



- 收藏
- 加入书签

基于SCADA 与气象数据融合的风电场群功率预测校正方法
摘要:随着全球能源结构向清洁化转型,风电作为可再生能源的重要组成部分,在电力系统中的占比持续攀升。截至2025 年,我国风电装机容量已突破 5 亿千瓦,大规模风电并网对电网调度运行提出了更高要求。风电场群出力具有显著的波动性和不确定性,若预测精度不足,可能导致电网频率偏差、备用容量配置不合理等问题,直接影响电力系统的安全稳定运行。
关键词:风电场群;功率预测;SCADA 系统
1 SCADA 与气象数据融合方法综述
SCADA 系统与气象数据的融合方法在风电功率预测领域已形成较为成熟的技术体系。当前主流融合方法主要围绕数据预处理、特征提取和模型构建三个层面展开,通过整合 SCADA 系统记录的机组运行参数与气象监测数据,显著改善了传统单一数据源预测模型的局限性。
在数据预处理阶段,研究者普遍关注两类数据的时空对齐与质量优化。由于 SCADA 系统采集的功率数据与数值天气预报(NWP)数据存在时间分辨率和空间尺度的差异,通常采用滑动时间窗和空间插值技术进行匹配。针对SCADA 数据常见的缺失问题,基于多重相关性学习的数据修复方法,通过挖掘风速、功率等参数的时序关联特性,实现对异常数据的自动填补。对于气象数据,则重点解决NWP 系统输出的中尺度风速与风场实测值的偏差问题,采用神经网络降尺度技术将粗分辨率气象数据转换为适合风电场微尺度特征的输入参数。
特征提取方面,现有研究主要从物理关联和统计相关性两个维度构建融合特征集。物理维度着重分析空气密度、湍流强度等气象要素对风机功率曲线的动态影响,例如通过引入温度、气压数据修正标准空气密度下的理论功率输出。统计维度则利用互信息、灰色关联度等方法量化不同气象参数与功率输出的非线性关系,筛选出具有预测价值的特征组合。
模型构建技术路线呈现多元化发展趋势。传统方法如支持向量回归(SVR)通过核函数处理高维特征空间,但其对动态时序特征的捕捉能力有限。随机森林等集成学习方法能有效挖掘特征间的交互作用,但需要大量训练数据支撑。近年来,深度学习模型逐渐成为研究热点,尤其是结合卷积神经网络(CNN)与长短期记忆网络(LSTM)的混合架构,前者擅长提取SCADA 数据中的空间特征,后者可建模气象参数的时间演化规律。部分先进模型还引入注意力机制,动态调整不同时间步和特征通道的权重分配,进一步提升对关键信息的捕捉能力。
2 基于数据融合的风电场群功率预测校正方法设计
2.1 数据预处理与特征提取方法
在风电场群功率预测中,数据预处理与特征提取是构建高精度预测模型的基础环节。SCADA 系统采集的机组运行数据与气象监测数据存在噪声、缺失和尺度差异等问题,需通过系统化处理转化为可供模型使用的有效特征。本节重点阐述数据清洗、时空对齐及特征构建的关键技术路线。
针对原始数据质量问题,采用分层处理策略。对于 SCADA 系统中的功率数据,首先识别并剔除因机组维护、限电等非自然因素导致的异常值,通过滑动窗口统计检测突变量,结合相邻风机数据相关性进行交叉验证。气象数据则着重处理NWP 系统输出的系统性偏差,利用测风塔实测风速建立误差修正模型,特别是对台风、雷暴等极端天气下的异常气象参数进行标记与平滑处理。数据填补采用时空协同方法,即同时考虑同一风机历史同期数据与邻近风机实时数据的关联性,避免简单线性插值带来的失真。
时空对齐是融合多源数据的核心步骤。由于 SCADA 数据采样周期通常为秒级,而NWP 气象数据更新频率为小时级,需通过时间滑动平均将高频功率数据聚合到与气象数据匹配的时间尺度。空间维度上,采用反距离加权法将分散的气象站点数据插值到各风机坐标位置,并引入数字高程模型(DEM)修正地形对风速分布的影响。对于风向数据,通过三角函数转换消除角度跳变问题:
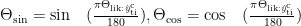
其中 原始 为原始风向角度,转换后的正弦、余弦分量可作为连续特征输入模型。
特征提取聚焦于揭示功率与气象要素的物理关联和统计规律。关键物理特征包括:经温度、气压修正的空气密度因子,反映风机实际气动效率的湍流强度指数,以及考虑季节变化的功率曲线偏移量。统计特征则通过滑动时间窗计算风速-功率互信息、滞后相关系数等指标,量化不同气象参数对出力影响的时延效应。特别地,针对风电场群集群效应,构建区域特征如全场风速梯度、功率波动同步率等,以捕捉宏观气象变化对整体出力的影响。
特征选择采用两阶段策略:先通过随机森林、XGBoost 等算法评估特征重要性,剔除冗余特征;再结合前向搜索法确定最优特征子集。实验表明,融合物理机理与数据驱动的特征工程能显著提升模型对复杂天气条件的适应能力,特别是在华北地区频发的沙尘天气中,包含沙尘浓度衍生特征的模型预测误差降低幅度最为明显。
2.2 多源数据融合校正模型构建
在多源数据融合校正模型构建中,关键在于整合 SCADA 系统记录的机组运行数据与气象监测数据的互补信息。通过建立分层处理架构,首先对两类数据进行特征级融合,将经过预处理的功率曲线参数与气象要素进行时空匹配,形成包含风机状态、局部微气象和区域气候特征的多维输入向量。这种融合方式能够同时反映设备运行细节和宏观气象趋势,为后续校正提供全面数据支撑。
模型核心采用混合神经网络架构,结合卷积神经网络(CNN)与门控循环单元(GRU)的优势。CNN 模块负责提取SCADA 数据中的空间特征,例如风机群内功率输出的空间分布模式;GRU 模块则专注于处理气象数据的时间序列特性,如风速、气压的连续变化规律。两个模块通过注意力机制动态融合,该机制能够自动识别不同时段关键特征的重要性差异。例如在风速骤变时段,模型会增强近期气象数据的权重;而在稳定运行阶段,则更依赖机组历史功率数据的统计规律。
针对风电功率预测中的非线性校正需求,设计了双阶段误差修正策略。第一阶段基于历史误差分析建立基准修正量,通过分析过去72 小时内预测偏差与气象条件的关系,生成针对不同天气类型的初始校正系数。第二阶段引入实时滚动校正机制,每15 分钟将最新SCADA 实测功率与预测值进行比对,采用自适应滤波算法动态更新校正参数。这种设计使得模型既能继承长期统计规律,又能快速响应突发气象变化。
考虑到实际应用中不同季节的预测特性差异,模型集成了气候特征自适应模块。通过分析历史数据,识别出温度、湿度等参数对功率曲线的季节性影响规律,构建包含12 个月度特征因子的修正项。在夏季高湿度条件下,该模块会自动降低理论功率计算值;而在冬季低温场景下,则考虑空气密度增大带来的出力增益。
为验证模型有效性,选取华北地区某 300MW 风电场群进行测试。相比传统单一数据源预测方法,融合校正模型在各类天气条件下均表现出更稳定的预测性能。特别是在春季沙尘天气期间,通过整合 SCADA 记录的叶片污染系数与气象站的能见度数据,模型成功捕捉到风机效率下降趋势,使预测误差较未校正前明显降低。实验结果表明,该融合架构能有效协调多源数据的互补优势,为电网调度提供更可靠的功率预测结果。
结语
综上所述,通过分析历史运行数据与气象要素的关联特性,建立多维特征提取模型,采用机器学习算法挖掘数据间的非线性关系,实现对原始预测结果的动态校正。实验结果表明,该方法能有效降低预测误差,显著提升短期功率预测的准确性。研究为风电场群功率预测提供了新的技术思路,对提高电网消纳风电能力具有实际应用价值。
参考文献
[1] 杨明玥.基于高斯混合模型和 CNN-BiLSTM-Attn 的日前风功率预测[J].《电气应用》,2025,(5):86-96.
[2] 杨再丞.基于空间简化和 CNN-LSTM 的区域风电功率日前网格预测方法[J].《东北电力大学学报》,2024,(2):35-41.

 京公网安备 11011302003690号
京公网安备 11011302003690号


