



- 收藏
- 加入书签

烟草数字门店分布合理性优化与数据质量控制
——数字门店选点分布测算模型与数据质量检测预警模型应用
 打开文本图片集
打开文本图片集




摘要:数字门店的分布与结构决定了是否能够准确还原整体终端网络的市场状态,而数字门店数据质量的好坏直接影响商业企业的数据分析应用结果。前者为数据代表性要求,后者为数据准确性要求,皆为商业企业数字门店建设的关键环节。本文运用R语言,建立数字门店选择与分布测算模型,数字门店数据质量评价模型及门店扫码数据质量预警反馈模型,通过模型算法测试和挑选出最优备选数字门店,保证数字门店合理分布,并对数字门店的数据质量进行检测预警,为优化数字门店功能提供科学依据,以支撑后期数字门店数据的深度挖掘。
关键词:数字门店;代表性拟合度;分布地图;数据质量;预警
Abstract: The distribution and structure of digital stores determine whether the market status of the overall terminal network can be accurately restored, and the quality of digital store data directly affects the data analysis and application results of commercial enterprises. The former is a data representativeness requirement, and the latter is a data accuracy requirement, which is a key link in the construction of digital stores of commercial enterprises. This paper uses R language to establish a digital store selection and distribution calculation model, a digital store data quality evaluation model and a store scan code data quality early warning feedback model, test and select the best alternative digital stores through the model algorithm, ensure the reasonable distribution of digital stores, and detect and warn the data quality of digital stores, so as to provide a scientific basis for optimizing the function of digital stores to support the in-depth mining of digital store operation data in the later stage.
Key words: digital stores; representative fit; distribution map; data quality; Early warning
为了推动行业数字门店建设的标准化、规范化,全面提升运行质效,发挥数字门店的示范引领作用和市场信息触点作用,建立科学的数字门店选点机制和数据质量控制机制就尤为重要。
本文构建1套烟草数字门店选择和分布测算模型,旨在实现数字门店选点工作的标准化操作,完成从“怎么选”到“选得好”的转变。同时,为建设一个长期稳定、可靠运行的烟草数字终端体系,本文针对数字门店的“数据质量”评价和监测,建立1套数字门店数据质量评价模型和1套数字门店扫码数据质量预警反馈模型,既能确保所采集门店数据的质量能支撑后续数据分析的正确性,又希望通过对门店运营异常现象进行实时监测,将数据异常的门店清单和异常类型及时反馈给烟草公司对口管理部门进行处置。在日常监测的同时,还能以周、月、季、年为周期,定期生成数据质量综合评价报告,让烟草公司精准、全面掌控数字终端体系的建设效果,不断优化完善。
1 备选数字门店计算生成
对于需要新增数字门店的需求,建立了针对卷烟销量段分类、卷烟单条值分类、门店商圈类型、门店所属区县分公司(市场部)4个客户信息字段和门店经纬度坐标的算法模型。导入标准格式客户信息后,在满足正态分布的前提下,模型能按照所需新增数字门店数量要求快速挑选出合适的备选数字门店,同时能满足反映市场状况的要求。
1.1 相关变量
a. 客户信息:销量段分类、单条值分类、商圈类型、区县分公司(市场部)
b. 从客户地址与地图位置所计算获得的门店经纬度坐标
1.2 计算过程
a. 根据门店的经纬度坐标,利用Haversine公式,计算任意非数字门店到数字门店的距离,形成一个距离矩阵(distance matrix),再利用这个距离矩阵来对非数字门店进行排序,目的是让备选门店的地理分布尽可能均匀,以保证后续基于经营特征所抽样的门店,在地理分布上能够尽可能均匀,更好的反映市场整体状况。
b. 指定备选门店的数量(本期预计新增的数字门店数量);分别根据数据集里“销量段分类、单条值分类、商圈类型、市场部”四个字段里的细分分类的实际比例,计算每个分类里所需要抽样的样本数。
c. 针对前述计算出来的比例,并依照前述所指定的备选门店数量,对非数字门店的所有样本进行基于正态分布的“加权”随机抽样。随机抽样的加权基础是在前述a里面所计算出来的距离矩阵,在相同条件下,和现有数字门店距离远的非数字门店优先进入抽样,以获得比较均匀的地理分布。
d. 对抽样结果进行Kolmogorov-Smirnov正态分布检验,以验证针对备选门店的抽样,确实满足正态分布,实际上就是在比较我们所观察的样本累积密度函数F,和KS统计量G之间的差,公式如下:
假如D非常小,则表示F和G之间非常相似,也就是说,F满足KS统计量的正态分布。
2 现有数字门店可视化分布
对于已建成的数字终端体系,根据所有门店信息,生成可视化分布地图,并自动测算现有数字门店统计分布上的相似性(越相似表示越有代表性,将来越能用来正确预测市场销售状况)。
2.1 涉及数据集和包含字段
a. 现有数字门店信息
b. 所有零售客户信息
2.2 相关变量
a. 数字门店名单:客户编码、两次MD5加密后的编码(为了与销售数据一致,称为“烟草证号”)
b. 客户信息:客户编码、两次MD5加密后的编码(为了与销售数据一致,称为“烟草证号”)、修改后地址。
2.3 计算过程
a. 利用“烟草证号”在“客户信息”里匹配出属于数字化门店的样本,并建立一个新字段“数字门店”,归并入“客户信息”,0代表非数字门店,1代表数字门店。
b. 申请“高德开放平台”账号,取出“客户信息”里的“修改后地址”,利用平台所提供的API,通过高德开放平台里的经纬坐标数据库将地址转换为经纬坐标。
c. 设地球表面A点经纬坐标为(λ,Φ),对应的投影坐标为(x,y),基准纬线设置为赤道,则R为地球半径,利用Mercator Projection 函数:
即可求得地图上地球表面投影到平面上的微积线段,并针对数字门店和非数字门店,以不同颜色绘出门店位置。
3 选点分布测算模型应用成果
3.1 选点方式
应用分层随机抽样为核心模型,所选择的分层包括:销量段分类、单条值分类、商圈类型、所属区县分公司,目标是:a.让被推荐的备选数字门店在成为数字门店后,通过所采集的数据,能正确反映市场实际销售状况。b.所推荐门店尽可能在地理位置上均匀分布,能更好的反映市场状况。
3.2 选点过程
3.3 分布测算
2022年绵阳烟草数字门店828户的分布拟合测算,可以看出“销量段分类”分布拟合(78.69%)略低,需逐步优化;“单条值分类”分布拟合(100%)、“商圈类型”分布拟合(98.01%m)、“区县分公司”分布拟合(100%)均达到标准。
3.4 分布地图
绵阳烟草现有数字门店(红色)、备选数字门店(蓝色)可视化门店分布地图(截图)。
4 数据质量评价模型的构建与应用
4.1 数据质量评价模型的构建
在排除因为数据库导出数据发生的错误,以及可能导因于数据库或系统本身的错误后,数字门店的数据质量评价指标主要由两类因素构成:(1)数据录入错误;(2)门店违规操作导致的数据质量问题。以下分别说明阐述这两类问题的识别和评判方法。
4.1.1 数据录入错误
(1)相关变量
主要检查终端销售数据里的录入错误,这些错误来自于:a.在数字类型字段里录入了字符串(例如部分门店在购买数量里录入的是“3包”);b.在字符串字段里录入了不属于该字段应有的内容(例如在单位字段里录入“斤”,但是品规字段显示是“包烟”);c.异常值(例如购买数量小于或等于0;销售价格小于2元)。
(2)计算方法
以终端销售数据里的“烟草证号”为键值,计算每家门店出现前述四种类型错误的次数,形成四个新的变量:数字字段错误、单位字段错误、购买数量错误、销售价格错误,然后利用基于“k-means”方法的“聚类分析”对所有数字门店计算“输入错误得分”并进行门店分群。
k-means的计算步骤如下:
(1)选择初始化的k个样本作为初始聚类中心,a=a1,a2,...ak;
(2)针对数据集中每个样本xi计算它到k个聚类中心的距离,并将其分到距离最小的聚类中心所对应的类中;
(3)针对每个类别,重新计算它的聚类中心(即属于该类的所有样本的均值);
(4)重复上面2和3两步骤,直到达到某个中止条件(迭代次数、最小误差变化等)。
基于“k-means”的聚类分析方法需要事先指定聚类数,为了精准且自动化地确定最合适的聚类数,我们采用的方法是Husson和Pages(2010)所提出的PCA算法,也就是数据维降算法。
数据维降算法的计算步骤如下:
(1)均值归一化:计算出所有特征的均值,然后令;
(2)计算协方差矩阵(covariance matrix):
(3)求解平均均方误差与训练集方差的比例:
(4)得出降维方程:
4.1.2 门店违规操作
(1)相关变量
本模型涉及的变量有终端销售数据里的6个变量:1)烟草证号;2)时间;3)订单号;4)购买数量;5)实际销售价格;6)利润。
(2)计算方法
1)实际销售价格和利润两个字段经过清洗和归并(以每条10标准包的比例,重新计算正确的金额)后,重新建立为两个变量:“交易金额”和“交易利润”;
2)基于“订单号”字段,生成每家门店每小时的订单数量;
3)基于“订单号”字段,归并出每家门店基于“订单”的销售记录(而不是扫码的交易记录);
4)基于“时间”字段,生成每家门店,每天从1到24小时的“交易时间”数据集,没有交易的时间段数值为0,有交易的时间保持原本的销售数量、交易金额、交易利润、订单数;
5)引用Cowell(2000)提出的Gini系数算法,计算每家门店每天基于24小时销售交易的交易集中度。Gini系数原本是用来计算在一个固定样本范围内所得分配集中度的(例如贫富不均的程度,也就是财富的集中度),在零售场景上同样适用。24小时销售的交易时间是固定样本范围,而在交易时间里的销售数量、交易金额、交易利润、和订单数就如同计算Gini系数时用到的国民所得。
Gini系数的公式如下:
6)由于Gini系数是一种集中指数,而我们想获得的是均匀指数,所以定义均匀指数=1-Gini系数,换句话说,在24小时内,交易分布越均匀,得分越高;
7)利用前述c基于“订单”的销售记录,加上“时间”字段,寻找所有门店“在20秒之内成交5笔或以上”的交易次数,正常而言,人类很难在20秒内成交5笔交易,所以假如出现这样的情形,可以判定存在“违规操作”的嫌疑。依此计算每一家门店出现这类型“过快交易”的次数x,然后用max(x)-xi形成新变量“合理交易密度”,数值越大代表越少出现这种“过快交易”的情形。
8)依据前述计算出来的销售数量、交易金额、交易利润、订单数均匀度分布,以及g所计算出来的“合理交易密度”得分,采用基于kmean和PCA的聚类分析方法,对所有数字门店进行潜在“违规操作”的聚类分析,得到“合规指数”,数值越高代表门店的运营管理越合规,并据此对门店样本进行分群。
4.2 数据质量评价模型的应用成果
数据质量评价指标由“输入干净度(检查数据录入错误)”、“交易分布集中度(检查基于每天24小时的交易分布是否均匀)”和“合理交易密度(检查是否存在“高密度扫码”)”三者组成,其中后两个评价指标均属于“时均分布”检查,需通过计算检验来判定哪一个更加适用于绵阳烟草实际。
4.2.1 输入干净度
检查了绵阳烟草828户数字门店每家门店“数字字段错误数”、“单位字段错误数”、“购买数量异常值”、“销售价格异常值”四个指标,进行基于k-means的聚类分析,获得四组在“输入干净度”上表现存在明显差异的门店,分别是“优秀门店(样本数10)”、“次佳门店(样本数165)”、“错误次多门店(样本数303)”、“错误最多门店(350)”,模型解释能力为71.1%(45.6%+25.5%)。通过“均方根标准化”计算这四者的联合得分,并生成基于html5+css3的网页可视化雷达图(图1)。
从雷达图可以看出来,不论哪组门店,都存在比较高的“单位”字段错误问题,也就是说,在收银录入数据时不规范,明明是卷烟类产品,应该录入“包”或“条”这样的单位,但是却出现了例如“斤”或“瓶”这样的单位,这可能和门店人员专业性以及人员训练有关,需要追踪并予以改善。表现不佳的门店在“数量”、“价格”方面存在比较明显的异常值,例如卷烟价格出现小于2元,甚至为负数的情形;购买数量出现为0或是负数的情形;反之,表现好的门店在这些方面呈现出比较认真的态度。当然,在零售实践上这有可能是因为顾客退货而需要冲账所导致的情形,但是假如次数太多,就需要改善。表2是2021年6月1日到2022年9月30日的出错数量,显示“数字类型”的字段和“单位”字段的出错数都相当大。
4.2.2 时均分布
时均分布是指门店每天24小时营业时间内的交易分布,包括销售数量、交易金额和订单数,计算时均分布的目的就是用来判别门店是否存在违规操作的嫌疑。
我们使用了两种方式来检查门店交易的“时均分布”。
(1)第一种方式是检查每家数字门店的每天“营业时数”、“销售数量均匀度”、“交易金额均匀度”、“订单量均匀度”四个指标,并借以计算出“均匀指数”以及在时均分布上的“得分”(得分采用线性差补法,数值介于0到100分,最优结果为100分,最差结果为0分,以下皆是如此,兹不赘叙)。采用的均匀度计算方法是Gini系数。然后基于上述这些计算结果来进行基于kmeans的聚类分析,获得五组在“时均分布”上表现存在明显差异的门店,分别是:“优秀门店”、“次佳门店”、“一般门店”、“次不均匀门店”和“最不均匀门店”。
(2)第二种检查是否存在违规操作的方式是计算所有门店“在20秒之内成交5笔或以上”的交易次数,假如出现这样的情形,可以判定存在“违规操作”的嫌疑。依此计算每一家门店出现这类型“过快交易”的次数x,然后用max(x)-xi 形成新变量“合理交易密度”,再通过标准正态化计算满分为100分的得分,得分越高代表越少出现这种“过快交易”的情形。
第一种检查方式的结果如下:
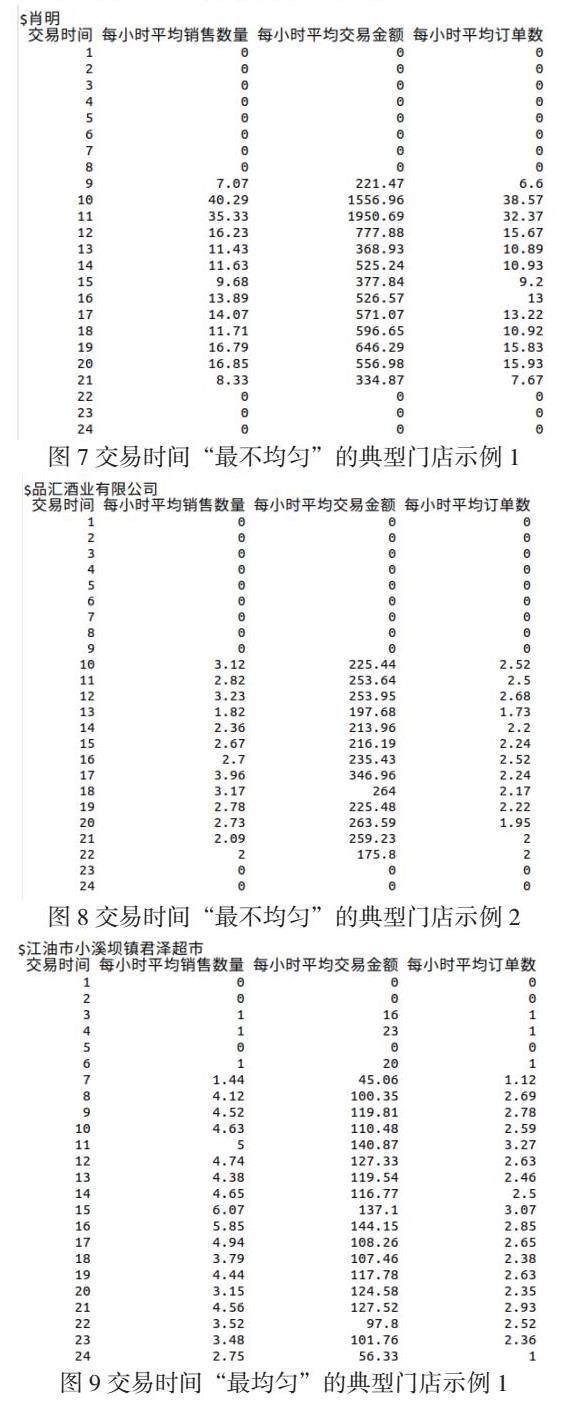
尽管聚类分析模型的解释能力极高(达到96.3%),并不能断定这样子“交易时均分布”的均匀度一定能正确反映“集中扫码”的违规操作情形。原因是,可能某些门店的规模较大,营业时间也较久(例如靠近24小时营业),那么很可能交易分布会分散些,导致交易均匀度比起别家门店更好;反之,可能存在某些门店的位置特殊(例如位于存在营业时间限制的商场),导致可营业时间受到局限,就可能导致交易分布变得集中,使得交易均匀度变差(集中在某些时间内出现尖峰交易)。
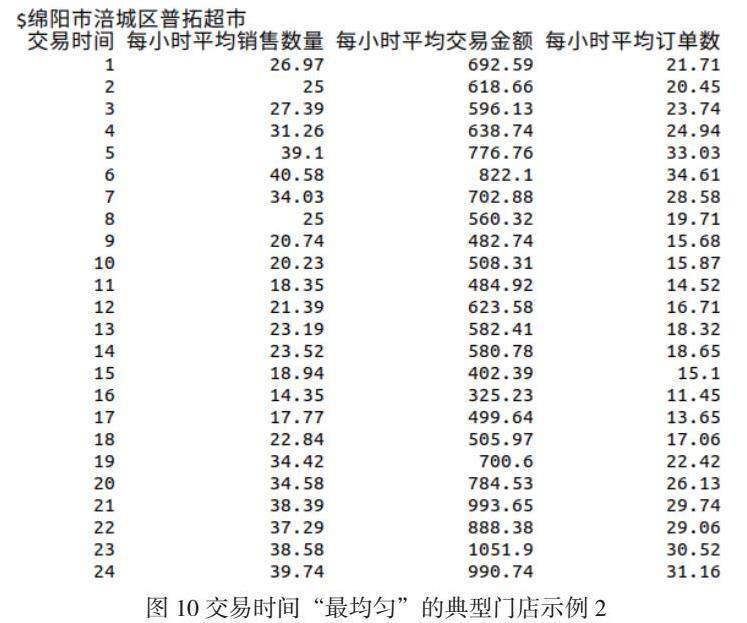
为了验证“营业时间”对交易均匀度的影响,我们选择落入交易时间“最不均匀”和“最均匀”的若干典型门店进行比较观察,如下图所示,发现“交易时均分布”的均匀度并不能很好的反映“集中扫码”的违规操作情形。原因和前述猜想吻合。
由此可见,每天24小时内的交易数量分布并不是恰当的用来检查门店是否存在“违规操作”的理想指标。我们的结论是,目前,基本上所有的数字门店都已经放弃了这种违规操作的方式了(非数字门店的问题较为严重)。因此,我们接下来将检查指标放到“过快交易(合理交易密度)”。
第二种检查方式检查结果如下:
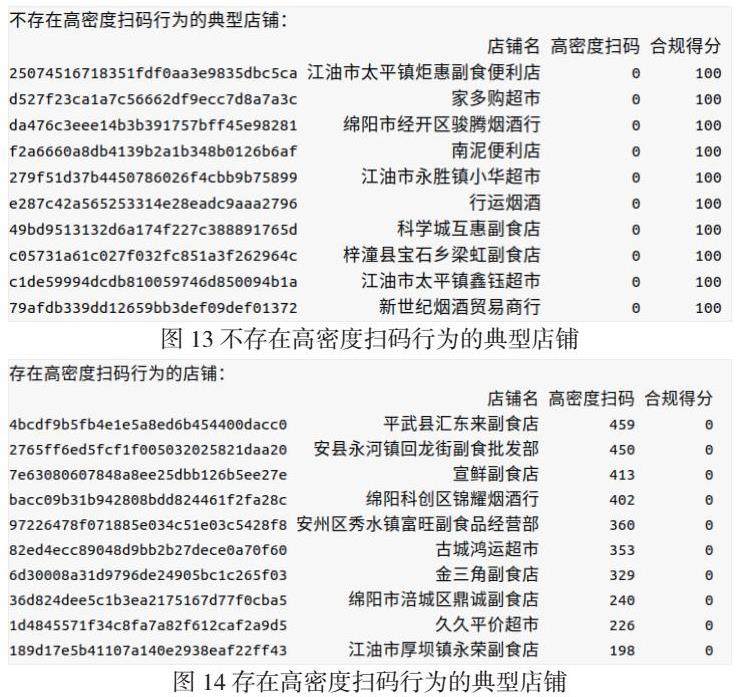
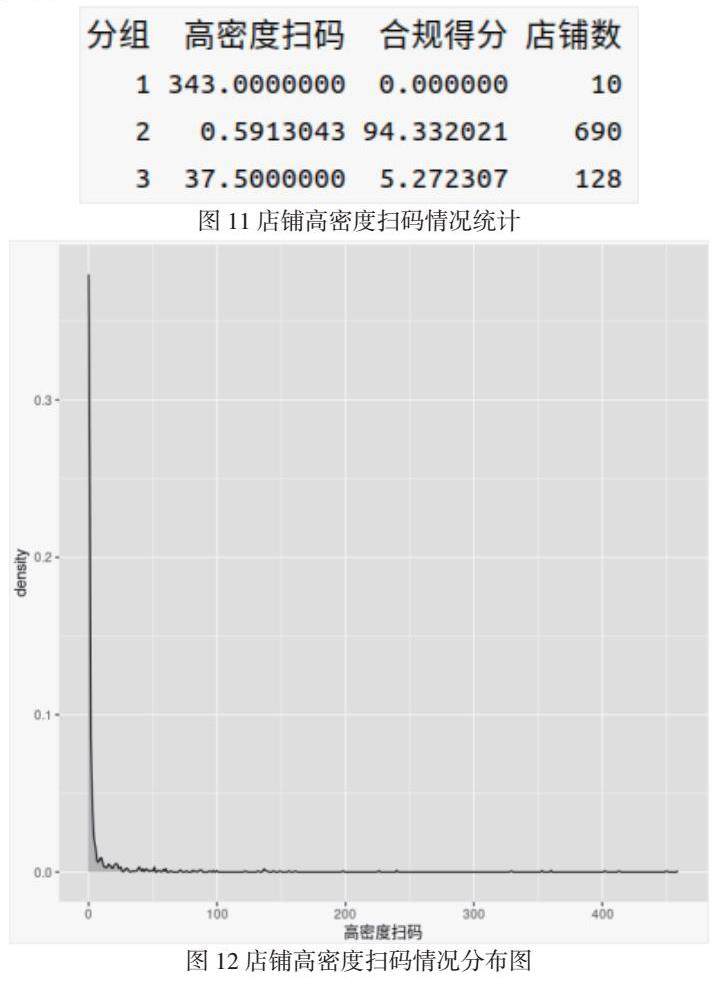
我们对于“高密度扫码”的定义是“在20秒内扫码超过5单”,这里的“单”,是根据“订单号”归并之后的一单交易,并不是单纯的一次扫码交易。一般零售门店的成交频次大概率不可能在20秒内成交5笔交易,所以在某个程度内应该足以判定门店“违规操作”的嫌疑。整体而言,绝大多数门店都少有这种“高密度扫码”的行为,仅有极少部分门店出现了这种现象。为了防止“误杀”,我们选出合规得分为100分的和0分的门店分别进行检查,结果如下:
图12中的10家门店因为出现了“高密度扫码”现象(20秒内成交5单以上,数字为2021-06-01直到2022-09-30的出现次数),所以可能存在“违规扫码”行为。
基于上述检验计算,我们认为以绵阳烟草当前数字门店交易数据情况,“合理交易密度”作为数据质量时均分布的检验指标,比“交易集中度”指标更加适用。
5 扫码数据质量预警反馈模型的构建与应用
基于前述建立的数据质量模型,进一步建模:
(1)采集最近一周的门店数据,进行自动化“聚类分析”,针对明显存在“数据录入错误”的门店列出清单,并显示出现录入错误的字段;
(2)采集最近一周的门店数据,进行自动化“聚类分析”,针对明显存在“违规操作”的门店列出清单,并提示违规操作的类型;
(3)对烟草数字门店进行合理选择后,采集最近一个月、一季的数据进行同类分析,并进行预警。
对于“数据录入错误”的预警模型暂时是没法建立的,原因是所有的建模都是基于已经做完“数据清洗”之后的数据才能进行的。
5.1 营业异常门店的侦测
针对烟草公司实际需求,建立了一套能用来侦测各种门店异常状态的函数库,这些函数可以通过命令方式直接执行,也可以内嵌在基于html+css3+JavaScript结构的网页里自动化执行。
函数:check_open()
输入:无
目的:找出已经歇业的门店(日期可以根据所拥有的数据自动进行调整)。
方法:数据集条件搜寻。
示例:
5.2 时均交易的均匀度分布
函数:check_wktime(days)
输入:日数(输入7代表一周,输入30代表往前倒数一个月,依此类推)
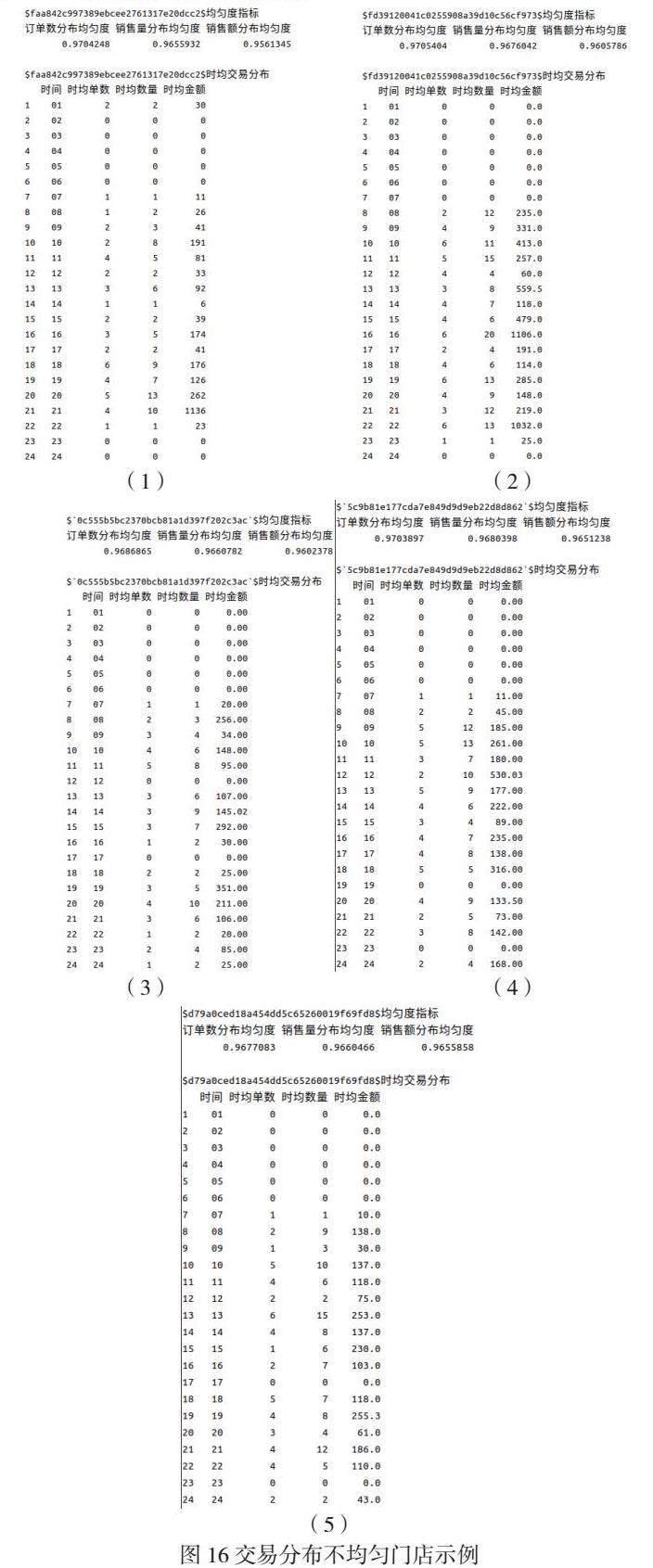
目的:观察一天24小时里交易分布最不均匀的门店,原始目的是寻找可能违规操作的门店(在一天里特定时间段违规集中扫码),虽然目前绵阳烟草数字门店基本上已经不出现这类违规情形了,还是可以作为监控交易均匀度的工具。
方法:数据集条件搜寻+Grubbs异常值检验。
示例:最近一周的交易均匀度检验,自动检测出5家交易分布比较不均匀的门店,如图16所示。
5.3 检查频繁交易
函数:check_rush(days)
输入:日数(输入7代表一周,输入30代表往前倒数一个月,依此类推)
目的:根据“高密度扫码”来判定门店是否存在“违规操作”的嫌疑。频繁交易的定义是“在20秒内扫码超过5笔订单”,系统自动从数据集里取出当时的交易证据作为参考。
方法:数据集条件搜寻+“高密度扫码”算法。
示例:最近一周的频繁交易检验,自动检测出2家需要进一步观察了解的门店。
6 不足与展望
绵阳烟草初期数字门店选点的标准更多立足于客户意愿和规范经营等基础条件,易于操作、扩点较快,但不利于数字门店的长期发展与管理,也为后期的数据还原应用增添了难度。本文通过建立烟草数字门店选择和分布测算模型,解决数字门店数据代表性问题,通过数据质量检测与预警模型,解决数字门店数据准确性的问题。
但本文所建立的选点标准更多是将宏观层面的门店分布纳入考量范围,但未考虑收银设备的安装条件、门店自身的经营条件以及经营者的能力等微观层面的影响因素,可能造成总体分布合理但单点缺乏发展潜力的问题。而数据质量检测更偏重当前较突出的违规扫码问题,而不是更精准的经营逻辑检查。随着行业数字门店体系建设的要求逐渐从数量转向质量,需要在下一步构建更加完善系统的模型算法达到“发展一户、用好一户”的本质目的,实现数字门店建设从“量变”到“质变”的转换。
参考文献:
[1]梁英, 莫柳青. “数字化门店”在流通品牌建设中的应用研究[C]. 2022: 24-30.
[2]张志远. “数字烟草”向信息化要竞争力[J]. 智库时代, 2019(01): 83+85.
[3]谢鑫, 张贤勇, 杨霁琳. 融合信息增益与基尼指数的决策树算法[J]. 计算机工程与应用, 2022, 58(10): 139-144.
[4]刘莺迎. 决策树分类算法的分析和比较[J]. 科技情报开发与经济, 2008(02): 65-67.
作者简介:
一作:郝越(1986-05),男,汉族,籍贯:陕西,职称:硕士学历,研究方向:市场营销。
二作:彭剑秋(1978-08),女,汉族,籍贯:四川绵阳,本科学历,研究方向:数字门店。三作:夏渝嘉(1984-03),男,汉族,籍贯:四川绵阳,职称:企业培训师、电子商务师,本科学历,研究方向:数据统计与分析。

 京公网安备 11011302003690号
京公网安备 11011302003690号


