



- 收藏
- 加入书签

浅析大数据下的精准招商的数据采集与处理系统设计研究
 打开文本图片集
打开文本图片集


摘要:基于Python语言以及PyQt工具包设计开发了面向大数据精准招商的数据采集与处理系统,主要由数据采集、数据处理、数据存储、数据应用四部分组成。其中,数据采集部分主要实现企业基础数据定期增量采集与用户查询的目标企业、行业媒体数据的实时采集。数据处理部分,分别对采集的网页数据进行信息提取、数据清洗、话题提取。数据应用部分,为招商人员提供查询功能,将招商政策中的招商条件转化为行业、企业性质、注册资本等搜索条件,帮助快速锁定目标企业,以及对行业前沿资讯、目标企业动态信息的查询展示,同时为业务人员深入挖掘提供重要数据支撑。
关键词:大数据,招商引资,网络爬虫,数据处理
一、系统开发环境
硬件环境:CPUIntel(R)Core(TM)i5-1035G1CPU@1.00GHz、内存8G、硬盘1TB。软件环境:编程语言采用Python3.6、开发工具为Pycharm、数据库选用关系型数据库MySQL以及本地创建的数据库、数据可视化创建GUI应用程序的工具包PyQt5。算法环境:Tensorflow1.14+keras2.3.1+ Bert4keras0.9.7。Tensorflow是一个深度学习框架、Keras是一个基于Tensorflow的高级API,Bert4keras是一个基于keras的预训练模型加载框架,目前支持多种预训练模型如Bert等。Bert预训练模型选用针对中文预料的大规模预训练模型Bert-base-Chinese,具有12个多头自注意力层,每层有12个头,中间向量维度为768,参数量有110M。
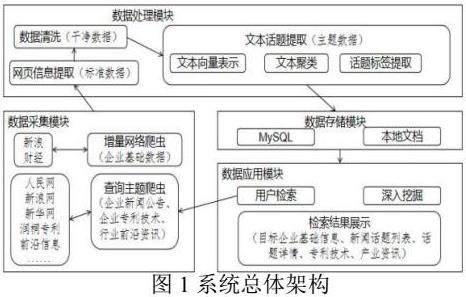
二、系统总体架构
面向大数据精准招商的数据采集与处理系统分为四个层次,分别为数据采集层、数据处理层、数据存储层、数据应用层。其总体架构如图1所示。
本系统数据来源于互联网数据开发网站,包括新浪财经网、人民网、新华网、3158招商、U88加盟网、润桐专利、佰腾专利网、前沿信息网等。数据采集层主要完成面向大数据精准招商的数据采集工作,包括采用增量网络爬虫技术的企业基础数据采集、基于查询的主题爬虫的企业新闻公告、企业专利技术、行业前沿资讯采集。数据处理层主要对采集的网页源码HTML结构数进行信息提取,数据清洗、新闻文本聚类话题提取。数据存储主要包括MySQL存储及本地磁盘存储两种方式。最后系统采集与处理后得到数据进行应用,为用户提供数据查询与数据展示以及为技术人员数据挖掘提供数据支撑。
系统工程结构。ZS_DML为根目录文件,VIEW文件实现系统与用户交互模块,login.py实现用户登录功能,view.py实现界面展示功能,main.py为主体程序,根据用户行为触发各模块功能。数据采集由collect目录下多类型程序文件实现,数据清洗由clear.py程序文件实现。clusting目录文件夹下,LDA.py实现LDA模型训练,Bert_whitening.py实现bert文本向量映射求值,LW_Bert.py实现最终的文本向量表示,single_pass.py完成文本聚类与话题提取。database目录文件夹下,mysql.py负责MySQL数据库创建,同时该文件夹下保存预加载Bert模型信息。
三、模块设计与实现
3.1数据釆集
数据采集包括两种方式,基于增量网络爬虫的静态数据采集和基于查询主题爬虫的动态数据采集。其具体的设计与实现如下。
(1)基于增量网络爬虫的静态数据采集
企业基础数据来源于新浪财经网的公司资料界面,要采集的权威站点队列构成为“http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpInfo/ stockid/+企业编码+.phtml",企业编码采用6位数编制方法,分别由前三位的证券类别加后三位的顺序编号组成,如圆通速递公司代码为600233、中证金融企业代码为000934,证券类别编码如表1所示。
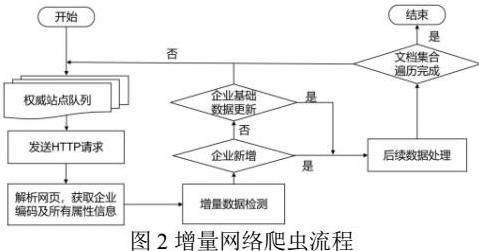
基于增量网络爬虫的企业基础数据采集的具体流程如图2所示,从权威站点队列中获取待爬取链接,模拟客户端发送HTTP请求,获取服务器端响应后网页,主要通过requests.get方法实现。再利用BeautifUlsoup(html,'lxml')方法解析当前网页,通过find_all、find、get、获取当前采集页面企业编码及所有属性信息。增量数据检测主要通过set集合去重,更新数据主要判别MD5值,data转MD5方法主要利用hashlib库中md5(data)实现。如果是新增企业则爬取web页面,如果不是新增企业,判别页面内容是否有新增,如果有新增,继续后续的数据处理,如果无新增,继续爬取下一链接,直至权威站点队列为空。
(2)基于查询的主题爬虫的多源异构数据采集
该模块收集了多个主流媒体网站,具体情况如表2所示。表中网址链接为初始链接,通过招商用户关键词在当前网站查询跳转结果,得到的链接为详情链接。
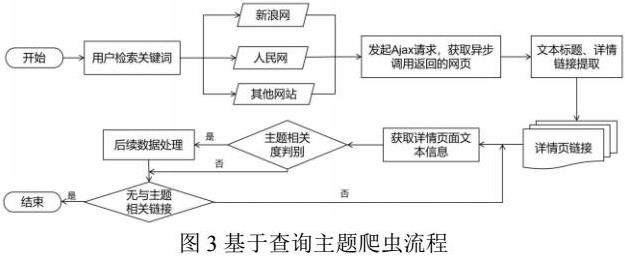
基于查询的主题爬虫的企业新闻公告、专利技术、行业前沿信息釆集的具体流程如图3所示,用户检索关键词被传递到各网站查询接口,页面跳转到查询结果页面,进行文本标题、详情链接提取,获得详情页链接队列,获取详情页面文本信息,主题相关度判别。如果主题相关进行后续数据处理,如果不相关继续读取下一详情链接,直到队列无与主题相关链接,停止爬取。
3.2数据处理
(1)网页信息提取
1)基于Beautifulsoup的页面信息提取
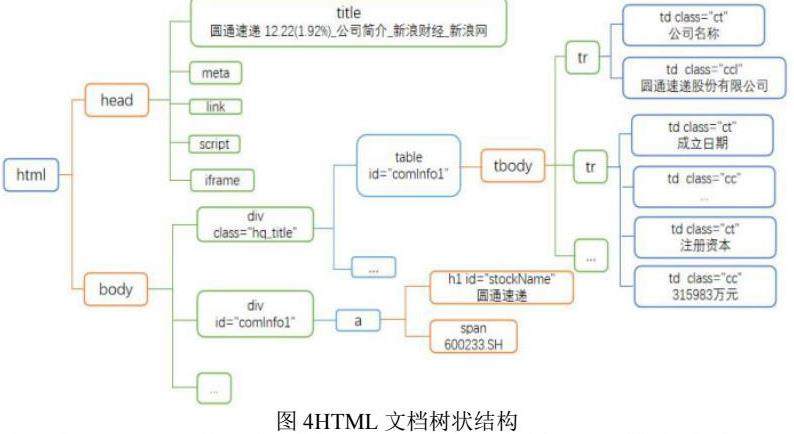
页面具有一定规律时,采用Beautifulsoup方法进行页面信息提取,如企业基础信息。以企业基础信息为例,通过网页源码分析,企业基础信息页面具有相同的网页编码规则,网页的HTML文档树状结构如图4所示,公司简称及注册码在id="stockName”属性下的hl标签下,其余基础信息皆在id="comlnfo1”属性的table标签下由多个tr和td元素组成。
首先对获取的目标网页HTML编码格式转换,将所有内容统一转为UTF-8格式;其次创建Beautifulsoup对象,并将转码后的响应内容以参数形式传给该对象;再分别用find、find_all方法对Beautifulsoup对象的内容进行解析,找到id="stockName”的h1标签下的内容,将其提取出来作为当前企业的简称及其编码;其次将id="comlnfo1”的table标签下的内容提取出来,并按照<tr>进行分块处理,并分别取每块内容中<td>标签中的内容作为企业其他基础信息属性及其对应结果。
2)带权行块分布函数网页正文提取
通过网络爬虫爬取下来的文本网页数据带有噪声信息,需要进行正文提取。第三章中文本提到了现有的网页正文提取算法的不足,并提出了改进的带权行块分布函数网页正文提取算法,为了尽可能多的收集数据,本系统采集了多源权威网站。因来源于多网站,采集过来的网页HTML编码各不相同,使得正则表达式,BeautifulSoup方法不再适用。现有的一些基于密度统计的网页正文提取算法会使一些文字密度较长的噪声被当做正文内容给抽取出来,以及段落间隔较大的文本内容抽取不完整,严重影响正文抽取的通用性和准确性。因此在第三章中提出了改进的带权行块分布函数网页正文提取算法。首先进行源码重构再去除格式标签,等纯文本内容。随后定位正文起始位置,计算行文本与标题文本关联度值作为加权值,加权行块文字密度,构建带权行块分布函数图,找到图中密度峰值,定位正文区间获取正文。
(2)数据清洗
1)数据去重
在爬虫采集到的原始数据中,可能存在内容相同的语料,因此在网页信息提取后,对数据进行去重处理。主要以详情链接作为依据,将冗余语料进行删除处理。
2)特殊符号去除
从网页提取出来的信息尤其是文本数据,可能存在特殊符号,“一>”,“<em>”等,通过匹配搜索的方式予以剔除。
3)统一编码处理
常见的编码格式有用于表述英文文字编码的ASCII、汉字编码的GB2312/GBK/GB18030、国际标准化组织统一的编码准则Unicode以及它的轻量化UTF-8。
爬取下来的数据可能因为编码格式不同存在乱码的问题。解决该问题首先对编码格式进行识别,采用第三方库charset的detect方法来判别字节数据的编码格式。判别其编码格式后再对其解码为Unicode数据,最后使用统一UTF-8进行统一编码。
(3)文本话题提取
1)文本话题提取流程
主要对采集的新闻文本数据进行聚类话题提取处理,旨在将相同话题的新闻文本内容整合到同一主题下,帮助招商人员梳理杂乱信息,快速锁定重点。首先对文档进行向量表示,提取文档关键词作为文本特征,加载LDA、Bert向量表示,Bert向量进行Bert-whitening处理,融合后得到最后的文本向量表示。随后进行文本聚类,计算文档d与已有话题相似度sim划分文档d所属话题类,汇总聚类结果。遍历各话题簇标题,提取各簇最优标题作为话题标签,文本话题提取结束。
2)文本特征词提取
新闻文本包含大量噪声特征,如“的”、“是”等冗余修饰的词。为了防止噪声数据的干扰,选择特征词提取做为文本向量模型的输入。在新闻文本中,时间、地点、人物等要素在内的命名实体可以很好地区分新闻内容,因此选用命名实体作为文本的特征词。对输入的每一篇新闻文本分别采用Jieba进行分词和词性标注。
3)模型配置
LDA模型训练主题数目的确定,选用总文档量的数目的10%,该主题数目并非最后文本聚类结果主题数目,其主要目的是通过LDA模型训练学习各文本主题概率分布之间的相似性。各参数设置learning_method选择'batch',算法迭代次数max_iter设为10。
Bert模型配置文件包括vocab.txt字典文件,用于做ID的映射,bert_config.json配置文件,bert_model.ckpt用来保存预训练模型。Bert模型加载调用bert4keras框架中的build_transformer_model方法。
3.3数据存储
(1)企业基础信息存储
企业基础信息存储到MySQL中,便于用户查询。企业基础信息数据库表字段包括公司简称、企业注册码、公司名称、注册资本、成立日期、公司电话、公司电子邮箱、公司地址、公司简介、经营范围、公司网址、组织形式、所属板块、指纹编码。其中企业注册码为主键,作为唯一标识。
(2)企业新闻与行业前沿资讯存储
企业新闻与行业前沿资讯采用本地文件存储,同一企业或行业的文本数据在同一文件夹下,同一话题下的文本内容存储与同一文档。文档中的每一篇报道存储格式为[标题+\t+链接+\t+文本内容+\n]。
(3)企业专利技术信息存储
企业专利技术信息同样采用本地文件存储,存储于专利文件夹下,同一企业专利技术信息存储与同一文档。文档中的每一篇报道存储格式为[专利名+\t+公开号+\t+简介+\t+专利类别+\t+相关链接+\n]。
总结:采用融合LDA和Bert-whitening的文本表示方法,强化文本向量的语义表达。通过Bert-whitening技术对预训练的Bert文本向量线性变换,改善了Bert文本向量的嵌入空间在语义上不平滑表现。以及融合LDA主题模型,增强特定领域信息。最后将融合LDA和Bert-whitening的文本表示方式引入Single-Pass动态话题中心聚类方法,加强聚类过程中文本向量的语义表达,有效提升文本相似度计算与聚类的准确性,进而增强招商大数据话题提取的精确度。
参考文献:
[1]江如茜.基于DOM树的网页正文信息抽取的研究与实现[D].长沙:中南民族大学,2019.
[2]孙景春.基于视觉块识别的网页元数据提取方法[D].南京:东南大学,2017.

 京公网安备 11011302003690号
京公网安备 11011302003690号


