



- 收藏
- 加入书签

基于多源数据融合的心理健康知识图谱框架构建研究
 打开文本图片集
打开文本图片集
摘要:随着人工智能技术的飞速发展,构建医疗领域的知识图谱成为智慧医疗的研究热点。同时抑郁症、强迫症等心理疾病的发病率逐年呈现低龄化趋势,已经成为亟待解决的严重的公共卫生问题。本文阐述一种基于多源数据融合的心理健康知识图谱构建方法,选取3个不同源头数据动态整合构建心理健康知识语料库增加可信度。通过信息抽取、知识融合、知识存储等步骤最终实现心理健康知识图谱可视化。
关键词:知识图谱;心理健康;多源数据融合;可视化
中图分类号:TP391.5 文献标识码:A
Abstract:With the rapid development of artificial intelligence technology,building a Knowledge Graph in the medical field has become a research hotspot in wisdom medical. At the same time,the incidence rate of depression,obsessive-compulsive disorder and other psychological diseases is showing a trend of younger age year by year,which has become a serious public health problem to be solved urgently. This paper describes a method of constructing mental health Knowledge Graph based on multi-source data fusion,and selects three different sources of data to dynamically integrate and construct a mental health knowledge corpus to increase credibility. Through Information extraction,knowledge fusion,knowledge storage and other steps,the Knowledge Graph of mental health is finally visualized.
Key words:Knowledge Graph;Mental Health;Multisource Data Fusion;Visualization
引言
近年来,随着人工智能技术的飞速发展,自然语言处理和数据挖掘技术已经被广泛应用到各个领域的大数据语料库自动构建和非结构化数据处理。2012年,谷歌公司首次提出了知识图谱(Knowledge Graph,简称KG)的概念。此后知识图谱日益成为大数据领域研究的热门话题,国外已陆续出现了面向医疗健康领域的知识图谱。目前构建完成的医疗领域的知识图谱普遍具有数据量巨大、研发投入高、信息量全等优势,但部分知识图谱在实际应用过程中存在数据源单一,说服力不高,操作繁琐等缺点。同时目前国内针对心理健康知识领域的精细图谱比较匮乏。本文尝试利用自然语言处理和数据挖掘技术构建基于多源数据融合的心理健康知识图谱,旨在能够实现对人们进行心理健康知识普适性教育,同时可以帮助心理疾病患者及家属实现自我诊断和病情监测和辅助医生临床做出决策等。
1 研究背景
1.1 心理疾病
常见的心理疾病主要包括抑郁症、焦虑症、恐惧症、强迫症等。近些年,由于社会竞争激烈导致人们生活压力的增大和受新冠疫情的影响,全世界各地各种心理疾病的发病率呈现直线上升趋势。以抑郁症为例,据2020年世界卫生组织(WHO)披露数据显示,抑郁症已成为世界第二大疾病(仅次于癌症),全球有超过3.5亿人患抑郁症,近十年来患者增速约18%,每年大约有100万人因为抑郁症自杀。同时抑郁症等心理疾病的发病率逐年呈现低龄化趋势,已经成为亟待解决的严重的公共卫生问题。
而与之对应的是目前多数人们对心理健康知识知之甚少,主要表现在:(1)对“心理健康”问题存在羞耻感,认为心理有问题的人就是精神不正常表现。(2)缺乏心理疾病常识,无法根据临床表现正确分辨自身及他人罹患的心理疾病类型。(3)忽视心理疾病带来的危害,普遍认为心理疾病并不需要专业的治疗,仅靠自我排解就能解决问题,最终导致病情恶化甚至危及生命。
1.2 知识图谱
知识图谱是现实世界中根据实体间关系相互连接起来所形成的一种网络结构,用于呈现各类实体以及实体间的关联关系。利用将自然语言处理和数据挖掘技术将半结构化、非结构化的数据整合成知识图谱可以帮助机器完成某一知识领域大数据的快速分析和简化表示,最终实现智慧搜索与智能交互。目前知识图谱已经广泛应用在银行、保险、证券、医疗、物流等领域。构建完整的知识图谱主要包含数据获取(原始语料库构建)、信息抽取、知识融合和知识存储和可视化等步骤。
由于心理疾病在临床上存在症状多、复杂性高、易误诊和类型鉴别困难等特点,所以构建心理健康知识图谱如果仅采用单一数据源的话不具备较强说服力和有效力。本文构建的心理健康知识图谱原始语料库数据来源除了包括医学权威书籍、科研论文外,还从浩瀚的互联网中获取有价值的相关数据信息。采用多源数据融合方式进行数据获取,对心理健康知识图谱构建及可视化研究具备重要启发意义。
2 心理健康知识图谱构建过程
2.1知识图谱构建体系架构
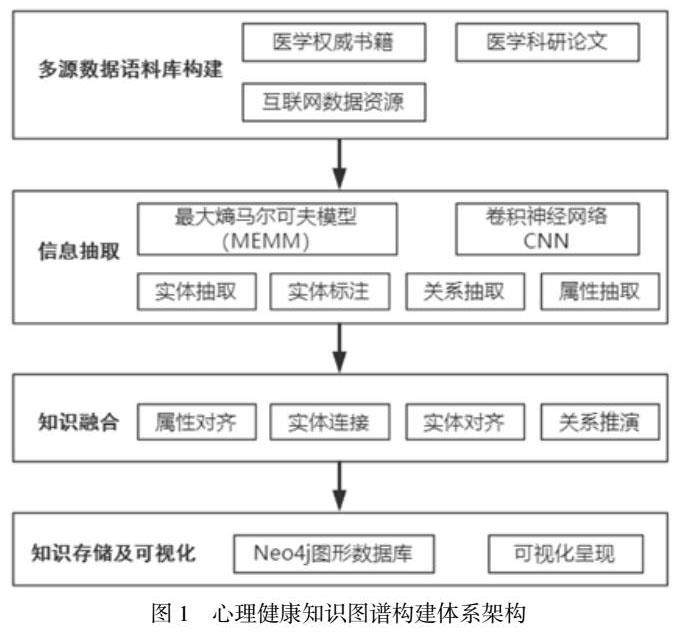
心理健康知识图谱构建体系架构如图1所示,主要包含多源数据语料库构建、信息抽取、知识融合、知识存储及可视化这几个步骤。关键核心技术是通过信息抽取、知识融合等技术从归一化后的多源数据语料库中抽取其中的实体、属性等关键知识及其关系,最终以三元组的形式存储于图数据库中。
2.2多源数据语料库构建
多源数据语料库构建也叫做知识获取/数据获取阶段,是后续完成构建心理健康知识图谱的基础。显然选择采用多源数据构建的语料库显然比单一数据源可靠、准确。所以本文选取3个不同源头数据来整合构建心理健康知识语料库,数据具体来源包括(a)医学权威书籍。(b)医学科研论文。(c)互联网数据资源。
其中医学权威书籍选用张明教授主编的《临床心理学》(科学出版社出版,ISBN:9787030256256)作为处理书籍。该书籍内容权威可靠、表述规范,重点处理书中第4章节《心理障碍的分类及其表现》内容。该章节详细阐述了常见的心理疾病的分类及表现特征,包括抑郁症、焦虑症、强迫症、恐慌障碍等。作为公开出版的书籍无疑是具备较强的权威性和可靠公信力。
根据CNKI检索“心理疾病”、“心理健康知识”等关键词显示,CNKI收录的知识图谱相关中英文学术期刊文献已经达到了1.1万篇。选取医学权威领域的北大核心期刊论文50篇作为“医学科研论文”数据源。医学科研论文同样作为公开发表的资料经过严格审核检验,同公开出版的书籍一样具备较强的可信度。本文将这“医学权威书籍”和“医学科研论文”这两个数据来源作为心理健康知识语料库的主干来源。
浩瀚的互联网同样存在心理健康知识相关的海量数据资源,比如常见的百度百科、百度知道等有针对心理疾病知识的科普和问答,同时国内领先的互联网医疗平台比如好大夫在线、妙手医生等网站存在大量的真实心理疾病患者诊疗问答数据、科普文章等。我们借助目前成熟的网络爬虫技术动态获取互联网上已存在的大量心理健康知识相关数据,但是通过互联网获取的海量数据资源,相比较于(a)(b)两种数据源可能存在不精准、垃圾数据多等问题。所以,互联网数据资源可以作为心理健康知识语料库的动态补充数据。
2.3 信息抽取
由于前期构建的情感障碍症知识语料库由于数据来源不一、数据不规则,初步得到的大部分数据并不是结构化数据,而是大量纯文本非结构化数据集。所以在信息抽取阶段采用基于最大熵马尔可夫模型和卷积神经网络的自然语言处理算法(MEMM-CNN)从半结构化和非结构化数据中抽取出可用的知识单元,完成实体抽取、实体标注、关系抽取和属性抽取等过程。
其中实体抽取是从原始文本数据集中提取出命名实体,比如心理疾病类型、临床症状、治疗对策等。实体标注是自动标注实体有效性、完整性、出现频次等附加信息。通过实体抽取和实体标注这两个步骤形成心理健康知识实体库。关系抽取是进一步提取心理健康知识实体库中各个实体的关联关系,通过将多种零散的实体连接起来,从而形成关联的网状知识结构。属性抽取是抽取实体的属性信息构造实体的属性列表,比如治疗抑郁症药物的注意事项、不良反应和禁忌等。通过进一步的关系抽取和属性抽取最终形成三元组关系表,从而完成信息抽取过程。
2.4 知识融合
前期构建的情感障碍症知识语料库的数据来源有3个,所以在数据源整合过程中不可避免的会出现数据知识重复、冗余、歧义、关联性冲突等问题,尤其是从互联网上爬取的数据文本甚至充斥着部分错误信息。需要从实体对齐、实体连接、实体对齐、关系推演等方面进行知识融合,完成多源数据整合、加工、消歧、推理验证、更新等操作。
(1)属性对齐
由于数据来源的多样性,数据存在知识重复、心理健康知识之间的联系不够、多元指代等问题。属性对齐首先判断多源异构数据中的实体是否指向真实世界同一对象。
(2)实体连接
实体连接是指实体对象连接到知识库中对应的正确对象的操作。实体链接的基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。
(3)实体对齐
实体对齐主要用于消除实体冲突、实体命名多元指代问等问题。例如常用来治理抑郁症的药物盐酸帕罗西汀片,其别名和通用名还包括赛乐特、乐友、舒坦罗、Paroxetine等,但其实都是指代同一种药物,这时候就需要实体对齐消除实体名称指代冲突。
(3)关系推演
关系推演是将从最新的数据文本中获取的实体关系及时填充到构建的知识库中,有助于提高心理健康知识库的时效性。通过完成属性对齐、实体连接、实体对齐、关系推演等步骤实现知识融合过程。
2.5 知识存储及可视化
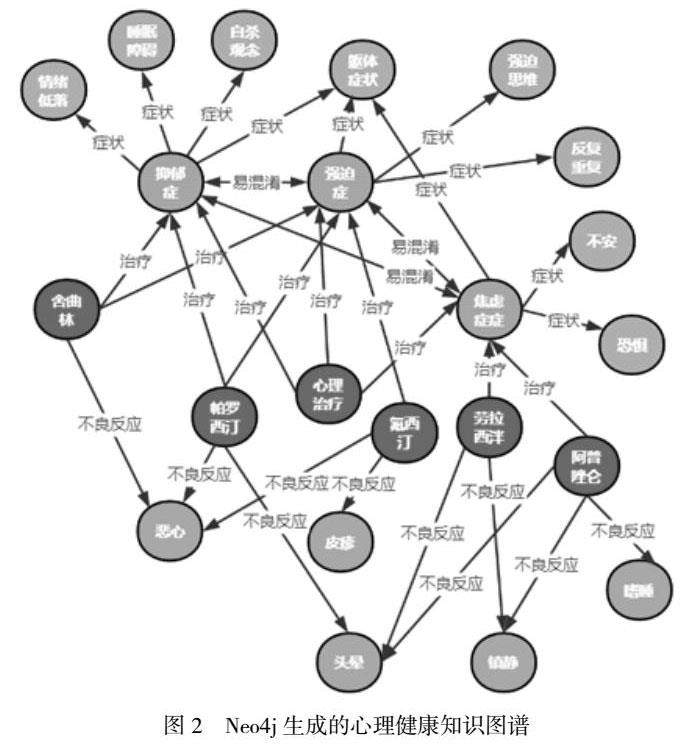
通过借鉴中文医学知识图谱CMe KG2.0知识存储方式,采用开源图形数据库Neo4j作为底层的存储结构。Neo4j 是由 Java 和 Scala 语言写成 NoSql 数据库,也是目前使用较多的图形数据库。通过 Neo4j可以直观呈现实体间的各种关系,能够最终实现心理健康知识图谱可视化。
经过上述技术,共得到1025条三元关系组,部分知识图谱如图2所示。图中每个圆圈代表1个实体,各个实体之间以关系形式连接。其中关系包括症状、治疗、不良反应、易混淆等。
3 结语
本文提出了一种基于多源数据融合的心理健康知识图谱构建方法,并详细阐述了多源数据语料库构建、信息抽取、知识融合、知识存储及可视化等步骤。构建的心理健康知识图谱不仅能够对人们进行心理健康知识普适性教育,同时可以帮助心理疾病患者及家属实现自我诊断和病情监测,以及辅助医生临床做出决策,具备较强的应用价值。
参考文献:
[1]段宏. 知识图谱构建技术综述[J]. 计算机研究与发展(03).
[2]赵雪娇.妇产科知识图谱构建研究与实现[J].中国数字医学,2019,14(1):3.DOI:CNKI:SUN:YISZ.0.2019-01-003.
[3]昝红英,窦华溢,贾玉祥,等.基于多来源文本的中文医学知识图谱的构建[J].郑州大学学报:理学版,2020,52(2):7.DOI:10.13705/j.issn.1671-6841.2019383.
[4]韩普,马健,张嘉明,等.基于多数据源融合的医疗知识图谱框架构建研究[J].现代情报,2019,39(6):10.DOI:10.3969/j.issn.1008-0821.2019.06.009.
[5]刘桂锋,郭科远,包翔.基于多源数据融合的新冠肺炎病例活动知识图谱构建与知识发现研究[J].情报工程,2023,9(1):16.
[6]Liran J,Wang Y,Jiang J,et al. Evaluating Individual Genome Similarity with a Topic Model[J]. Bioinformatics,2020.
[7]Yang B,Liao Y M .Research on enterprise risk knowledge graph based on multi-source data fusion[J].Neural Computing and Applications,2021:1-14.DOI:10.1007/s00521-021-05985-w.
作者简介:汪洋(1991-),男,河南信阳人,硕士,讲师,主要研究方向:人工智能、软件技术。
雷开(2002-),男,四川内江人,泸州职业技术学院2021级在读学生,主要研究方向:数据分析、智能算法。
※基金项目:2021年泸州市科技计划项目《多源数据融合情感障碍症知识图谱构建关键技术研究》(课题编号:2021-JYJ-96);数据智能分析与处理泸州市重点实验室2022年开放基金课题《基于多源数据融合的心理健康知识图谱构建与应用研究》(课题编号:SZ202207)。
(作者单位:1.泸州职业技术学院;2.数据智能分析与处理泸州市重点实验室)

 京公网安备 11011302003690号
京公网安备 11011302003690号


