



- 收藏
- 加入书签

基于YOLO v5实现聋哑人与普通人的双向交流设想
 打开文本图片集
打开文本图片集
摘要:帮助聋哑人实现与普通人之间双向基本交流需求,是现代社会以人文本的重要体现。本文基于YOLOv5技术,以及使用数据库、单片机、摄像设备等,对实现这一需求做出了研究设计。通过建立手语及常用词语的数据库,并利用YOLO v5框架对摄像设备采集到的手语动作进行解码分析,经过不断训练后,将其部署到树莓派或单片机中,并连接显示设备,最终实现手语与文字的双向转化,从而助力听障人士与普通人之间进行基本沟通。本文重点分析了技术优势及一些应用的不足。
关键词:聋哑人;双向交流;数据库;YOLOv5;单片机
一、研究背景
据最新研究资料显示,我国听障人士数量庞大,约为2600万人,占中国人口总数量的1.86%。当前,这类群体主要面临三方面的问题:第一个是生活方面的问题,听障人士对外界缺乏了解,甚至不能驾驶车辆,不能参加献血。第二个是工作方面的问题,因为无法实现有效沟通,听障人士很难找到工作,大多数的工作都很难有效完成。第三个是心理方面的问题,先天的生理缺陷使他们在面对诸多不便时需要很强的的意志力。
党和国家高度重视残疾人融合发展,重视无障碍交流环境的建设和语言辅助设备供应和服务,加快完善相关法律的法规和标准,加大支持力度、辅助设备供应和服务的政策支持。国家已经将手语工作纳入相关国家规划,制定手语工作专项规划。基本形成手语规范化工作机制,各地区的语言文字部门开始将手语相关工作作为语言文字工作发展的重要模块,纳入发展规划、统一战略部署,并且做好相关业务的指导和技术设备的支持,积极开展手语科学研究,加快成果转化。
然而,我国手语翻译职业化进程发展较晚,国内手语服务行业目前处于发展的初级阶段,根本无法满足听障人群日益增长的语言服务需求。如何助力聋哑人服务体系的建设是一个十分紧迫而艰巨的事情。
针对这一社会现象及社会需求,我们提出了一款助力聋哑人与普通人之间实现双向交流设备的研究方案设想,这款设备名叫:为“声”搭桥。
二、设备的技术理论研究设想
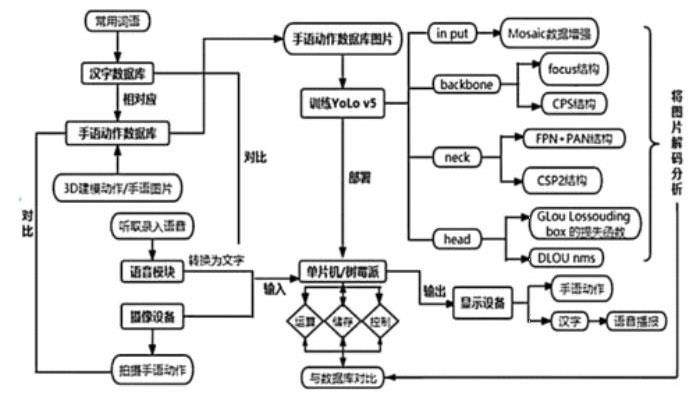
简介:我们在对手语进行转化时,收集常用的汉字建立词库,并建立相应的手语动作数据库,通过YOLO v5框架实现将1080\720P图像中的手语动作解码分类为指定的汉字。再根据数据库进行训练后将YOLO v5框架部署到树莓派或者其他单片机系统,单片机系统应当组装摄像模块、语音模块和显示屏。通过摄像模块录制视频后由YOLO v5框架逐帧解析后再显示到显示屏上,同时阅读汉语文本。对语音文字转化时,绘制好3d建模动作,通过单片机系统的语音模块将语音转化为汉语文字,并将汉语文字解码分类为指定的手语动作,通过显示屏播放虚拟手语图像。设计流程图如下:
具体设计理论如下:
(一)对手语进行转化
1、YOLO v5技术的应用
在对手语进行转化时,收集常用的汉字建立词库,并建立相应的手语动作数据库,通过YOLO v5框架实现将1080\720P图像中的手语动作解码分类为指定的汉字。YOLO v5是一种单阶段目标检测算法,是一个在COCO数据集上预训练的物体检测架构和模型系列,其网络结构分为:input、backbone、neck和head四个模块,Mosaic数据增强、自适应锚框计算、自适应图片缩放等多种技术被使用在input端;而在backbone端使用了Focus结构与CSP结构;在neck端添加了FPN+PAN结构;在head端改进了训练时的损失函数,使用GLOU_Loss,以及预测框筛选的DloU_NMS[1]。
输入端口则负责对所输入的图像进行预处理。该网络的输入图象尺寸为608*608,而预处理过程主要是先把输入图象进行缩放,然后放到网络的输入位置上,再完成归一化的运算[2]。在网络训练的阶段,YOLO v5通过利用Mosaic数据增强操作使模型的训练速度和网络的精度得到了极大的提升;而且还提出了自适应锚框计算与自适应图片缩放方法。YOLOv5通过Mosaic数据增强将4张图片随机缩放、随机裁剪以及随机排布,并且充分分析和处理捕捉到的图片,最后将其拼接到一张图片上,作为训练的数据,这样做极大的丰富了数据集,并且大大提升了网络的训练速度,还降低了内存[3]。对于自适应锚框计算,不同的数据集,都需要设定特定长宽的Anchor。在网络训练阶段,模型输入对应的预测框,这是以初始锚点框为基础的。然后对预测框与真实框之间的差距进行计算,并执行方向更新操作,从而更新整个网络的参数。YOLO v5模型在每次训练时,能够根据数据集的名称自适应的计算出最佳的锚点框。自适应图片缩放采用传统的图片缩放方式进行图片缩放,其首先按照原始比例将图片缩放,未到目标大小的部分用黑色填充,然而在实际操作中,我们手机的图片有着不同的长度和宽度,而图片被缩放后,在图片的两端会有不同大小的黑边出现,但是如果过多的填充,则会使出现大量的的多余的信息,从而减缓了整个算法的推理速度。为了提高YOLO v5算法的推理速度,我们提出了一种方法,这种方法方法可以自适应的为缩放后的图片添加最少的黑色[4]。具体步骤如下:
(1)以原始图片大小和输入到网络图片大小为依据,计算图片的缩放比例;
(2)根据原始图片大小与缩放比例计算缩放后图片的大小;
(3)计算黑边填充数值,该黑边数值要求一定使图片缩放至自适应模型中卷积和池化的大小。
backbone的引入了Focus结构和CPS结构。其中Focus结构的切片操作是最重要的部分,在YOLO v5网络模型中,往Focus结构中输入原始608*608*3大小的图像,通过Focus结构中切片操作,将原始图片切割成304*304*12大小的特征图,然后经过一次32个卷积核的卷积操作,最终变成304*304*32大小的特征图[3]。另一个是GPS结构,YOLO V5中设计了两种CPS结构,主干网络中应用了CPS1_X结构,而Neck网络中则应用了另一种叫CPS2_X的结构。YOLO V5的Neck网络使用FPN+PAN结构,但是在它的基础上做了一些改进[5]。借鉴CSoNet设计的CSP2结构在YOLO v5的Neck网络中,使得网络特征融合能力得到加强。在head部分,YOLO v5改进了损失函数,采用Glou_Lossounding box 的损失函数,并添加了预测框筛选的DloU_NMS[6]。再根据数据库进行训练后将YOLO v5框架部署到树莓派或者其他单片机系统。
2、YOLO v5技术的优势
(1)在Mosaic数据方面,YOLOv5通过Mosaic数据增强将4张图片随机缩放、随机裁剪以及随机排布,并且充分分析和处理捕捉到的图片,最后将其拼接到一张图片上,作为训练的数据。
它的优点在于:
①丰富数据集:因许多数据集中,大、中、小目标的比例极不均衡,小目标的数量相对较少,采用随机scale的trick增加小目标占比,从而提高网络鲁棒性,使其变的更好;
②减少图形处理器:在Mosaic进行训练时,可以直接计算拼接在一起的4张图片的数据,这就变相地提高了batch_size,在进行batch normalization的时也计算四张图片,而对自身的batch_size不是很依赖,使用单块GPU就可以进行训练[7]。
(2)在自适应锚框方面,YOLO v5模型在每次训练时,通过计算机单独的程序运行,根据数据集的名称自适应的计算出最佳的锚点框,从而自适应的计算不同训练集中的最佳初始锚框值。
(3)在自适应图片缩放方面,YOLOv5时缩放之后的图片自适应的添加最少的黑色,自适应的对原始图像进行调整。使图像高度上两端的黑边变少了,所以在推理时,计算量就会减少,目标检测速度得到提升。
(4)Focus结构:关键在于切片操作。将原始图像二倍间隔采样:每隔一个像素拿到一个值,相当于对原始特征重排。它的优点在于提高了感受野,将w-h面上的信息转入到通道维度,保证信息未丢失。
(5)CSP结构:YOLOv5中设计了CSP1_X和CSP2_X两种CSP结构,在特征图中集成了梯度的变化,模型的参数量和FLOPS数值也相应减少,推理速度和准确率有极大的提高,而且尺寸也被减小,有效的缓解梯度消失问题[8]。
3、其它辅助设备与技术的应用
(1)树莓派
树莓派是指Raspberry Pi,它是一款类似银行卡大小的微型电脑,可以与键盘、鼠标和网线进行连接,还拥有HDMI高清视频输出接口和视频模拟信号的电视输出接口,可以播放高至1080P的高清视频,它的银行卡大小的主板,具备着计算机所有的基本功能。
(2)单片机
运算器、控制器、主要寄存器三个模块共同组成了单片机。运算器有执行各种算术运算和执行各种逻辑运算两个功能。运算部件算术逻辑单元、累加器和寄存器等几部分共同组成了运算器。它在控制器的控制下,把传过来的数据进行算数或逻辑运算,最后将结果存入累加器。而控制器由程序计数器、指令寄存器、指令译码器、时序发生器和操作控制器等组成,协调并指挥整个微机系统的操作[9]。
微处理器内通过内部总线把ALU、计数器、寄存器和控制部分互联,并通过外部总线与外部的存储器、输入输出接口电路联接。通过输入输出接口电路,实现与各种外围设备连接[10]。
单片机系统应当组装摄像模块、语音模块和显示屏。通过摄像模块录制视频后由YOLO v5框架逐帧解析后再显示到显示屏上,同时阅读汉语文本。
(二)对语音进行转化
1、语音到手语的转化
对语音文字转化时,绘制好3d建模动作,通过单片机系统的语音模块将语音转化为汉字语言,并将汉语文字解码分类为指定的手语动作,通过显示屏播放虚拟手语图像。
我们把高清摄像头与计算机连接,将高清摄像头作为数据采集的设备,并通过高性能计算机进行运算,让聋哑人在规定的背景区域内进行手语表达,计算机接受到数据信息并转换,进而实现实时翻译,从而理解聋哑人的语言表达。通过采集听障者手语表达的数据集,对数据集中上千个句子进行分析和归纳,研发出一套手语识别转换算法,识别听障者大部分的日常表达用语,从而进一步缓解聋哑人与普通人之间沟通障碍,帮助聋哑人获得更好的服务,同时也使的普通人能够对其进行良好的服务。
2、数据库应用系统的优势
有较大的内存,可以储存大量的数据信息,占用空间小;对于数据库的管理,便利高效,且数据的维护有很高的安全性;在使用数据库管理信息资源时,我们可以任意的进行各种操作;还对数据进行分类(按关键词),从而使检索数据的速度更快,大大的提高了检索效率。还有就是数据库的数据应用有很好共享性,以及较高的效率。
三、应用的缺失
(一)面临的问题及原因
问题一:数据采集和处理有很大的难度
原因:手语表达具有特殊性,还具有地域性;我国语言文化多样,各地方言也不同,普通话不标准等,极大的提高了数据采集与处理的难度。
问题二:算法的设计以及优化面临很大的技术考验
原因:外界对听障群体的整体关注度不高,数据的采集相对滞后,而且国内外对这一方面的研究比较空白,可借鉴的极少,这些都对技术研究提出了很大的挑战。
问题三:各个技术模块的衔接较为困难
原因:目前的研究设想尚处于研究阶段,各模块的数据需要不断的调试优化,如何有效的衔接和组装面临的很大困难,需要进一步的研究。
(二)改进措施
1、我们希望能与听障者进行接触,扩充我们数据的容量,加快完善数据的规范,加强普通话标准化,地区手语标准化,以降低语言转换难度,提高转换准确率,完善数据。
2、根据不同的场景来优化我们的识别算法,与数据库中的手语、汉字数据进行精确比对,并不断运行、改进算法,尽快搭建出无障碍沟通的完整平台。
3、加强对各个技术模块的训练与调试,不断优化,多进行标准化测试,加强技术衔接的流畅性,形成一套完成技术设计方案。
四、结语:
实现聋哑人与普通人间的双向交流面临着巨大的需求,我们要提高数据的标准化程度,不断优化研究技术,使技术进一步突破,提高运算效率,同时让算法提供更多的算法和表达。相信为“声”搭桥产品的设计,以及未来的出现,将为实现全社会的无障碍化交流拓宽前行之路。也将为推动国家“十四五”发展时期,手语规范化工作提供一定技术支持,同时加大通用手语推广力度,加强国家通用手语规范标准建设、应用与人才培养等多方面工作贡献巨大力量。相信在不久的将来,为“声”搭桥可以向世界证明,只需要打开一个通道、接通一座桥梁,技术红利就可以源源不断地汇聚到那些需要它的人群当中!
参考文献:
[1]王谈,郭祺赞,毕美华.基于YOLOv5的鱼塘养殖系统设计[J].电子测试,2022,36(10):42-44
[2]何斌,张亦博,龚健林,付国,赵昱权,吴若丁.基于改进YOLOv5的夜间温室番茄果实快速识别[J].农业机械学报,2022,(9):201-208
[3]王淑青,顿伟超,黄剑锋,王年涛.基于YOLOv5的瓷砖表面缺陷检测[J].包装工程,2022,43(9):217-224
[4]李昌夏,加文浩,黄政龙,黄文峰,甘恒.基于YOLOv5的实时抽烟检测研究[J].电脑知识与技术,2022,(8):100-102
[5]王国庆,李璇,杨理践,高松巍,耿浩.基于改进YOLOv5算法的管道漏磁信号识别方法[J].计算机测量与控制,2022,(8)147-154
[6]管尧,朱凯.基于雾天条件下交通道路上的目标检测[J].电脑与电信,2022,(5):69-76
[7]黄璐,毛晓艳,杜航,谢心如,胡海东.基于深度学习网络的星表非结构化岩石目标辨识方法研究[J].空间控制技术与应用,2021,47(6):27-33
[8]周伟鸿,朱思霖.基于深度学习技术的智慧考场方案的应用探究[J].信息技术与信息化,2020,(12):224-227
[9]李昌鑫.单片机在广播发射机中的应用[J].西部广播电视,2018,(16):222
[10]刘志茹,耿晓文.基于多媒体技术的校园全景沙盘设计与实践[J].科技风,2019,第(16):19
*基金项目:本文系2022年度晋中学院大学生创新创业训练项目(项目级别:省级,项目名称:为声搭桥,项目编号:20221105)阶段性研究成果,并受上述基金计划资助。
作者简介:李申奥(2002—),男,汉族,山西长治人,晋中学院经济管理系财务管理2021级01班本科生。

 京公网安备 11011302003690号
京公网安备 11011302003690号


