



- 收藏
- 加入书签

语料库与语言研究
——以藏译本《贤愚经》为例
 打开文本图片集
打开文本图片集
摘要:本文系统介绍了语料库的概念、发展历程和分类,并深入探讨了语料库在语言学研究中的重要性,特别是在藏语言研究中的应用。通过对语料库的分析和利用,我们可以更深入地了解藏语言的语法结构、词汇使用和语言变化等方面,为语言学研究提供了丰富的实证数据和理论支持。本文强调了语料库语言学在藏语言研究中的重要作用和价值,对于推动藏语言学科的发展和促进语言文化的传承具有重要意义。最后,本文提出了在藏语言研究中进一步发展语料库的建议和展望,以期为藏语言学研究的深入发展提供有力支持。同时,通过语料库语言学和计算语言学的方法对《贤愚经》中出现的名词、动词、形容词和数量词进行了统计分析,探讨了这些词汇在文本中的频率和搭配规律。对文本的语法规则和文化现象进行了解析,为对《贤愚经》的语言特征和风格进行深入了解提供了重要的定量数据支持。
关键词:语料库、字符、词汇、句法
一、语料库与语料库语言学
1.语料库的概念
对于什么称之为语料库与语料库语言学,很多学者从不同的角度阐述了不同的定义。有专家认为,语料库语言学这一术语有两层含义,一是利用语料库对语言的某的方面进行研究,是一种新的研究手段。二是依据语料库所反映出来的语言事实对现行语言学理论进行批判,提出新的观点或理论,是一个学科的名称。
总之,语料库就是存放语言材料的数据库。语料库语言学就是基于语料库进行语言学研究的一门学问,具体点讲就是,研究自然语言机读文本的采集、存储、标注、检索、统计等方法的一门学科。
2.语料库的分类
根据不同的划分标准,语料库可以划分很多种。例如,2.1按语种划分:单语种语料库和多语种语料库。2.2 按地域划分:国家语料库和国际语料库。2.3 按用途划分:通用语料库和专用语料库。2.4 按时间划分:共时语料库和历史语料库。2.5 按加工程度划分:生语料库和标注语料库。2.6 按结构划分:平衡结构语料库和自然随机结构语料库。2.7 按表达形式划分:口语语料库和文本语料库等按照不同的研究目的可分为多个种类。
3.语料库的建设
建设语料库的目的是为语言研究提供研究手段。建设语料库建设的步骤简要概括为以下几点:3.1语料库的总体设计和规划:这是基础的工作,要确定语料库的种类、功能、规模及技术。3.2收集语料:“收集语料包括获得语料的途径、语料文件的数据格式、语料文件的大小、语料的选取标准及语料库中各类文本的比例等几个环节需要考虑”[1]。3.3语料库的加工:“根据需要进行初步的加工,按照统一标准,文本进行分类及标注。比如,词性标记、句法层次和范畴标记、词义标记、篇章指代标记、韵律标记”[2]等等。实践证明,构建大规模标注语料库是语料库语言学发展的重要基础。3.4 语料的应用:“语料库在自然语言处理的许多方面都有重要的应用价值。比如:基于大规模语料库的语音识别、基于大规模语料库的音字转换技术、基于大规模语料库的自动文本校对技术、利用语料库训练HMM模型进行分词、词性标注、词义标注、基于语料库的句法分析、基于语料库的机器翻译、基于机器学习技术、通过语料库获取语言知识、包括搭配特征、句法规则等等”[3]。通过一系列反复的工作之后可用于语言研究的领域,根据研究目的语言进行统计和分析,进一步阐述语言的各种现象。
二、藏译本《贤愚经》语料库的建设
1.藏译本《贤愚经》
《贤愚经》收录于《中华大藏经》,其虽名为经,但实际上是一部故事集,不仅有汉藏两种译本,还有英文等多种外文译本,是古典文献和语言、文学研究领域的重要典籍,各种研究成果层出不穷,成为一个研究热点。《贤愚经》汉译本和藏译本的卷数各不一,此典的汉译本有十三卷、十五卷、十六卷、十七卷等不同版本。藏译本也有十一卷、十二卷、十三卷等不同版本,其中郭法成译本堪称经典。《贤愚经》在藏族民间流传甚广, 对人们的思想观念和人生价值产生了深远影响。
2.藏译本《贤愚经》的语料库
在本研究中,对《贤愚经》语料库中出现的字、词、句进行了统计解析。首先,将出现的字分为字符、字丁和音节三种类型,并分别进行了统计和阐述。其次,将出现的词分为实词和虚词两大类。实词又细分为名词、动词、形容词、数量词四种主要类型;虚词分为自由虚词和不自由虚词两种。进一步将出现的句子分为单句和复句两类,分别对其中的句型和词、字进行了统计和解析。
通过对《贤愚经》语料库的统计和分析,可以深入了解该文本的语言特点和作者的写作风格。这种基于语料库的分析方法有助于揭示《贤愚经》的语言特征和文本结构,为进一步的文本解读和作者研究提供了重要的实证数据和理论支持。最终,通过对《贤愚经》语料库的分析,可以更好地理解该文本的语言特点和文学价值,为文学研究提供了新的视角和方法。
三、基于语料库的语言研究
在本研究中,我们建立了《贤愚经》的语料库,并利用Python程序对语料中出现的藏文字符和字丁进行了统计和分析。此外,我们还对藏文单音节、双音节、三音节和四音节进行了统计和分析。在词汇方面,我们对不同词类的频率和频次进行了研究,包括名词、动词、形容词和数量词等。此外,我们还对句型和文本风格进行了深入研究。
通过这些统计和分析,我们能够更全面地了解《贤愚经》的语言特点和文本结构。通过Python程序对语料库的处理,我们能够更加高效地进行大规模数据的统计和分析,为文本的解读和作者风格的研究提供了更为丰富的实证数据和理论支持。这种基于计算机程序的语料库分析方法为文学研究提供了新的工具和视角,有助于深入挖掘文本的语言特征和文学价值。
1.基于语料库的字符研究
藏文编码是藏文输入计算机的第一个环节,是藏文信息处理的关键技术之一。“在IS0/IEC10646《藏文编码甚本集》(以下简称《基本集》)里根据藏文的动态叠加特性,对藏文进行了编码。这就涉及到藏文的字符与构件问题。在《基本集》里,共安排了192个码位,占用OF00-0FBF区域,其中168个编码字符及构件,空缺码位24个。在1999年9月公布的Unicode3.0中,增补了34个藏文字符构件和符号。“Unicode4.0中没有增加藏文字符,但是藏文编码空间进一步扩充到OFFF范围,共计256个码位”[4]。藏文编码《基本集》平面OF行的00位上。Unicode 6.2收录的藏文字符的编码从OF00 到OFDA,共211个,其中包括辅音字符、元音符号、变音符号、数字符号、标点符号和一些其他符号。
“《藏文编码字符集基本集》以藏字中的每一个字符作为编码的对象,编码流的顺序规定。为藏字的书写顺序,也就是藏字在键盘上的输入顺序。如以下所示;
བསྒྲིགས=བ(0F56)+ས(0F66)+ྒ(0F92)+ྲ(0FB2)+ི(0F72)+ག(0F42)+ས(0F66)+་(0F0B)”[5]
下面通过《贤愚经》的语料库为例,介绍语料库对语言研究的作用和方法,并该文本中出现的字符进行统计及分析来解释各种语言现象。
根据《藏文编码基本集》的字符与构件、符号,在《贤愚经》中,共出现字符与构件、符号504623次,符号及构件种类68个。其中出现最多的是音节点,共出现126824次,占《贤愚经》总字符的25.1324%;其次是单垂符,出现了6446次,占《贤愚经》总字符的1.2773%;第三个是双垂符,共出现了3097次,占《贤愚经》总字符的0.6137%;《贤愚经》总字符中出现最少的是起始符,《贤愚经》的整个字符中就出现了一次。
除了标点和符号外,四个元音中出现最多的是“i”,共出现了23953次,占《贤愚经》总字符(除上述标点外的总量368205)的6.0553%。其次是“o”,出现了22409次,占《贤愚经》总字符(除上述标点外的总量368205)的6.0860%。再次是“e”,共出现了17477次,占《贤愚经》总字符(除上述标点外的总量368205)的4.7465%。最后是“u”出现了15405次,占《贤愚经》总字符(除上述标点外的总量368205)的4.1838%。排序为“i o e u”,传统语法的排序为“i u e o”, 《贤愚经》中“o”和“u”的位置换了,之所以出现这种情况,与《贤愚经》的写作风格有关,《贤愚经》中出现的大量的终结词。
通过对《贤愚经》中元音的频次进行统计,我们可以深入了解该文本的语音特点和元音的使用规律。这种基于元音频次的分析方法为深入挖掘藏文文本的语音特点和语言风格提供了重要的实证数据和理论支持。
除了标点和符号、元音外,构件出现的排序为“ས་ད་ག་བ་ན་ང་ར་མ་ལ་འ”。这个排序恰好对应藏文的十个前加字,这种现象值得我们进一步深入研究。这种语言现象可能反映了《贤愚经》文本的特殊结构和编排方式,暗示着作者在使用构件时可能有意识地遵循了特定的语言规律或者风格。这种现象的存在可能与藏文语言的特殊特征、文化传统或者作者的写作意图有关,需要通过进一步的语言学、文化学和文本分析来探究其深层含义和意义。对构件排序的研究有助于揭示《贤愚经》的语言结构和文本特点。
2.基于语料库的音节研究
音节是一字根为中心的语言单位。藏文音节是以藏文音节点来分的,音节又可分为单字音节、双字音节、三字音节、四字音节等。对藏文的音节数初次做过研究的是萨伽索南则牟,才丹夏茸先生也生前曾计算过藏文音节数,最后他认为藏文有 17532个音节。多拉教授所著的《藏文规范音节频率词典》中,通过建立四种不同的语料库进行考察,最后得出,藏文规范音节总数为9111个,其中纯藏文规范音节为8263个,梵文转写音节为848个。
音节研究对字典的建设、教材建设、通用词表的建设、音节的总数及分布和使用情况等提供了可靠的数据和依据。
在《贤愚经》中,共出现了2220个不同的音节,且这些音节的出现频次高达134471次。平均每个音节出现60.6次,其中出现频率最高的音节出现了4826次,而最低频率的音节仅出现了1次。这种音节的分布特征反映了《贤愚经》的语言风格和文本结构,同时也反映了藏文语言的特殊特征和文化传统。对音节的研究有助于揭示《贤愚经》的语言特点和文本结构,为对该文本的深入解读和作者研究提供重要的实证数据和理论支持。
3.基于语料库的词汇研究
词汇是语言研究中的一个关键领域。标注语料库的价值在于它提供了便捷的观察语言各种现象的途径,其中包括词汇的功能。在这里,功能指的是词汇在句法结构中所处的位置和所扮演的角色。标注语料库为我们提供了观察这些位置和角色的统计数据,从而有助于深入理解词汇在句法结构中的使用规律和语言的表达方式。通过分析标注语料库,我们可以更好地把握词汇在句法结构中的作用,从而深入探讨语言的语法特点和语言表达的规律。
通过《贤愚经》的语料库,我们可以进行对词汇的研究。词汇可以分为实词和虚词两大类,其中实词包括名词、动词、形容词和数量词,而虚词则包括格助词、自由虚词和非自由虚词等。通过对《贤愚经》语料库的统计分析,我们发现其中涵盖了90多种词类,共计5087个词语,出现频次高达103826次。这表明《贤愚经》在词汇使用上具有丰富多样的特点。此外,通过进一步分析,我们发现前10个出现频次最高的词语均为虚词,这为我们提供了对于文本语言特点和风格的重要线索。
语料库的研究方法通过对大规模语言数据的统计和分析,可以揭示出文本的词汇特点、语言使用规律和风格特征。通过对不同词类的频次统计,我们可以了解到文本中各类词汇的使用情况,从而深入理解文本的语言特点和表达方式。这种研究方法有助于揭示《贤愚经》的语言特色。
4.基于语料库的句法研究
句子作为语言运用的基本单位,由词和词组(短语)构成,能够表达完整的意思。根据句子的语气特点,我们可以将句子分为陈述句、疑问句、祈使句和感叹句等不同类型。而根据句子的结构特点,我们可以将句子分为单句和复句,其中复句又可以进一步细分为若干小类。通过对句子的分类和结构分析,我们可以更深入地理解句子在语言表达中的作用和特点,进而揭示语言表达的规律和特征。这种分类和分析方法有助于我们更全面地理解句子在语言中的功能和运用规律,为语言学研究提供了重要的理论基础。
在《贤愚经》语料中,为了便于统计,我们以藏文垂直符作为句子的界限进行分析。这些垂直符可以进一步分为单垂符和双垂符等不同类型。尽管有时以垂直符为界限的句子并不一定构成一个完整的句子,但为了便于统计分析,我们仍然采取了这种方式。在《贤愚经》中,以垂直符为界限的句子共出现了8668个,其中单垂符为界的句子出现了6446个,双垂符为界的句子出现了3097个,四垂符为界的句子出现了51个。这些句子中,频率最高的达到了41次,而最低的仅出现了1次。通过统计分析,我们发现在《贤愚经》中共出现了8011种不同的句型,总出现频次达到9479次,从中可以看出《贤愚经》在句法结构上的特点和规律。这种统计方法有助于我们深入了解《贤愚经》的语言特征,为进一步的语言学研究提供了重要的数据基础。
5.基于语料库的文本风格研究
风格是指人们在交际活动中形成的个人言语特征,包括句子、词语甚至篇章的独特感悟。通过对文本的分析,我们可以深入研究文本的风格。基于语料库的文本风格研究是以量化的语言特征来对文本风格和作者写作习惯进行研究的方法。其理论基础在于认为文本的语言特征反映了作者在写作活动中的个人言语特征,是作者个人风格的不自觉而深刻的反映。这些特征可以通过数量特征进行刻画,从而揭示出文本的风格特征和作者的写作特点。通过这种研究方法,我们可以更加深入地了解文本的语言特征,为文学研究和语言学研究提供了重要的数据。
作者的写作风格可以通过文本中的字符、词、短语、标点符号等进行深入分析。在字符方面,研究者将文章视为一个字符序列,从中提取字母、数字、符号等特征,并使用频数来表示这些特征。在词汇方面,研究者会关注词长、词汇丰富度、功能词、高频词等方面进行研究,以揭示作者的词汇使用特点。句子方面的分析主要涉及句长分布和句长离散度的研究,以探讨作者在句子结构上的个人特点。此外,段落方面常使用的特征是平均段落长度,该特征可以通过文本的总字数与总段落数的熵来计算,从而揭示出作者在段落组织上的个人风格特点。通过对这些不同层面的特征进行分析,研究者可以更加深入地了解文本的语言特征,揭示出作者的写作风格和独特表达方式。
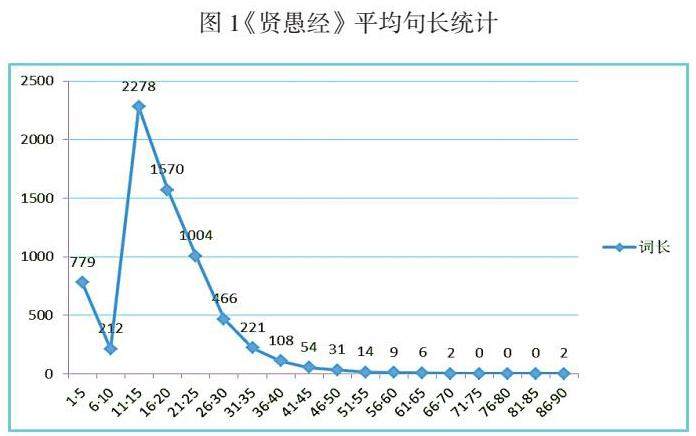
在句长的考察过程中,我们主要从句长分布和平均句长两个方面进行了分析。句长反映了句子的复杂程度,即一个句子中包含的音节数。我们的分析显示,《贤愚经》的平均句长相对较短,表明该文本的复杂性较低,可读性较强。具体而言,我们发现《贤愚经》的平均句长大约为15个音节,其中11个音节到15个音节之间的句子出现频率最高,共出现了2278次。
结语
随着计算机技术的迅速发展,计算机已经成为语言研究和语言教学中不可或缺的重要工具。这种发展促进了语言研究方法的改进,使得语言研究更加规范和科学,并加快了语言研究的进程。统计方法在自然语言处理中得到了广泛应用,而计算机技术的快速发展也使得基于语料库的语言研究成为一个备受青睐的研究方向。一些学者甚至指出,语料库语言学已经成为语言研究的主流。基于语料库的研究不再只是计算机专家的专属领域,而是对语言研究的许多领域产生了越来越大的影响。计算机技术能够丰富语言教学方法和手段,提供生动的语言环境,并提高语言学习的效率。
语料库是计算机在语言领域应用的一种形式。近年来,全球范围内广泛展开了语料库的建设,其容量逐步扩大,种类繁多,应用已经渗透到语言领域的各个方面,成为语言研究、词典编纂和语言教学的有力工具,受到了语言研究者和教育工作者的高度重视。这一发展为语言研究和语言教学带来了新的机遇和挑战,也为语言领域的进步和发展提供了强大的支持。
在本研究中,我们通过语料库语言学和计算语言学的方法对《贤愚经》中出现的名词、动词、形容词和数量词进行了统计分析,探讨了这些词汇在文本中的频率和搭配规律。同时,我们对文本的语法规则和文化现象进行了解析。这一研究为我们深入了解《贤愚经》的语言特征和风格提供了重要的定量数据支持。随着计算机技术的不断发展,计算机已经成为语言研究和语言教学中不可或缺的重要工具,这为我们提供了更多的可能性和机遇,也为语言领域的进步和发展提供了强大的支持。通过这项研究,我们对语言研究方法和技术的应用有了更深刻的认识,也为未来的语言研究和教学工作提供了宝贵的经验和启示。
参考文献:
杜斗城译注,白话《贤愚经》,甘肃人民出版社出版,1994.
慧觉等译撰,温泽远等注译,《贤愚经》,花城出版社出版,1998.
光亮编译,《贤愚经》,西藏人民出版社出版,2017.
冯志伟著,《现代语言学流派》,商务印书馆出版,2013.
索绪尔著,《普通语言学教程》,商务印书馆出版,2017.
俞士汶编,《计算语言学概论》,商务印书馆出版,2003.
欧珠,扎西加编著,《藏语计算语言学》,西南交通大学出版社,2014.
多拉,基于语料库的《格萨尔》史诗语言研究,西北民族大学,2012.
多拉,扎西加,史诗《霍岭》语料库句子及诗行计量解析,中央民族大学学报,2015(3)
俞士文,《计算语言学》,第85页,商务印书馆,2003年
俞士文,《计算语言学》,第91页,商务印书馆,2003年
俞士文,《计算语言学》,第99页,商务印书馆,2003年
多拉,基于语料库的《格萨尔》史诗语言研究,第105页,2012年
高定国,《藏文信息处理的原理与应用》,第67页,西南交通大学出版社,2013年
作者简介:满拉: 男,青海黄南人,西北民族大学2020级语言学专业博士研究生,研究方向:语言学及应用语言学专业。

 京公网安备 11011302003690号
京公网安备 11011302003690号


