



- 收藏
- 加入书签

计算机网络中Web信息智能抽取系统的设计分析
 打开文本图片集
打开文本图片集
摘要:随着互联网的快速发展,基于计算机网络的万维网(Web)承载海量的信息,促使其慢慢成为大众实际生活中检索各项信息的源头。下文旨在设计一个由万维网抽取自身所需信息的系统,在深入分析Web信息智能抽取系统需求基础上,详细介绍系统各部分内容设计情况,以期为类似研究工作提供一定的参考。
关键字:计算机网络;智能抽取系统;设计;Web
随着计算机网络技术的发展,人们期望通过网络不仅可以实现通讯,也能达到有效信息共享的要求。万维网是一个可利用网络访问的架构,其通过相连接的超文本文档建立起来,达到人们依托网络获得所需资料的要求[1]。日常人们借助万维网浏览器,便于随时查看文字、图片等信息,也可利用超链接在上述网页内实现导航[2]。刘稳,王锦等学者研究中针对法院判决书设计相应的信息抽取系统,该系统不仅可以自动生成结构化信息,也能结合主题图技术全面展示出来,便于使用者快速进行查询、修改操作,有利于案件判决者提高犯罪信息分析效率[3]。这种背景下,如何快速、高效率抽取所需的内容,成为人们期望解决的问题。针对上述情况,文章探讨如何设计Web信息智能抽取系统,以便更好的运用相关信息。
1.系统需求分析
近些年,由于计算机网络的快速发展,基于计算机网络的Web流量明显增加,其信息量也处于爆炸式增长的状态,越来越多的人开始采用网络获取所需信息。Web因具有信息量大、信息呈现动态性等特点,在各领域得到广泛的应用。信息抽取系统就是特定或通用信息进行提取操作的系统。Web信息智能抽取系统除要达到传统信息抽取要求外,还应依据Web特点攻克其他问题,例如;如何借助Web执行下载大数据网页的操作[4]。基于此,本次所设计的系统功能性需求如下:应提供不同的对外接口,即:依托用户界面便于用户执行配置、处理信息抽取任务的服务;依托Http协议服务开展各项抽取操作。前者要求系统设计用户界面及用于抽取任务执行的引擎。在此基础上,可以对抽取任务获取相应的Web信息实施存储,便于用户检索、使用。例如:支持各种格式的文件下载。后者要求系统应配置相应的Http协议服务器,借助该服务器便于完成Http请求解析操作,进一步执行信息抽取操作。具体情况下,Web信息抽取系统要能够抽取Web网页内通用格式及特殊列表的信息;所设计的系统应支持下载抽取页面、存储抽取结果等操作。
不得不说,非功能需求作为评估一个系统是否达到运行标准的指标,技术人员设计系统时,更倾向于功能方面的需求。用户实际操作时,则倾向满足自身非功能性要求。既然所开发的系统面向对象为用户,因此,所设计的系统要将用户非功能性需求考虑在内,具体表现如下:
(1)可扩充性:所设计的系统便于增添新功能,如果信息抽取工作量比较大,支持随时为系统增加新功能,大大提升系统的运行效率[5]。
(2)便于使用:用户使用、学习系统更为便捷,输出结果方便使用者理解。应用系统的用户不单单具有相关知识背景工作人员,也不具有软件开发经验或系统运营人员。在这种背景下,便于操作成为保证系统稳定运行应具有非功能性需求。
(3)可靠性:所设计的系统抽取准确地Web信息,并未增加数据运营工作人员的工作量。
(4)可重用性:对系统某一部件进行开发时,能够移植至相同需求平台充分利用。本次设计的系统不仅可以对通用信息进行抽取,也能推进信息收集向提供方面予以演化。
2.系统各功能模块设计
所设计的Web信息智能抽取系统支持对外提供抽取任务,也能达到Http服务下不同信息抽取服务要求。系统使用分布式体系结构,系统包含Http服务器、抽取任务管理器等组件。其中,Http服务器作为整个系统对外提供Http服务的组件,其依托Mongoose框架完成对用户基础请求予以响应,能够对用户不同的请求类型实施解析操作,便于完成响应抽取业务的处理工作。抽取任务管理器旨在对任务生命周期进行管理,用户重视做好任务状态的监控工作,顺利响应用户对于抽取任务进行创建、停止等操作。系统涉及抽取页面抽取功能、页面模板标注等模块,上述模块之间相互关联、协调,达到抽取Web信息的效果。
2.1页面抽取功能
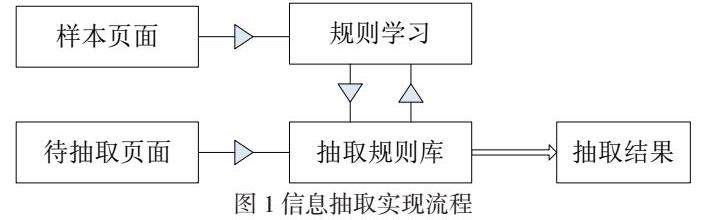
在Web信息智能抽取系统中,依托模板设计相应的页面模板标注模块,如果用户在某一网页页面检索出所需信息,利用鼠标进行标注,系统会根据用户标注页面信息提取相应的抽取规则。如果这一抽取规则认定有效,即可指导用户对标注信息实施提取操作,其满足于样本页面对大批量信息进行抽取操作的要求。抽取字段包含不同类型属性,任意一个抽取字段的位置,明确显示该字段标注页面展示的详细内容[6-7]。加之,由于页面标注出来有待进行抽取的字段代表用户期望执行的抽取目标。针对这种情况,对信息进行抽取时,不只要依据位置信息全面展示用户抽取目标在具体页面的位置,还要准确定义其属性。系统配置的抽取器各部件开展抽取操作时,会依据抽取字段具体位置及属性信息,进一步判定采用哪种抽取方法及需要得到相应的内容[8]。页面抽取数据采用JSON格式代表,其依托Javascript语言进行编程。信息抽取作为该系统的核心内容,信息抽取基于抽取规则为基础,任何一种信息抽取均要获得可靠的抽取规则。随之,准确完成信息抽取操作。例如:开展样本学习时,能获取相应的抽取规则,实现流程见图1。
2.2页面模板标注功能
该模块主要功能在于依托模板页面完成抽取服务,这也是整个系统不可缺少的一部分,其核心在于能与用户实现交互。用户借助所设计的Web操作界面标注指定样例中的节点。必要情况下,可以挑选或输入有待抽取的信息。随之,该模块能够根据用户执行的操作进行运算,进而展现包含不同模板字段的数据结构。在此基础上,通过页面模板开展标注构成相应的模板数据结构,各项数据存储于Mysql数据库内。系统页面模板标注提供相应的标注用户界面,前台执行与使用者实施标注相交互操作,后台旨在完成页面标注操作中所用页面渲染及相关数据存储操作。其中,该模块前台逻辑利用javascript语言完成编写,用户可通过点击鼠标执行输入标注等操作。系统在响应用户的标注页面前,会将用户标出来的页面URL作为请求信息,通过Ajax技术执行相应的渲染操作。这一操作完成后及时返回至标注页面,利用iframe标签向用户呈现经过渲染处理的各项内容。
2.3抽取任务引擎
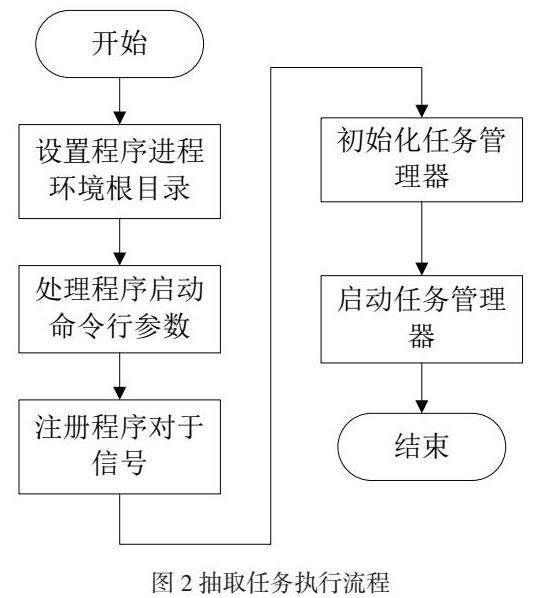
抽取任务管理器作为发出抽取任务请求的一个驱动模块,依托数据库访问接口与数据库、调度与抽取任务调度器实施交互[9-10]。抽取任务管理器是信息智能抽取系统的重要组件,借助独立进程法开展各项工作。实际运行中,抽取任务管理器先要对环境变量各项目录进行设定,借助启动组件完成信息输入操作,在此基础上,初始化响应任务。随之,对数据库内相关信息进行扫描、抽取出来,如:对某一个抽取任务状态由创建止血启动操作时,任务管理器会对整个抽取任务开展初始化操作。抽取任务管理器先要对页面种子URL及各项信息进行抽取,将其推送至任务调度器逻辑中。抽取任务管理器各项业务借助类Task Manager实现,成为整个抽取操作的驱动模块。
2.4信息抽取算法设计
2.4.1基于页面模板抽取算法
依托页面模板设计的信息抽取算法,旨在对Web特定网站信息及Web页面信息需求进行抽取。信息抽取算法实现过程如下:(1)使用者根据自己对于信息需求对期望抽取信息实施定义,如:期望对网址的部分问题及答案抽取出来。(2)用户根据Web网站提供的相关网页,根据其样式予以分类,且每个类别网页会选出相应的样例展示。(3)对于任何一个样例页面,使用者可利用系统标注功能,完成模板标注处理工作。(4)如果用户采用Web信息智能抽取系统时,可以指定数据源或采用这个数据源单个或多数抽取模板。(5)系统借助相应的模板完成对数据源页面信息的抽取操作。
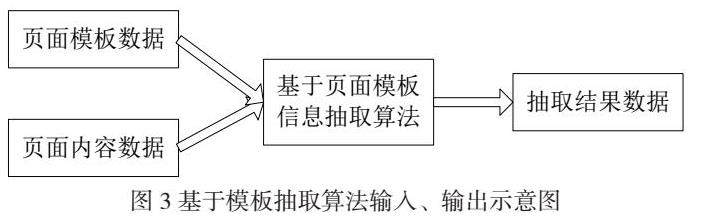
整个抽取算法输入作为页面模板数据及网页信息,输出操作则依据模板定义相应的抽取目标,通过网页获取相应的信息。输入、输出实现步骤见图3。
2.4.2基于列表结构抽取算法
系统设计出来针对列表结构的抽取算法,旨在对Web页面内根据列表结构对信息完成抽取操作。其中,利用HTML 标签表示相应的Web 网页文本。日常对Web网页内容实施处理时,网页会参照DOM(Document Object Model)各项标准执行各项操作,并以树型结构表示。其中,DOM树结构中任意一个中间或叶子节点与某个HTML标签相对应。全面分析计算机网络歌类网页的列表结构,便于总结每个列表项的特点。列表项特点归纳如下:列表项在网页HTML DOM的结构相似度较高;列表项作为DOM树的平级节点。最常见的列表形式为:···(A1-A2)-(A3-A4)···(An-1-An)···嵌套式重复结构,也是该算法定义的抽取列表项。
通过分析具体需求,下文选定列表-详细页面信息模型对算法进行执行,关注区域为重要列表区域。第一步,先要对页面各列表节点候选信息进行展示,如果利用DOM树模型得到相应的Web页面信息,必须对页面所有节点是否能够为某一可能实现列表结构进行评估。通过全面检索DOM树结构,判定所有经过节点是否执行列表候选中的子算法。基于此,对所有网页DOM树模型进行深度优选处理后,能够获取这一网页全部达到定义的候选节点集合。如果算法识别出获选的列表区域,会采用特殊颜色矩形框标识出来。
第二步,对页面内各项列表候选节点进行识别时,会求解候选列表中关键的指标分数。得到所有候选节点以后,根据相关指标设定执行排序规则,最终选定各候选节点中相对重要的内容,以此作为最终的识别结果。
第三步,得到列表区域的终极目标,在于获取该区域某一项有意义的外链。具体操作可知,一个外列表中包含不同的外链,因此,执行算法最终目标在于利用子算法由无数外链中求解得到具有意义的链接,进而得到最终的外链。
结论:
总之,在计算机网络技术得到广泛应用背景下,Web信息抽取技术逐渐趋于成熟。针对信息抽取设计相应的系统或开发支持抽取操作软件成为研究的热点,在市场上发展及应用场景较好。文章根据用户对于抽取Web信息需求,深入分析设计信息智能抽取系统各项需求,对系统各功能展开设计,以期为下一步系统开发奠定良好的基础。
参考文献:
[1]熊蕊,吴晨生,赵桂芬. 人物相关会议信息抽取系统设计及实现[J]. 情报杂志,2020,39(7):142-150.
[2]陈泽东,赵旭剑,张晖,等. 面向开放式信息抽取系统的知识推理验证[J]. 西南科技大学学报,2019,34(4):72-80.
[3]刘稳,王锦,李锐,等. 法院判决书关键信息抽取系统设计与实现[J]. 湖北工业大学学报,2018,33(1):63-67.
[4]张健. 专家主页信息抽取系统的设计与实现[D]. 江苏:东南大学,2019.
[5]曹瑞. 分布式信息抽取系统在物流领域中的应用[D]. 江苏:江苏大学,2018.
[6]宋立华. 基于信息抽取的电网缺陷文本挖掘系统设计[J]. 电子设计工程,2022,30(3):31-34,39.
[7]高海慧. 募集说明书文本信息抽取系统的设计与实现[D]. 中国科学院大学,2021.
[8]王博博. 面向上市公司三类信息披露公告的信息抽取系统[D]. 重庆:重庆邮电大学,2019.
[9]金伟豪. 基于知识图谱的电商信息抽取系统的设计与实现[D]. 江苏:东南大学,2019.
[10]张少迪,艾山·吾买尔,郑炅,等. 高并发汉英信息抽取系统的设计与实现[J]. 现代电子技术,2019,42(16):104-107,111.
作者简介:林碧洪,1989-01,男,汉族,广东省乐昌市人,本科学士,广州工商学院助理研究员,研究方向:计算机应用

 京公网安备 11011302003690号
京公网安备 11011302003690号


