



- 收藏
- 加入书签

基于多指标融合的NIPT时点选择优化及胎儿异常判定模型
摘要:NIPT(无创产前检测)是一种通过采集母体血液,检测胎儿的游离 DNA 片段,分析胎儿染色体是否存在异常的产前检测技术,其准确性受孕妇孕周、BMI 等多种因素影响。本文是在通过用数学建模的方法,研究胎儿 Y 染色体浓度与孕妇指标的关系,确定最佳 NIPT 检测时点,并构建女胎异常判定模型,以达到降低临床风险的目的。
关键词:NIPT 时点优化、胎儿异常判定、分类模型、决策树算法
一、问题重述
1.1背景描述
出生缺陷是影响人口素质和家庭幸福的重大公共卫生问题,染色体浓度异常会导致唐氏综合征、爱德华氏综合征和帕陶氏综合征等常见先天性遗传疾病。传统产前筛查和诊断方法存在准确率低或有流产风险的两难困境[1]。
无创产前检测(NIPT)[2]技术是产前筛查领域的革命性突破,其原理基于1997年卢煜明发现的cffDNA,即孕妇外周血中存在胎儿游离DNA。通过高通量测序技术对DNA片段测序,经生物信息学分析计算特定染色体相对剂量[3],可无创评估胎儿患染色体非整倍体疾病的风险。与传统方法相比,NIPT对T21的检出率和特异性均显著提高,还避免了流产风险,因此被广泛应用于临床[4]。
1.2、问题的提出
本题要求参赛者基于某地区孕妇NIPT数据建立数学模型,研究并解决以下四个问题:
问题一:相关性分析与建模
分析胎儿Y染色体浓度(列V)与孕妇孕周数(列J)、身体质量指数BMI(列K)等指标的相关关系,建立描述此关系的数学模型(如回归模型),并利用统计方法(如p值、R²)检验和说明模型显著性。
问题二:基于BMI分组的男胎最佳检测时点选择
临床显示男胎孕妇的BMI是影响胎儿Y染色体浓度最早达标(≥4%)时间的主要因素。要求:(1)对男胎孕妇的BMI合理分组并给出每组区间;(2)确定每组最佳NIPT检测时点(孕周),以最小化孕妇潜在风险;(3)分析检测误差(如测序失败、浓度波动)对分组和时点选择结果的影响。
问题三:多因素影响下的分组与检测时点优化
综合考虑孕妇体重(E)、年龄(C)等多因素、检测误差及胎儿Y染色体浓度达标比例,重新对男胎孕妇分组。要求:(1)给出更精细化的合理分组方案;(2)确定每组最佳NIPT检测时点,目标仍是最小化孕妇潜在风险;(3)分析检测误差对优化结果的影响。
问题四:女胎染色体异常的判定方法构建
针对女胎(Y染色体浓度为空白)的异常判定问题,要求:(1)以女胎21号、18号和13号染色体非整倍体(AB列)判定结果为基准;(2)综合考虑X染色体的Z值(T)、13/18/21号染色体的Z值(Q,R,S)、GC含量(X,Y,Z)、读段数(L,O)及相关比例、BMI(K)等多因素;(3)构建有效数学模型或判定方法,准确判别女胎是否存在染色体异常。
二、问题分析
2.1问题一的分析:胎儿Y染色体浓度与孕周、BMI的关系分析
该问题要求摸清胎儿Y染色体浓度与孕妇怀孕周数、胖瘦程度(BMI)的关系,核心是从复杂线索中找出直接关联模式。首先,整理分析手头数据,挑出怀XY染色体的孕妇。接着,借助散点图直观查看浓度随孕周和BMI的变化规律,同时尝试用数学公式描述这种变化,即描述在特定孕周和胖瘦程度时浓度的大致数值。最后,用统计方法检验该规律是否可靠,是否为数据巧合造成的假象。
2.2问题二的分析:基于BMI分组找最佳检测时间
临床观察表明,孕妇胖瘦决定男宝宝Y染色体浓度达4%的时间。目的是按胖瘦分组,如偏瘦、标准、偏胖等,使每组情况相近。对于每个小组,要找出合适的抽血检查时间点,该时间点需平衡两方面风险:抽血太早浓度不够,抽血太晚后续处理时间稀缺。
2.3问题三的分析:多因素影响下的更精细分组
问题2仅考虑胖瘦(BMI),但实际宝宝Y浓度达标时间与孕妇身高、体重、年龄等多因素有关。问题3要求综合考虑这些因素,进行更精细、个性化的分组。分组后,和问题2一样,为每个组找出最稳妥的抽血时间,确保此时抽血多数人浓度达标,以降低孕妇整体风险。
三、模型假设
为保证模型科学性与可行性,基于对题目理解和实际数据分析,提出以下假设:
1.认为题目附件数据真实可靠、有统计意义,数据中的缺失值等可通过清洗与预处理有效处理,不影响模型整体有效性。
2.模型聚焦与NIPT检测准确性及胎儿异常判定最相关的核心变量,如孕妇孕周等,忽略其他次要因素干扰。
3.认同题目中潜在风险与孕周关系的界定,以最小化孕妇高及极高风险为核心目标之一。
4.采用题目给出的NIPT准确性黄金标准,该标准是模型定义“检测达标”和“胎儿异常”的基石。
5.依据孕妇BMI、年龄等指标分组合理可行,可为组内确定统一、最优的NIPT检测时点。
6.假设胎儿Y染色体浓度与孕周等变量存在可量化函数关系,检测随机误差服从正态分布,便于模型检验和误差分析。
7.对于多次检测样本,每次检测结果在给定真实生理状态下视为相互独立,或取均值作为该孕周代表值。
四、模型的建立与求解
5.1问题一模型建立与求解
5.1.1模型的选择和理由
探究胎儿Y染色体浓度与孕妇孕周、BMI的关系时,因涉及多个自变量(孕周、BMI)对因变量(Y染色体浓度)的线性影响,且要量化各因素单独及交互作用,所以选择多元线性回归模型。该模型能呈现自变量与因变量的线性关联,通过系数估计与显著性检验,可明确各因素对Y染色体浓度的影响程度及统计学意义,为临床NIPT(无创产前检测)时点选择提供理论依据。
5.1.2多元线性回归模型原理
多元线性回归模型原理在于描述多个自变量与一个因变量之间的线性关系,其一般形式为:
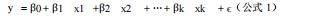
其中:y为因变量(胎儿Y染色体浓度);X1,X2,…,XK为自变量(孕周GA、BMI等)
β0为截距项;β1、β2、βk为自变量的回归系数,反映对应自变量对因变量的影响程度ϵ为随机误差项,服从均值为0、方差为σ2的正态分布
(1)变量定义与拓展
针对本研究,我们不仅考虑孕周GA和BMI的单独作用,同时还引入两者的交互项GA*BMI,以捕捉孕周与BMI对Y染色体浓度的联合影响。此时模型形式为:
(2)参数估计与检验
Yconc=β0+β1 GA+β2 BMI+β3(GA×BMT)+ϵ(公式2)
采用普通最小二乘法(OLS)对模型参数进行估计,通过最小化残差平方和来确定最优回归系数。同时,进行以下统计检验:
系数显著性检验(t检验):检验每个回归系数是否显著不为0,即判断对应自变量对因变量是否存在显著线性影响。
检验统计量为:
(公式3)其中,SE()为回归系数的标准误差。
模型整体显著性检验(F检验):
检验模型中所有自变量的回归系数是否同时为0,即判断模型整体线性关系是否显著。检验统计量为:

拟合优度检验(R2):衡量模型对数据的解释能力,R2=(SSR为回归平方和SST为总平方和),R2越接近1,模型拟合效果越好。
5.2问题二的模型建立和求解
5.2.1模型的建立
在无创产前检测(NIPT)中,男胎检测最佳时点选择对检测准确性和时效性至关重要。本次研究基于1082条原始数据,筛选后得1069条有效样本,围绕数据质量、BMI分组、最佳检测时点及检测误差等方面分析。
5.2.2数据质量与基础特征
(1)数据筛选情况:原始数据1082条均为男胎样本,经异常值剔除(孕周10-25周、BMI 18-50kg/m²、Y染色体浓度>0),有效样本1069条,样本保留率98.8%,数据完整性好,为后续分析提供可靠支撑。
(2)关键指标分布:孕周均值16.73周,中位数16周,集中在13.29-20周,覆盖孕中期核心检测窗口,无极端异常值;孕妇BMI均值32.29kg/m²,中位数31.84kg/m²,整体偏肥胖且存在明显分层,为后续BMI分组分析提供依据;Y染色体浓度均值0.077,中位数0.075,达标阈值(0.04)以下样本占比极低,多数样本检测浓度满足临床要求。
5.2.3 BMI分组特征:
借助KMeans聚类(依据轮廓系数最优原则),将孕妇BMI分为2组,分组特征清晰且有显著临床差异,如下表所示
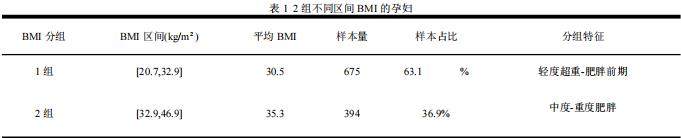
从分组结果看,肥胖样本占比高,2组(BMI≥32.9 kg/m²)样本占比近37%,最高BMI达46.88 kg/m²,表明目标人群中肥胖孕妇占比显著,需针对性优化检测策略。同时,两组以32.9 kg/m²为分界,无重叠区间,组内BMI标准差小(整体2.96),分组有效性高,可作临床分层管理依据。
5.3问题三模型的建立和求解
因无创产前检测(NIPT)涉及孕周、孕妇BMI等多维度指标,且各指标与Y染色体浓度关系复杂,为精准优化检测时点,构建多指标融合的NIPT检测时点优化模型解决。
5.3.1模型的建立
为精准优化检测时点,构建多指标融合的NIPT检测时点优化模型。
(一)指标选取与预处理
选取孕周、孕妇BMI等为核心影响指标,筛选原始数据,保留男胎样本,剔除异常值,得有效样本集1069条,同时统一孕周格式为连续数值,为后续分析奠基。
(二)多因素关系与分组建模
1.多因素关系建模:采用广义可加模型(GAM)捕捉各指标与Y染色体浓度的非线性关系。
2.BMI分组建模:为探究不同BMI孕妇的检测时点差异,用K-Means聚类算法对孕妇BMI分组,通过肘部法则和轮廓系数法确定最优聚类数为2,最终将孕妇BMI分为2组(分组结果见表1)。

从不同BMI分组的样本分布(图5)可看出,分组0主要集中在28-34 kg/m²,分组1集中在34-38 kg/m²,分组边界清晰,符合临床对肥胖程度的分层逻辑。
5.3.2模型求解
(一)最佳检测时点求解
对每个BMI分组,基于广义可加模型生成10-25周(步长0.5周)的Y染色体浓度预测值。定义达标条件为Y染色体浓度≥0.04,结合风险函数(孕周<12周,风险权重0.5;12≤孕周≤20周,风险权重1.0;孕周>20周,风险权重1.5),按公式Risk=(1-达标率)×风险权重计算各孕周风险值,找出最小风险值对应的孕周作为该BMI分组最佳检测时点。从BMI分组1风险曲线(图4)可知,分组1最佳检测时点为14周,风险值最小,为0.3655;从各BMI分组风险曲线(图5)及计算结果(表2)看,两组最佳检测时点均为10周,最小风险值为0,这可能是模型设定或数据特性导致的理想情况,实际临床需结合更多因素验证该时点普适性。

图6 Y染色体浓度分布

图7检测误差对各BMI分组达标率的影响

图8各BMI分组风险曲线

图9 BMI分组1风险曲线

图10不同BMI分组的样本分布

图11肘部法则与轮廓系数
表3最佳检测时点结果

(二)检测误差分析求解
模拟服从正态分布的检测误差,对各BMI分组在最佳检测时点(10周)的样本进行1000次误差模拟。计算无误差达标率、误差后平均达标率、达标率的标准差和95%置信区间。以分组0为例(表3),无误差达标率100%,模拟误差后平均达标率98.26%,标准差0.0402,95%置信区间为(0.9,1.0)。从检测误差对各BMI分组达标率的影响(图2)可见,误差后平均达标率虽有下降,但整体仍处较高水平,表明检测方法抗误差能力较强。
表4检测误差分析结果(分组0)

参考文献
[1]田彦捷,武会娟,钱嘉林.我国非整倍体产前筛查及诊断方法的研究新进展[J].中国妇幼保健,2014,29(26):4351-4353.
[2]赫一山.卢煜明:无创产检之父[J].创新世界周刊,2024,(04):56-57+6.
[3]Chiu RW K,Chan K C A,Gao Y,et al.Noninvasive prenatal diagnosis of fetal
chromosomal aneuploidy by massively parallel genomic sequencing of DNA in maternal plasma[J].Proceedings of the National Academy of
Sciences,2008,105(51):20458-20463.
[4]Gil M M,Accurti V,Santacruz B,et al.Analysis of cell-free DNA in maternal blood in screening for aneuploidies:updated meta-analysis[J].Ultrasound in Obstetrics&Gynecology,2017,50(3):302-314.

 京公网安备 11011302003690号
京公网安备 11011302003690号


