



- 收藏
- 加入书签

基于知识增强大模型技术的医疗查询意图分类方法
 打开文本图片集
打开文本图片集

摘要:基于预训练大语言模型(Large Language Models, LLMs,后简称大模型)和领域知识增强的查询意图分类方法对医疗搜索技术影响显著,为提高医疗搜索查询效率提供了科学依据。通过分析大模型在理解和分类用户搜索意图的应用效果,其与传统基于机器学习的方法相比,新方法构建在海量通用知识体系上,大大减少了标注数据样本量,并且在医疗的通用知识理解能力上有显著提升,在处理复杂和长查询时的表现尤为出色。同时通过知识增强技术对大模型进行查询扩展,解决了传统方法知识难于更新的限制。这一发现不仅提高了医疗搜索和对话系统的用户查询体验,也为在线医疗的未来发展提供了新的方向。
引言/背景:
用户查询的最终意图是满足需求解决问题。基于此搜索引擎或对话系统必须为用户提供能够满足其意图的结果。例如用户搜索“最近早上起来浑身无力是怎么回事?”,搜索引擎需要知道用户查询意图是”病情诊断:已知症状,判断可能的原因”并基于此召回排序;因此能够准确识别查询意图成为搜索引擎或对话系统服务水平的关键。
然而随着信息化技术和全球化趋势的发展,用户查询需求产生了一系列新的变化:
1)在政策和疫情的影响之下,在线问诊需求增长迅速,然而医生资源是稀缺的,由此促使了自动化医疗问诊的发展,以人机对话来辅助问诊过程,搜索或对话系统需要基于对话历史来回答,用户查询复杂度变大,长文本的查询越来越多,数据表明近三年中长查询从10%增加至30%.
2)全球化加快了疾病的传播速度,新的病症新的药品新的疗法的出现周期缩短,因此查询或对话系统中需要能够处理新的名词概念
存在问题
首先,传统搜索引擎面临着的理解能力的挑战。例如,当用户进行复杂的医疗相关查询时,传统查询技术往往仅依赖关键词匹配,无法处理长的带上下文的文本,而无法深入理解用户的实际需求和查询的具体医学背景。这会导致返回的结果缺乏语义相关性。假设用户搜索“胸痛的紧急处理方法”,期望找到心绞痛或心脏病发作等紧急情况的处理指南。然而,传统搜索引擎可能只是简单地匹配到包含“胸痛”关键词的文章,这种情况下,紧急情况下需要的快速、准确的医疗建议就无法有效提供,可能导致延误治疗。
其次,机器模型面临着知识更新的时效性局限性,即基于模型中过去的知识来回答当前用户问题,但在目前高速发展的信息化阶段,出现新问题新知识新概念频率极大加快,不断标注新语料来更新训练模型成本巨大,假设一个患者查询关于“COVID-19的最新治疗方法”,如果机器学习系统仅仅基于早期的疫情数据进行训练,可能无法提供关于最新研究发现、新药或新治疗方案的信息。
问题分析
1、缺乏语义理解能力
传统搜索引擎在处理用户查询时主要依赖关键词匹配,缺乏深层次的语义理解能力。
传统的基于特征的机器学习技术,其技术要点是数据的特性工程,主要是通过One-Hot特性向量等表示特性,基于词袋、TF-IDF等统计统计语言模型进行特征分析,最后使用机器学习实现查询意图分类。较传统人工规则阶段其泛化能力进一步提升,但存在的缺点明显:
(1)特征准确性得不到保障:(2)人工设计和选择特征成本较高:(3)适应性差:传统的基于特征的方法通常需要大量的人工标注数据,并且难以扩展到新的域或任务。
2、上下文推理能力不足
传统搜索技术同时也缺乏有效的上下文推理能力,这导致它们无法根据上下文信息或用户的历史查询行为来做出合理的推断和响应。
大多数现有的搜索技术依赖于静态的、预定义的规则和模型。这意味着它们在处理新出现的概念、术语或流行趋势时常常显得力不从心。
综上所述,传统搜索技术在语义理解、上下文学习推理能力的不足,已成为制约其发展的主要问题。为了解决这些问题,有必要引入更先进的技术,比如基于人工智能的预训练模型和知识增强技术.
方法
预训练大模型技术能利用预训练阶段的通用知识,同时知识增强技术能够结合外部专业知识快速补充领域知识,更好地理解语言的复杂性和用户的意图,从而提供更准确和相关的搜索结果。通过引入这些先进技术,搜索引擎的发展开始朝着更加智能化和个性化的方向发展。
1、大模型技术
大模型技术经历了静态词嵌入阶段,这些词向量是从高维空间(如one-hot编码)映射到低维、连续的向量空间中。这些向量捕捉了单词的潜在语义和语法特征。然而,静态词嵌入无法区分词语在不同上下文中的不同含义,例如,“阳性”在不同的医学测试中可能有不同的意义。
带上下文的动态词嵌入阶段:解决了上下文的多义性问题。这种情况下,使用基于CNN、RNN、LSTM或GRN等算法的动态词嵌入技术可以更好地理解查询中每个词语的具体医学含义,提供更准确的信息或建议。
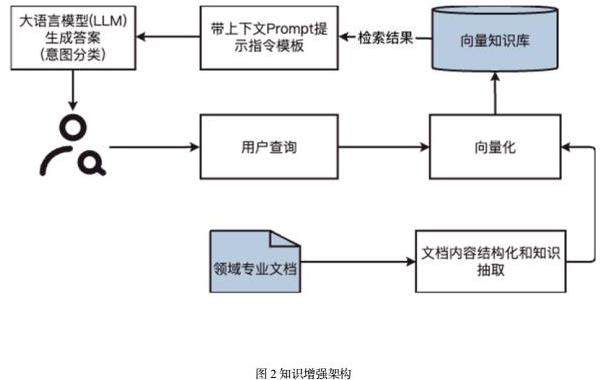
1)、步骤一:利用知识图谱或现有领域专业知识文档,基于LlamaIndex 抽取结构化知识,将知识向量化,保存到向量知识库。
2)、步骤二:将查询向量化,从向量数据为检索出相关的专业知识上下文信息。
3)、步骤三:将检索结果与特定指令模板进行组合,将组合后的Prompt发送给大模型生成回答。
实验
本实验利用了CBLUE开放数据集进行意图分类实验。CBLUE是中文生物医学领域的一个公认基准测试集,用于评估各种模型在医学语言理解方面的性能。其中“医疗搜索检索词意图”数据集涉及广泛的用户查询意图类别,共包含6900多个精心标注的样本,每个样本均被标注为特定的意图类别,反映了真实世界搜索引擎的使用情况。样本覆盖的意图类别包括:治疗方案、后果描述、病情诊断、预防注意事项、病因分析、药物功效作用、医学指标解读、就医建议、疾病描述以及医疗费用等。除此之外CBLUE还提供了更多相关医疗信息处理的子任务数据,这部分做为本实验知识增强的知识补充.
中文医学命名实体识别
中文医学文本实体关系抽取
医疗因果实体关系抽取
临床发现事件抽取
临床术语标准化
智能对话诊疗数据集
医疗对话临床发现阴阳性判别
临床试验筛选标准短文本分类
疾病问答迁移学习
等
例如:原始样本为[问: 请识别以下搜索query的意图类型:\n幽门螺旋杆菌阳性是什么意思\n搜索意图选项:治疗方案,后果表述,注意事项,就医建议,医疗费用,指标解读,功效作用", "答": ]。增强后的提示为:[幽门螺旋杆菌”是胃内致病菌,中国人群中60%-70%有感染这细菌\n“阳性”是指已有症状疾病或者假设未来可能发生的疾病等;“阴性”是指未患有症状疾病,\n问: 请识别以下搜索query的意图类型:\n幽门螺旋杆菌阳性是什么意思\n搜索意图选项:治疗方案,后果表述,注意事项,就医建议,医疗费用,指标解读,功效作用", "答":]
评估指标:实验主要采用准确率(Accuracy, Acc)作为评估模型性能的核心指标。Acc= 预测正确的条目数 / 预测总条目数。该指标在意图分类任务中尤为关键,直观反映了模型在识别用户查询意图的准确性。
实验方法:实验的核心目标是提升搜索引擎在处理用户查询意图时的准确度。实验重点对比了传统机器学习TextCNN和基于BERT的微调(finetune)方法以及基于ChatGLM的参数效率微调(lora)方法以及数据增强后在意图分类任务上的性能。
1)TextCNN方法:该方法使用不同大小的卷积核构建卷积层,以提取局部特征。采用最大池化层整合特征,并通过全连接层进行分类输出。实验中调整了卷积层参数和模型结构,以适配CBLUE数据集特性。
2)BERT-Chinese finetune方法:采用预训练的BERT模型,并通过微调方式调整以适应意图分类任务。微调过程中,使用CBLUE数据集训练模型,以更好地理解和分类用户的查询意图。
3)ChatGLM-6B lora方法:基于ChatGLM-6B生成式模型,结合预训练和微调方法进行优化。该方法强调在保持模型通用性的同时,提高其对特定任务(如意图分类)的适应性。同时在该方法基础上对样本输入进行了知识增强的实验。
实验结果:TextCNN:作为一种较为传统的方法,TextCNN在整体准确率上略低于BERT finetune和ChatGLM PEFT,但在处理关键词特征明显的查询意图时表现良好。BERT finetune:在CBLUE意图分类任务中,BERT finetune方法展现了较高的准确率,突显了BERT模型在深层语义特征捕获方面的优势。ChatGLM +LORA:该方法在处理长文本和复杂查询方面表现出色。ChatGLM +LORA+知识增强,取得了最好的成绩,说明了知识增强对模型性能的影响显著。
预训练模型阶段:这些模型能够通过捕捉上下文信息和长距离依赖关系,提供更深入的医疗知识理解,如ELMO、GPT、BERT、ERNIE3.0等,都是基于Self-Attention的Transformer架构。这些模型通过增加模型参数来捕获大量的医学知识,从而能够更加深入地理解用户的搜索意图。
大模型阶段:例如GPT-2, GPT-3, T5, BERT Large等。这些模型拥有大量的参数(从数亿到数十亿甚至更多),能够捕获更复杂的语言规律和世界知识。同时提供了更高效的训练和微调方法提高任务泛化能力:使其在理解任务(如分类、问答)和生成任务(如文本生成、翻译)上表现出色。
目前,主流的开源生成式大语言模型有LLaMA、ChatGLM等,根据当前任务对中文的要求,我们选择了对中文支持较好的ChatGLM做为模型的基座,它是清华大学提出的支持中英双语问答的对话语言模型,ChatGLM-6B是使用了多达1T的tokens的训练数据,其知识和理解能力能够满足本次研究需要.
高效参数微调:预训练模型的引入也带来了新的挑战。例如,这些模型通常需要大量的训练数据和计算资源,这可能限制了它们在某些环境中的应用。目前的大模型微调技术解决了这个问题.Prompt Tuning、Prefix Tuning、P-Tuning v2和lora都是针对大型预训练语言模型的微调方法,通过引入额外的可训练参数来改善模型在特定任务上的性能,同时限制对原始模型结构的修改,使用较少的计算资源和较少的数据样本更高效地适应下游任务的问题.
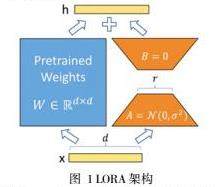
其中LoRA的特点是通过调整模型内部的权重矩阵进行微调,采用低秩适应(Low-Rank Adaptation)策略。优势:适用于需要微调权重但不希望重新训练整个模型的场景,增加了训练和推理的效率。
在LLaMA-6B模型的应用中,LoRA被用于每个transformer层的自注意力块的查询(query)和值(value)部分以及,注入旁路模块,以实现更有效的参数更新和训练。
2、知识增强技术
人类在做逻辑推理时其准确性取决于上下文信息和领域知识是否充分,同样机器的推理能力也取决于信息是否充分,因此我们通过利用大模型的上下文学习能力,将新的知识通过扩展查询Prompt的方式来进行知识增强。本文采用检索增强生成(Retrieval-Augmented Generation, RAG)技术来充分扩展模型的知识,有效地解决了模型的知识老化的时效性限制,即将大型语言模型(LLM)与未在LLM训练集中的数据结合使用。充分利用外部补充知识,从而保持系统的知识实时更新。
LlamaIndex 是一个将大语言模型和外部数据连接在一起的工具,为RAG提供良好了的基础组件。通过知识-向量数据库和查询-检索和组合提示模板-生成三个步骤,将最有效的信息提取出来与Prompt一起送给大模型,从而让大模型得到更多的信息。以下是基于RAG的方法来解决知识增强问题的具体步骤:
综上所述,ChatGLM-6b lora方法在结合知识增强技术后,在意图分类任务上展现出最佳性能,显著优于其他模型。这表明在处理复杂和长文本查询时,结合大型预训练模型和知识增强技术能显著提高搜索和对话系统意图分类的准确性和效率。
结论
本研究基于预训练大语言模型和领域知识增强技术,探讨了医疗查询意图分类的不同方法。研究结果显示,相较于传统基于规则的搜索技术,基于BERT、ChatGLM等大型预训练模型的方法在理解和分类用户搜索意图方面展现出显著优势。这些模型不仅减少了标注数据样本的需求,而且在处理复杂和长文本查询时表现更为出色,特别是在医疗领域的应用中,查询意图理解能力的显著提升。同时通过对医疗知识的查询扩展和输入知识的增强,解决了传统模型在识别新知识方面的局限,进一步提高了模型的时效性和准确性。这一点在实验数据中得到了验证,其中ChatGLM模型在结合LoRA微调技术和知识增强后,在意图分类的准确率上达到了0.9495,远高于传统方法。
本研究表明,通过结合大型预训练模型和领域知识增强技术,可以显著提高搜索引擎和对话系统在医疗查询意图分类方面的性能。此技术同样可以应用在专业领域知识库的智能问答上,未来有很大的发展前景.
参考文献
[1] Devlin J, Chang M-W, Lee K, Toutanova K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL]. arXiv, 2019, 1810.04805. https://arxiv.org/abs/1810.04805.
[2] Zeng, A., Sun, G., Li, S., & Liu, Y. (2023). GLM-130B: A Bilingual Open- Domain Pre-trained Model. arXiv preprint arXiv:2210.02414.
[3] Singhal, S., & Cardie, C. (2022). Retrieval-augmented language models for NLP: A survey. arXiv preprint arXiv:2202.01110.
[4] Hu, E., Shen, Y., Sun, G., & Liu, Y. (2021). Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
[5] Zhu, Wei, Xiaoling Wang, Huanran Zheng, Mosha Chen, and Buzhou Tang. "PromptCBLUE: A Chinese Prompt Tuning Benchmark for the Medical Domain." arXiv preprint arXiv:2310.14151 (2023).
[6] CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark (Zhang et al., ACL 2022)
[7] Sahu, Gaurav, Pau Rodriguez, Issam H. Laradji, Parmida Atighehchian, David Vazquez,Dzmitry Bahdanau. Data Augmentation for Intent Classification with Off-the-Shelf Large Language Models. arXiv, 2022.4.4.http://arxiv.org/abs/2204.01959.
[8] Gu, Yuxian, Xu Han, Zhiyuan Liu和Minlie Huang. 2022. PPT: Pre-Trained Prompt Tuning for Few-Shot Learning. arXiv. http://arxiv.org/abs/2109.04332.
作者:杨廷博研究方向:大数据与人工智能

 京公网安备 11011302003690号
京公网安备 11011302003690号


