



- 收藏
- 加入书签

基于德尔菲法-熵值法的甘肃省高校新基建档案管理成熟度指数(HEA-MMI)构建
摘要:为实现对高校新基建档案管理能力的科学评估,本研究提出高校新基建档案管理成熟度指数(Higher Education Archives Maturity Model Index, HEA- MMI)。通过德尔菲法-熵值法的组合权重模型,构建了包含 5 个一级指标、16 个二级指标的双层评价体系。选取甘肃省 12 所高校作为样本进行实证分析,结果表明:HEA-MMI 指数与高校产学研协同效能呈显著正相关,其中“技术融合度”为核心驱动因素。该指数为国家档案局制定分级分类管理政策提供了量化依据,也为高校档案管理数字化转型指明了路径。
关键词:新基建档案;成熟度指数;德尔菲法;熵值法;组合权重
1 引言
新基建自 2018 年 12 月在中央经济工作会议提出后不断演进,2020 年国家发改委细化其范围形成“3+7”框架,且在国际上形成竞争态势。[1]高校新基建档案记录校园新型基础设施全流程,涵盖智慧校园、科研、教育、绿色、安全与合规五类。然而,高校档案管理存在技术应用失衡、制度韧性不足、区域协同薄弱等关键问题,因此,构建适配新基建特征的档案管理评价体系迫在眉睫。
1.1 国内研究进展
新基建与档案管理融合研究:在《数字中国建设整体布局规划》推动下,高校档案管理的数字化转型与新基建形成协同发展态势。学界提出“数字孪生档案馆”概念,并形成了"物理实体-虚拟模型-交互机制"三层架构体系,通过 5G、BIM+GIS 技术实现档案库房全域感知与三维可视化建模,并依托区块链存证保障数据安全。[2]然而现有研究存在局限性:一是技术部署主要聚焦于 5G 网络覆盖等硬件设施,忽略了技术-制度协同机制;二是区块链存证系统虽验证了数据防篡改的有效性,但未量化技术融合度对管理能力的边际贡献;三是现有评价模型缺乏动态适配能力,难以应对联邦学习等新兴技术带来的合规风险。
成熟度模型本土化实践:国内学者在成熟度模型改造方面取得了阶段性成果:上海交通大学基于CMMI 模型构建了科研档案共享模型,但指标体系缺少“智能应用”维度;[3]武汉大学创新性地采用AHP-熵值法评估档案数据安全,但主客观权重冲突导致人才数字化素养等关键指标赋权失真。[4]
1.2 国外研究现状
国外研究呈现出两大特征:其一,美国 NARA 技术框架虽纳入新基建技术并设区块链存证覆盖率要求,设立了“云原生架构”“AI 辅助编研”等前沿指标,但政府导向与高校需求存在一定的指标适配偏差;[5]其二,欧盟数字遗产项目融合了德尔菲法与模糊综合评价法,但其静态权重机制难以适应技术迭代需求,动态调整滞后周期达 6-8 个月。此外,MIT 团队提出的技术适配度指数,虽量化了物联网等技术应用深度,但未涵盖中国特色产学研协同场景;[6]新加坡国立大学改进的熵值法模型,通过惩罚因子将高相关指标权重稀释度降低,为组合赋权提供了算法支持。[7]
2 HEA-MMI 指标体系设计
在高校新基建档案管理成熟度评估过程中,单纯依靠专家经验或数据统计都容易产生偏差。本研究将德尔菲法与熵值法按照 6:4 的比例进行融合,兼顾了专业判断与数据规律,具体流程如下:
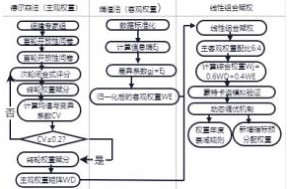
图 2 成熟度等级分布雷达图
2.1 专家确定
候选专家需同时满足专业背景、权威性和地域分布三个维度的要求。最终,专家组由 15 人组成,分为三个类别:高校档案管理者 6 人,主要解决跨校区协同治理的实际难题;新基建技术专家 5 人,核心诉求是推动区块链和数字孪生技术的实践应用;政策制定者 4 人,重点关注教育新基建评估体系的优化改进。
2.2 德尔菲问卷设计
2.2.1 问卷结构
问卷结构包含制度完备度、技术融合度、数据治理度、人才适配度、生态协同度五大模块。量表设计采用 Likert5 级量表评估指标重要性,并针对可操作性增设“数据获取难度”二级评分标准,其中 1 分表示数据不可获取,3 分表示需校方协助,5 分表示可直接提取。
2.2.2 指标筛选标准
专家认同度维度:筛选阈值为指标需获得专家组认同度≥80。例如,在首轮筛选中,“档案数字化率”仅获 52%专家支持率而被淘汰,专家组认为该指标已无法反映新基建环境下档案管理的核心需求,建议替换为“多模态档案智能识别准确率”。可量化性维度:筛选阈值为数据采集可行性评分≥4 分(5 分制)。例如,“区块链存证覆盖率”指标评分 4.7 分,因其可通过联盟链浏览器实时抓取节点数据而被保留;而“档案情感分析深度”指标评分 3.2 分,因依赖人工标注被暂缓纳入,需优化NLP 自动分析算法后复审。
政策相关性维度:筛选阈值为与国家标准《GB/T 37988-2019 信息安全技术 数据安全能力成熟度模型》匹配度≥70%。例如,将“隐私计算”与“数据安全”指标合并,形成复合指标“隐私增强技术合规应用率”。
2.3 指标池构建与筛选
2.3.1 初步指标池生成
指标池的选择主要来源于以下三个方面:政策文本方面,提取《GB/T 50328-2014》核心条款与配套政策,选取包括“区块链存证覆盖率”“动态更新机制成熟度”等 12 项;企业实践方面,选取华为“边缘节点部署密度”、商汤“联邦学习算法”等 9 项;学术研究方面,提取近三年CNKI 核心期刊与前沿课题的高频词“数据主权合规率”“跨域响应时效”等 11 项。
2.3.2 德尔菲法多轮筛选
第一轮开放式问卷阶段:提供政策原文(《GB/T 50328-2014》)、企业白皮书(华为/商汤)、学术文献库(CNKI 核心期刊 30 篇),要求专家自由提出指标,并标注来源类型。收集到 58 项指标,经合并去重后得到 32 项。第二轮闭合式评分阶段:采用 Likert5 分量表,对可量化性单独标注。计算均值与变异系数(CV),CV=(标准差/均值)*1
00% 。CV>30%的指标直接剔除;可量化性评分<3 分的指标合并。最终保留 20 项指标,淘汰率 37.5%。第三轮权重赋分阶段:专家对保留指标按 0-10 分赋分,强制正态分布(前 30%指标权重 ⩾0.8 ),同时达成共识标准:CV≤20%且均值≥4 分。
2.4 组合权重计算
2.4.1 德尔菲法主观权重计算
专家独立评分:邀请选定的专家针对特定的指标或问题,使用 1-9 标度法进行独立评分,其中 1 表示极不重要,9 表示极重要。计算均值与标准差:计算均值与标准差:对于每个指标,计算专家评分的均值(തx)和标准差ቀσቁ。均值的计算公式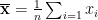 ,标准差的计算公式为:
,标准差的计算公式为: 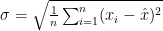 ,其中 n 是专家的数量,ݔ是第i个专家的评分。
,其中 n 是专家的数量,ݔ是第i个专家的评分。
剔除离群值:将评分落在均值±2σ范围之外的数据视为离群值,并将其剔除。
归一化处理,得主观权重矩阵:对于每个指标,将剔除离群值后的评分进行归一化处理,得到该指标的主观权重。归一化的计算公式为: 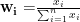 ,其中w是第i个指标的权重,ݔ 是第i个指标的评分。
,其中w是第i个指标的权重,ݔ 是第i个指标的评分。
2.4.2 熵值法客观权重计算
熵值法是一种基于信息熵理论的客观赋权方法,通过数据本身的离散程度确定指标权重。其核心思想是:指标数据越离散,熵值越小,信息是越大,权重越高。以下是具体步骤:
数据标准化:由于不同指标的量纲和数量级可能不同,首先需要对原始数据进行标准化处理,消除量纲的影响。常用的标准化方法包括:
正向指标(越大越好):
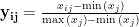
负向指标(越小越好):
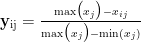
其中, xij? 第i个样本的第j个指标值, yijY 标准化后的值,若某指标所有数据相同,直接赋权重 0,跳过后续计算。计算比重୧୨:对标准化后的数据,计算每个样本值占该指标总值的比重:
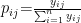 处理零值:
处理零值: 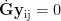 ,可替代为极小值,避免ln(0)无效计算。计算熵值E୨:利用信息熵公式计算各指标熵值:
,可替代为极小值,避免ln(0)无效计算。计算熵值E୨:利用信息熵公式计算各指标熵值:
其中,n 为样本数, 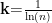 ,用于归一化,熵值范围: 0⩽Ej⩽1,Ej=1 :数据完全均匀,权重为 0; Ej=0 :数据极度集中,权重最高。
,用于归一化,熵值范围: 0⩽Ej⩽1,Ej=1 :数据完全均匀,权重为 0; Ej=0 :数据极度集中,权重最高。
计算差异系数݀ :熵值越小,差异系数越大,反映指标重要性: 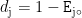 。确定权重ܹ:归一化差异系数,达到各指标权重:
。确定权重ܹ:归一化差异系数,达到各指标权重:
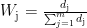
2.4.3 线性组合赋权
线性组合赋权是一种将主观权重和客观权重相结合的方法,通过设定一定的比例分配,实现对权重的综合调整。本文主客观权重按照 6:4 的比例进行组合,具体表达式为:
Wj=0.6WDj+0.4WEj
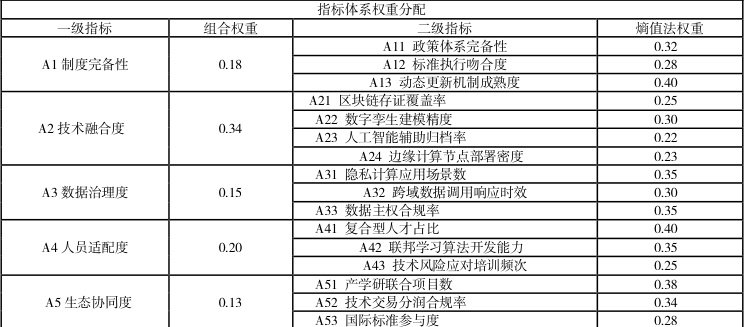
表 1 指标体系权重分配表
2.5 动态调优机制
建立动态调优机制,依据高校 MI指标体系和评估方法进行调整优化。采用权重年度衰减规则,对于一些随着 重 衰减,确保评估重点与发展需求相匹配。实施新增指标预分配,当出现新的档案管理 提前规划新增指标,并合理分配其权重,保证评估体系的前瞻性和适应性。
3 实证分析与等级划分
3.1 样本数据采集
本研究为确保样本的代表性和全面性,选取了 12 所甘肃省高校 2023 年的数据作为样本。评价体系给出了指标对应的详细评分细则,以产学研联合项目数为例:评分区间为 0-100 分,评分标准为每年开展 3 个以上产学研联合项目,且项目具有较高的创新性和影响力,可得 80-100 分;每年开展 1-2 个项目,有一定的合作成果,可得 60-79 分;每年未开展产学研联合项目,缺乏与高校和科研机构的合作,可得 0-59 分。
3.2 成熟度等级划分
运用 K-means 聚类分析方法,将 HEA-MMI 划分为5 个等级,样本数据具体情况用成熟度等级分布雷达图表示,如下图:
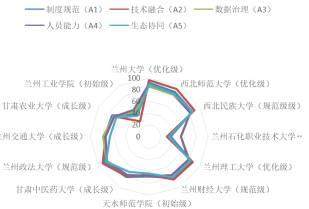
初始级:此阶段高校在档案管理方面制度严重缺失,技术应用率低,档案管理工作处于较为原始的状态,缺乏有效的规范和先进技术的支撑。成长级:高校开始进行局部试点工作,但数据孤岛现象仍然存在,不同部门或系统之间的数据难以实现有效共享和流通,限制了档案管理效率的提升。规范级:高校档案管理体系已较为健全,初步实现了跨域协同,不同领域之间的档案管理工作能够进行一定程度的协作和整合,提高了整体管理水平。优化级:以智能驱动为主要特征,技术交易贡献率超过平均水平,表明高校在档案管理中充分利用智能技术,通过技术交易等方式推动档案管理的创新和发展。卓越级:高校在档案管理领域具有生态引领作用,能够主导国际标准的制定,代表着高校档案管理的最高水平,在国际上具有较强的影响力。
4 管理启示与政策建议
4.1 高校改进路径
技术融合优先:高校应高度重视技术融合,积极部署区块链存证系统,增加其覆盖率,利用区块链的不可篡改、可追溯等特性,保障档案数据的安全性和真实性。同时,构建数字孪生档案库,通过数字孪生技术实现档案的虚拟映射和实时监控,提高档案管理的效率和准确性。
人才梯队建设:开设“档案+人工智能”双学位项目,培养既懂档案管理又掌握人工智能技术的复合型人才,大力提高复合型人才占比,为高校档案管理的智能化发展提供人才支撑。生态协同深化:高校应加强与头部企业的合作,共建联邦学习实验室,提高联合项目合作率。通过与企业的合作,实现资源共享、优势互补,共同推动高校档案管理的创新和发展。
4.2 政策制定建议
分级扶持策略:对于初始级高校,政府协助建立基础管理制度框架,提供技术培训,解决制度缺失问题。成长级高校,应设立专项基金完善数字基础设施,推动数据标准化以打破信息孤岛。规范级高校需搭建跨域协同平台,组织经验交流活动,深化档案整合与资源共享。优化级高校需设立技术创新奖励基金,建立技术交易服务平台,提升智能技术应用水平。卓越级高校要积极参与国际标准制定,推动国际学术合作,强化生态引领作用。
监测机制:首先建设 HEA-MMI 数据库,按季度更新成熟度雷达图,及时掌握高校档案管理成熟度的动态变化,为政策制定和高校改进提供数据支持,同时设立“红黄蓝”预警机制,对连续两年降级的高校启动整改督导,促使高校重视档案管理工作,不断提升管理水平。
5 结论与展望
HEA-MMI 指数成功填补了新基建档案管理量化评估工具的空白,其组合权重模型在 12 所高校的实证研究中展现出良好的效度,能够较为准确地评估高校档案管理的成熟度。
未来的研究方向主要包括:引入量子计算优化权重算法,利用量子计算的强大计算能力,提升模型的抗干扰能力和计算精度;拓展评估对象至省内全部高校与职业院校,构建全域评价网络,使评估结果更具全面性和代表性,为不同类型高校的档案管理提供更有针对性的指导。
参考文献:
]国家发改委:首次明确“新基建”范围[J].通用机械,2020(5):10.
[2]任远坤.数学视角下档案工作绩效评估指标体系建构与量化分析[J].山西档案,2024(11).
[3]胡水星等.我国高校大数据治理能力成熟度模型的构建与实践—基于 CMM 与 ISM 融合研究的视角[J].远程教育杂志,2024,42(04).
[4]吴倩.孪生档案馆:基于数字孪生的新型档案服务模式[J].北京档案.2022(04).
[5]美国国家档案与记录管理局.《联邦 RIM 计划成熟度模型用户指南》分析报告[EB/OL]. (2023-08-15)[2025-01-03].https: //www.archives.gov/files/records-mgmt/prmd/maturity-model-user-guide.pdf.MIT Technology Evaluation Lab.(2023).Technology Rea diness Assessment:A Quantitative Framework. MIT Press.Boyd S.《Distributed Optimization and Statistical Learning via ADMM》, 2023.
作者简介:(1979.6-),汉族,硕士研究生,副研究馆员工作单位:档案馆研究方向:档案信息化、路易·艾黎档案研究项目:2024 年度兰州市哲学社会科学规划项目(24-B56)

 京公网安备 11011302003690号
京公网安备 11011302003690号


