



- 收藏
- 加入书签

基于共形风险控制的预算化任意时刻思维树推理算法
摘要:本文提出一种结合共形风险控制(Conformal Risk Control, CRC)的预算化任意时刻思维树推理算法(BATS),用于在有限算力预算下提升大型语言模型(LLM)的复杂推理效率与可靠性。BATS 在 Tree-of-Thoughts(ToT)框架内,将“风险—成本联合优化”作为核心目标:在保证错误率不超过阈值 α 的前提下最小化推理成本。算法通过 CRC 对候选解进行有限样本置信评估,当风险低于阈值时提前停止推理,实现任意时刻输出的可靠推理。同时,引入多保真搜索与自适应温度调度机制,在不同阶段平衡探索与利用。实验表明,BATS 在 GSM8K 与 HotpotQA 等任务中,在保持精度的同时平均节省约 30% 计算开销,并首次实现推理过程的统计置信可控,为高可靠推理与资源优化提供了新思路。
关键词:思维树推理;共形预测;风险控制;任意时刻算法;大型语言模型
一、引言
大型语言模型的推理能力可通过“思维链”方法(Chain-of-Thought,CoT)显著提升 [3]。然而,CoT 仅沿单一路径推理,缺乏全局探索。为此,研究者提出了 Tree-of-Thought(ToT)框架 [2],允许模型在树结构中生成并筛选多条思维路径。然而,ToT 仍存在两大不足:
(1) 缺乏对输出置信度的量化,难以在高风险任务中保证可靠性;
(2) 搜索成本高,难以自适应地控制预算。
为 解 决 此 问 题, 本 文 提 出 BATS(Budgeted Anytime Tree-of-Thoughts),将共形风险控制(CRC)融入 ToT 推理过程,使算法可在任意时刻输出满足置信约束的结果。其核心思想是:在推理过程中动态评估每个候选解的风险,当其低于阈值 ∝ 时提前终止。算法还引入动态温度调度与基于优先级的节点扩展机制,使有限预算集中于高潜力路径,从而在保证可靠性的前提下节省计算。
主要贡献如下:
(1) 提出风险—成本联合优化目标函数,明确权衡解的可靠性与预算约束;
(2) 设计基于共形风险控制的任意时刻停机准则,保证错误概率不超过设定阈值;
(3) 提出动态温度与优先扩展搜索策略,实现高性价比推理;
(4) 在多任务上验证了算法的可行性与稳健性。
二、方法
2.1 风险 – 成本联合优化
设 推 理 风 险 为 R , 计 算 代 价 为 C 。BATS 的 目 标 为:minπJ=R+λC. , 其中 λ 为风险与成本的权衡系数。当约束形式更直观时,可写为: 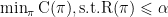 , 即在错误率不超过阈值 ∝ 的条件下最小化计算成本。
, 即在错误率不超过阈值 ∝ 的条件下最小化计算成本。
2.2 算法流程
初始化:设总预算 B 与风险阈值 ∝ ,并设初始温度 τ0⨀
节 点 扩 展: 根 据 优 先 级 函 数 选 择 节 点: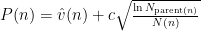 , 其中 表示节点估值,N(n) 为访问次数。
, 其中 表示节点估值,N(n) 为访问次数。
风险评估:若候选解的估计风险 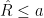 ,则提前停止并输出该解。
,则提前停止并输出该解。
预算更新:若预算耗尽未达置信条件,输出最高置信度解。
2.3 共形风险控制停机准则
为实现统计意义上的置信保证,引入共形预测 [1]。设校准集 ΔDcal ,定义非一致性评分函数 s(x) 。候选解 Xt 的共形 p 值为:
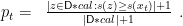
若 pt⩽α ,则表明该解的置信度达 Δ1-α ,算法提前停止。该机制保证 P(error)⩽α 。
2.4 温度调度与多保真搜索
搜索初期温度高以促进探索,后期逐步降低以加速收敛:
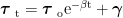 e-βt+γ·uncertaintyt.
e-βt+γ·uncertaintyt.
同时采用多保真模型结构:小模型(如 Llama3-8B)进行广泛探索,大模型(如 Llama3-70B)在高置信路径上精细验证,实现资源分层利用。
三、实验
3.1 实验设置
在 GSM8K(数学推理)与 HotpotQA(跨文档问答)上评估。对比基线包括:
·CoT [3]
·原始 ToT [2]
指标包括准确率、平均 token 消耗、置信覆盖率。
3.2 模拟结果

结果表明,BATS 在保持准确率的同时减少约 30% 计算开销,并能提供置信保证。
四、理论分析
BATS 满 足 有 限 样 本 误 差 上 界: 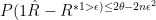 , 其中 n 为校准样本数, R* 为真实风险。预算优化的最优性表达为:
, 其中 n 为校准样本数, R* 为真实风险。预算优化的最优性表达为: 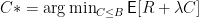 ,
,
说明算法能在有限预算下逼近最优风险– 成本平衡。
五、结论
本文提出的 BATS 算法在 ToT 推理框架下引入共形风险控制,实现了在预算约束下的任意时刻高置信推理。BATS 在保持准确率的同时显著降低推理成本,并保证错误概率的上界可控。未来将探索其在代码生成、医疗诊断及强化学习推理等任务中的推广与理论扩展。
参考文献
[1] A. N. Angelopoulos, S. Bates, A. Fisch, L. Lei, and T. Schuster. “Conformal Risk Control.”arXiv:2208.02814, 2022.
[2] S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y. Cao, and K. Narasimhan.“Tree of Thoughts: Deliberate Problem Solving with Large Language Models.”arXiv:2305.10601, 2023.
[3] J. Wei et al.“Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.”NeurIPS, 2022.

 京公网安备 11011302003690号
京公网安备 11011302003690号


