化算法软件控制,能够按照设定要求自动执行一些行为,如自动整理发布天气预报等信息,这些自动化程序大大降低了人力成本[1]。
然而有些恶意社交机器人账户被用于虚假信息传播、舆论操纵和负面内容放大,破坏了信息的有序传播与社会信任。例如,有关新冠疫情的虚假信息曾引发“信息疫情”。在公共突发事件中,社交机器人可能通过发布大量低可信度内容来操控公众情绪,干扰网络舆论的发展方向。因此,开展社交机器人检测研究对于保障信息传播的健康秩序和维护社会信任至关重要。
现有的社交机器人检测工作分为基于特征、文本和图结构的方法。基于特征的方法通过提取账户的元数据特征并结合传统分类器对社交账户进行检测[2]。然而,社交机器人操纵者经常通过故意篡改账户元数据信息,以逃避基于特征的检测方法。基于文本的方法利用循环神经网络和预训练语言模型,对推特内容进行编码并识别恶意意图。当前,随着生成式人工智能的发展,新兴社交机器人开始模仿真实用户的发文内容和风格,也大大影响了基于文本检测方法的性能。考虑到社交平台上账户之间的社交关系特征能够进一步提升检测性能,研究人员开始关注基于图结构的方法,将账户和账户间的社交关系分别作为节点和边构建图结构,使用账户元数据和推文特征作为节点初始特征,通过图神经网络,如GCN、RGCN、RGT 等学习账户的社交图特征以进行社交机器人账户检测。由于基于图结构的方法能够捕获到机器人账户之间的互动特征,该类方法达到了最先进的性能,并且在检测新型机器人方面,相较于基于特征和文本的方法更有优势。
尽管基于图神经网络的社交机器人检测取得了显著进步,然而图神经网络的检测方法主要基于同质性假设,认为图中有边相连的两个节点属于同一类,该假设忽视了存在于现实社交网络中的异质连接,比如广泛存在于真实社交网络中的社交机器人和真人账户之间的连接,通过图神经网络的邻居特征聚合,机器人帐户的可疑特征会经过真人账户的过平滑,导致漏检。
针对该问题,最近的工作提出基于符号注意力机制的图结构聚合方法,通过使用 tanh 函数替换注意力机制中的 softmax 函数,使其能够输出正负注意力权重,自适应地聚合邻居节点的特征信息。这类方法虽然取得了一定效果,但仍然局限于对节点特征的聚合,并且所有的特征维度施加统一的权重,忽略了不同特征维度在聚合过程中可能存在差异性。
本文提出一种基于标签传播网络的社交机器人检测方法,尝试整合邻居节点的预测标签信息。方法中设计元素级符号注意力机制,为每类标签计算单独的符号注意力权重,随后利用获得的权重聚合邻居节点的预测标签用于最终决策。此外,方法中还设计了一个多特征融合模块,通过注意力机制自适应融合节点的文本特征、数值元信息特征、分类元信息特征,帮助模型更准确捕获和利用关键特征。
在 MGTAB 和 TwiBot-20 两个公开的社交机器人检测数据集上进行验证实验:MGTAB 数据集上准确率达到91 . 2 7 % ,F1 值达到 8 3 . 6 % ;TwiBot-20 数据集上准确率达到 8 7 . 4 5 % ,F1 值达到 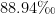 。两个数据集上的性能均超过已有的基线模型,表明了本文方法的通用性和有效性。
。两个数据集上的性能均超过已有的基线模型,表明了本文方法的通用性和有效性。
本文组织结构如下:第 1 节介绍相关工作;第2 节介绍社交机器人检测任务定义,第3 节对本文方法进行介绍;第4 节为实验结果以及分析;第5 节对本文工作进行总结。
1 相关工作
在 Twitter 机器人检测领域,研究者们提出了多种方法,包括基于特征、文本以及图结构的方法。
基于特征的方法往往从用户元数据、推文以及社交关系等提取特征,并使用传统机器学习模型如支持向量机[3]、随机森林来识别机器人账户。这类方法在早期取得了一定成效,但由于这些特征很容易被篡改,使得这些方法在面对复杂伪装策略时往往表现有限。
基于文本的检测方法使用自然语言处理相关技术从账户的个人描述和推文中挖掘异常特征用于机器人检测。Wei 等人使用双向长短时记忆网络(Bi-direction Long Short Term Memory Network, Bi-LSTM)网络处理处理账户文本用于机器人检测。Cai 等人认为账户历史推文具有时序特征,提出了 LSTM 和 CNN 组合的方法,以提取账户的潜在时序模式。随着预训练模型的兴起,Dukić等人使用 BERT 处理账户的推文。然而,随着生成式人工智能的进步,新兴社交机器人普遍使用大模型生成的推文内容,这些文本高度逼近真实文本,为基于文本的检测方法提出了挑战。
基于图结构的方法通常将账户抽象为图中的节点,并将账户间的关注、被关注、转发、点赞等互动行为映射为节点间的边,进而将推特平台中的社交关系构建为图结构;在此基础上,利用图神经网络,以社交关系网络为背景,为某个节点聚合其邻居节点特征,从而实现更好的检测性能。Feng 等人提出一个使用关系图卷积网络的社交机器人检测方法,将关注和粉丝定义为两种关系,从而构建带有边类型的异质图。在此基础上,使用关系图卷积R-GCN 汇总邻居节点信息,获得中心节点的表征,用于机器人检测。Li 等人通过提及、转发、评论关系构建多关系图,使用 GCN 学习每种关系图中的节点表示,随后拼接得到节点的初始表示;使用 GAT 根据邻居节点的重要程度聚合周围信息,得到最终的节点表示。Feng 等人设计关系图 Transformer 网络,根据节点之间的注意力权重汇总邻居节点信息;设计语义注意力网络,根据不同关系视图的重要性,合并不同关系视图下的节点表示。Lei 等人等人提出文本-图结构的交互模块,旨在学习过程中实现跨模态的信息交换。Liu 等人引入社区感知的混合专家模块,为元数据、文本内容和社交网络结构特征分别构建模态特定的混合专家层,以增强模型的领域泛化能力。
虽然这些方法取得不错的性能,但这些方法中所使用的图神经网络框架都基于同质性假设构建,即认为存在连接边的两个节点都属于同一类别。针对该问题,Ye 等人和 Yang 等人设计符号注意力机制方法,学习节点间的正负相关性,通过正负权重自适应聚合邻居节点的特征。本文进一步将符号注意力方法扩展到元素级,并且设计标签传播网络,能够为每类标签计算单独的符号注意力权重,利用获得的权重聚合邻居节点的预测标签用于最终的社交机器人账号检测。
2 社交机器人检测任务定义
社交机器人检测任务的目标是通过分析用户信息,判断一个用户是真人账号还是自动化机器人账号。用户信息包含以下内容:
个人简介是指用户在社交网络账户中用以简明扼要地介绍自己身份、兴趣、职业背景或其他相关个人信息的文本。
历史推文是指该账号自创建以来在社交网络上发布的所有过往消息的总和。这些推文记录了用户在特定时间段内的活动、表达的观点、分享的内容以及与其他用户的互动。
元信息是指账号创建时,社交平台生成的一些字段信息,包括数值信息和分类信息。数值信息如粉丝量、关注量等,分类信息由布尔变量构成,如账号是否经过认证、账号是否使用默认头像等。
社交关系是指账号的粉丝账号列表和关注账号列表。
通过粉丝和关注关系构建的社交关系图可表示为࣡ 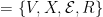 ,
, 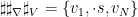 ,N 表示节点的数量,对于推特用户ݒ ,其节点特征包括个人简介、历史推文、元信息;ܺ表示所有节点的特征表示;ℇ表示边的集合;
,N 表示节点的数量,对于推特用户ݒ ,其节点特征包括个人简介、历史推文、元信息;ܺ表示所有节点的特征表示;ℇ表示边的集合;
ܴ表示边的类型。
3 基于标签传播网络的社交机器人检测
本文提出的基于标签传播网络的社交机器人检测模型,如图1 所示,模型包括节点特征编码、多特征融合、多层感知机分类器和标签传播网络四个部分,接下来将详细介绍各个部分。
3. 1 节点特征编码
个人简介&历史推文信息特征:对于每条推文和个人简介,本文使用预训练模型 TwHIN-BERT 对文本进行编码获得所有词元表示,随后通过向量平均得到文本的表示。
图1 模型整体结构
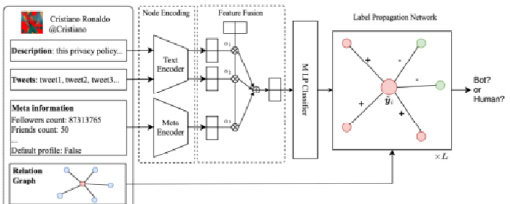
对于账号的历史推文,进一步计算所有推文表示的向量平均得到历史推文的整体表示。通过这种方式,对于推特用 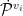 ,可计算得到其对应的个人简介表示ݔୢ和历史推文表示ݔ௧。随后对于这两个表示分别采用一层感知机编码,获得其低纬度的表示,计算公式如下所示:
,可计算得到其对应的个人简介表示ݔୢ和历史推文表示ݔ௧。随后对于这两个表示分别采用一层感知机编码,获得其低纬度的表示,计算公式如下所示:
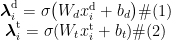
ୢ和ℎ୲分别为个人简介和历史推文的低纬度表示, σ ( ⋅ ) 表示 LeakyRelu 激活函数, 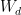 、
、 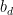 、
、 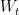 、
、 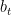 是可学习参数。
是可学习参数。
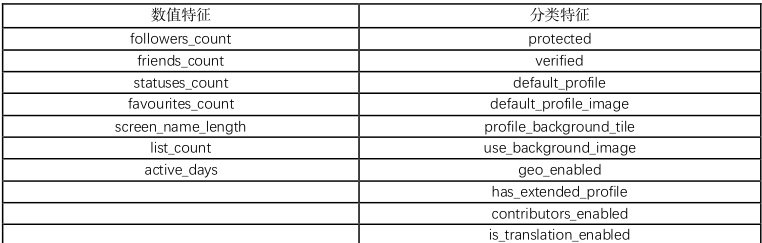
元信息特征:借鉴先前的方法,本文使用7 个数值信息和10 个分类信息特征,详细特征如表1 所示。
本文采用 z-score 归一化方法对数值特征进行规范化处理,获得数值特征ݔ୬;将分类特征中 True 和 False 映射为 1 和0,获得分类特征ݔୡ。随后采用1 层感知机网络学习元信息特征,计算公式如下:
其中,ߪ(∙)表示 LeakyRelu 激活函数, 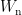 、
、 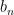 、
、 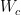 、
、 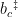 是可学习参数。
是可学习参数。
表1 元信息特征
3. 2 多特征融合
经过节点特征编码获得个人简介表示 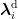 、历史推文表示ℎ୲、数值特征ℎ୬和分类特征ℎୡ后,本文采用基于注意力的多特征融合方法,通过注意力机制对不同类型的特征进行加权,赋予关键特征更大的权重,以提高重要特征对结果的贡献。基于注意力的多特征融合方法计算公式如下:
、历史推文表示ℎ୲、数值特征ℎ୬和分类特征ℎୡ后,本文采用基于注意力的多特征融合方法,通过注意力机制对不同类型的特征进行加权,赋予关键特征更大的权重,以提高重要特征对结果的贡献。基于注意力的多特征融合方法计算公式如下:
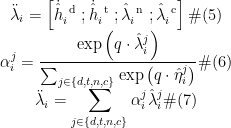
其中, 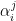 表示向量堆叠,ݍ表示全局查询向量,通过随机初始化生成,用于从不同特征中筛选关键特征。通过多特征融合方法,可获得更具代表性的节点特征ℎ。
表示向量堆叠,ݍ表示全局查询向量,通过随机初始化生成,用于从不同特征中筛选关键特征。通过多特征融合方法,可获得更具代表性的节点特征ℎ。
3. 3 分类器
分类器由2 层多层感知机构成。对于每个节点最终的特征表示ℎ,分类器判断该节点是真人账号还是机器人账号,其计算过程如下所示:
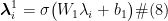
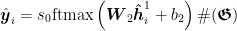
其中, 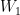 、ܾଵ和ܹଶ、
、ܾଵ和ܹଶ、 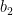 分别表示第 1 层、第 2 层多层感知机中的可学习参数;ߪ(∙)表示 LeakyRelu 激活函数。
分别表示第 1 层、第 2 层多层感知机中的可学习参数;ߪ(∙)表示 LeakyRelu 激活函数。
3. 4 标签传播网络
标签传播网络(Label Propagation Network, LPN)通过整合邻居节点的预测结果做出最终预测,有助于提高模型泛化性。
为了能够自适应地聚合不同标签信息,本文设计元素级符号注意力计算方法,结合节点特征来建模预测标签的正相关和负相关性,随后基于社交关系图,对邻居节点的预测结果进行加权和聚合用于最终检测,计算过程如下所示:
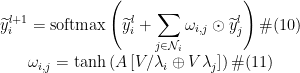
其中,⨀表示哈达玛积,⨁表示向量拼接操作,tanh是双曲正切函数,ܣ和ܸ是可学习参数, 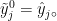 在社交机器人检测任务中,
在社交机器人检测任务中, 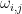 是 2 维向量,
是 2 维向量, 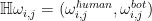 ,߱∗, ∈ (−1,1)表示节点݅与其邻居节点݆间的符号注意力权重,
,߱∗, ∈ (−1,1)表示节点݅与其邻居节点݆间的符号注意力权重, 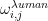 表示作用于Human 类的权重,
表示作用于Human 类的权重, 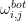 表示作用于Bot 类的权重。
表示作用于Bot 类的权重。
3. 5 模型训练
基于多层感知机的分类器提供初始的预测概率,标签传播网络则在建模节点间相关性的基础上,进一步整合邻居节点的标签结果做出最终预测。本文使用交叉熵损失对基于多层感知机的分类器和标签传播网络进行优化,损失计算方法如下:
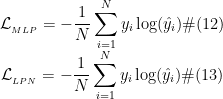
其中, 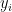 表示第݅个节点的标签。
表示第݅个节点的标签。
本文使用多任务联合学习方式训练整个模型,公式如下所示:
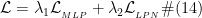
ߣ 和ߣ 是超参数,用于平衡两个损失的重要程度。
4 实验结果
4. 1 数据集
本文使用国际公开的 TwiBot-20 和 MGTAB 两个数据集来验证所提方法的效果,数据集统计信息如表 2 所示。
表2 数据集统计表

TwiBot20 数据集包含229580 个节点,但只有11826 个节点带有真人或机器人标签。为确保与先前工作[4]的连贯性,TwiBot20 数据集采用了标准的划分方式。对于 MGTAB 数据集,本文遵循文献中所采用的划分方法,以确保最终的训练集、验证集和测试集划分与先前研究[5]保持一致。此外,为了构建社交关系图,在两个数据集中均利用用户之间的“关注”(following)和“粉丝”(follower)关系进行图的构建。
4. 2 基线模型
本文与先前基于图结构的社交机器人检测方法进行对比。根据针对问题的相似性,选择的基线模型如下:GCN 是一个典型的图神经网络,通过平等地聚合邻居节点特征获得中心节点的特征表示,随后将其输入到多层感知机分类器用于机器人检测。
GAT 引入了注意力机制来区分聚合过程中邻居节点的重要性,学习到的节点表示被输入到一个多层感知机(MLP)中进行分类。
GraphSAGE 是一个通用归纳框架,通过节点属性和采用最大池化聚合邻居节点获得节点表示。
BotRGCN 将 following 和 follower 视为两种关系,构建带有边类型的异质图。在此基础上,使用关系图卷积R-GCN 汇总邻居节点信息。
RGT 采用与 BotRGCN 相同的构图方式,在每种关系视图下,采用图 Transformer 网络聚合邻居节点特征;使用语义注意力网络,根据不同关系视图的重要性,合并不同关系视图下的节点表示。
SEBot 使用结构熵优化图结构,揭示隐含在社交网络中的的层次社区结构;设计符号注意力机制,通过计算节点间的负注意权重以实现聚合高频特征,缓解传统图神经网络在聚合特征时存在的过平滑问题。
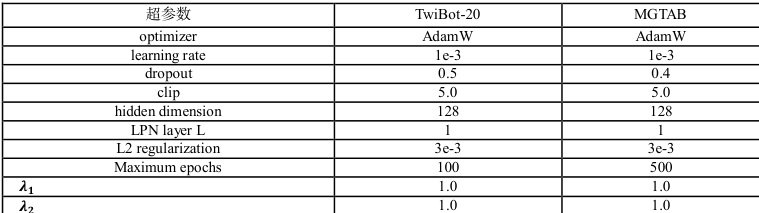
4. 3 参数设置
TwiBot20 和 MGTAB 数据集上的超参数设置如表 3 所示,使用 Pytorch 和 Pytorch Geometric 开源库实现本文模型。
表 3 TwiBot-20 和 MGTAB 数据集超参数设置
4. 4 实验结果及分析
表 4、5 分别展示了本文模型和基线模型在 MGTAB、TwiBot-20 数据集的实验结果,使用准确率(Acc)、F1值、召回率(Recall)、精确率(Precision)指标评估模型性能,计算5 次实验结果的平均值得到最终的模型性能。
表4 MGTAB 数据集上不同模型的性能对比
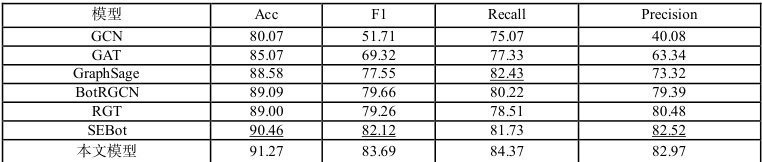
表5 TwiBot-20 数据集上不同模型的性能对比
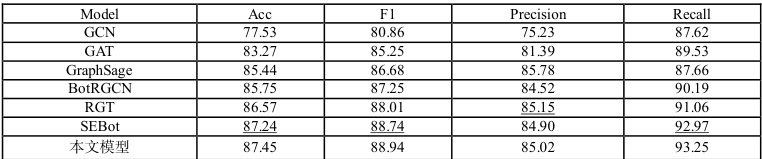
从表 4、5 中可以看出,本文模型在两个数据集上的准确率和 F1 值均超过现有基线模型,证明了本文模型的有效性和通用性。此外,本文模型在召回率指标上,相较于基线模型均有明显提升,说明本文提出的标签传播网络,能够缓解已有工作中节点特征的过平滑问题,从而能够检测出更多的社交机器人账户,减少漏检。
BotRGCN 和 RGT 在建模过程中考虑了社交关系网络中边的类型特征。具体地,它们将“关注”(following)和“粉丝”(follower)视为两种不同的边类型进行建模,从而能够更细致地捕捉不同类型社交关系对用户行为和属性的影响。这种对边类型特征的建模方式使得 BotRGCN 和 RGT 在性能上优于传统的图神经网络方法(如GCN、GAT、GraphSage)。进一步地,RGT 通过使用能力更强的 Transformer 架构替代 GCN 作为图编码器,进一步提升了模型的性能。
SEBot 设计超越同质性假设的特征聚合方式,并且利用结构熵挖掘社交关系网络中潜在的社区结构信息。与其相比,本文模型在所有指标上均取得更高的结果,证明了本文提出的标签传播网络的有效性。
4. 5 消融分析
为了进一步验证本文所提出的基于注意力的多特征融合和标签传播网络方法的有效性,本文在两个数据集上执行消融实验,实验结果如表6、7 所示。
表6 MGTAB 数据集上的消融实验

表 7 TwiBot-20 数据集上的消融实验

“-Fusion”表示去除基于注意力机制的多特征融合模块,改用简单的向量拼接操作来整合不同类型的特征,进而生成节点的最终特征表示。而“-LPN”则表示移除标签传播网络模块,此时模型仅依赖简单的多层感知机分类器,不再借助社交关系图中邻居节点的特征信息[6]。
实验结果显示,移除这两个模块中的任何一个均会导致模型性能的下降,这充分证明了这两个模块的有效性。特别是当移除基于注意力的多特征融合模块仅使用标签传播网络时,性能出现了较大的下降,MGTAB 数据集上表现得更为明显。这表明基于注意力的多特征融合模块,能够有效捕获关键的特征,获得更好的节点特征表示,这对于标签传播网络中学习同质或异质节点间的正或负相关性有帮助,从而正确聚合邻居节点的标签信息。
4. 5 案例分析
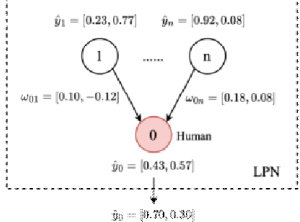
为了更清晰的说明标签传播网络(LPN)的效果,本文选取TwiBot-20 测试集中1 个节点及其邻居节点进行分析,结果如图2 所示。
图 2 展示了标签传播网络聚合邻居节点的预测目标节点标签的过程,图中节点 0 表示目标节点,它的正确标签为 Human,1\~n 表示邻居节点,ݕො表示多层感知机分类器的预测结果,其错误地将该节点预测为 Bot, 标签传播网络通过建模节点间的相关性߱,聚合邻居节点标签信息对ݕො进行修正,使得最终结果ݕ正确预测为Human。
图2 标签传播网络聚合邻居节点标签过程案例
5 总结与展望
本文提出基于标签传播网络的社交机器人检测方法,通过元素级符号注意力机制差异化聚合邻居标签信息,并结合多特征融合模块提升检测性能。实验结果表明,该方法在 MGTAB 和 TwiBot-20 数据集上准确率与F1 值均优于基线模型,验证了其对异质信息干扰的缓解能力及特征融合的有效性。未来工作,我们将尝试利用大语言模型的语义理解能力,分析账户历史推文中的语义特征,用于丰富账户的特征信息,从而帮助提升社交机器人检测性能。
参考文献
[1]张玄, 李保滨. 微博环境中的机器人账户检测综述[J]. 中文信息学报, 2022, 36(12): 1-15.
[2]余尚戎,肖景博,殷琪林,等.关注社交异配性的社交机器人检测框架[J].信息网络安全,2024 ,24 (02):319-327
[3] 卢昊宇,刘峰,王博雅,等.基于链接预测匹配的动态社交机器人检测方法[J].信息工程大学学报,2024 ,25(03) :285-291
[4]李阳阳,杨英光.基于生成对抗网络的社交机器人检测[J]. 计算机与现代化,2022 (03) :1-6
[5]Wei F, Nguyen U T. Twitter bot detection using bidirectional long short-term memory neural networks and wordembeddings[C]//2019 First IEEE International conference on trust, privacy and security in intelligent systems andapplications (TPS-ISA). IEEE, 2019: 101-109.
[6]Feng S, Wan H, Wang N, et al. What Does the Bot Say? Opportunities and Risks of Large Language Models inSocial Media Bot Detection[C]//Proceedings of the 62nd Annual Meeting of the Association for ComputationalLinguistics (Volume 1: Long Papers). 2024: 3580-3601.

 京公网安备 11011302003690号
京公网安备 11011302003690号


