



- 收藏
- 加入书签

浅谈开源大数据平台数据仓库工具的应用
 打开文本图片集
打开文本图片集
摘要:开源大数据平台Hadoop采用分布式文件系统方式存储数据,而开源数据仓库工具HIVE可以使用类SQL语句的方式来分析存储在Hadoop中的数据,开源大数据平台和开源数据仓库工具在实验和科研环境中都有着很广泛的应用。本文从开源数据仓库工具HIVE的所需要的环境开始分析,探讨离线开源大数据完全分布式环境中开源数据仓库工具的建设与应用,通过多台机器的部署,分析其中的问题,并提出解决方法。
关键词:HIVE;开源
由于HIVE需要将元数据保存在mysql中,检查在查询过程执行语义检查的时间,所以下面我们先来完成mysql的部署。这里我们采用离线方式,在线方式可使用软件仓库进行相应配置。
一、数据库环境配置
1、Mysql数据库的安装
(1)查询mariadb是否安装
[root@master ~]# rpm -qa |grep mariadb-lib*
mariadb-libs-5.5.68-1.el7.x86_64
CentOS 7版本将MySQL数据库软件从默认的程序列表中移除,用MariaDB代替了,MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可。开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL闭源的潜在风险,因此社区采用分支的方式来避开这个风险。MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。
[root@master ~]# rpm -e --nodeps mariadb-libs
卸载mariadb,改为安装mysql。
[root@master ~]# rpm -qa |grep mariadb-lib*
[root@master ~]#
再次查询,已经卸载完成。
(2)安装mysql数据库
提前下载好mysql离线安装包mysql-5.7.32-1.el7.x86_64.rpm-bundle.tar
由于mysql安装需要root用户权限,所以将离线安装包上传到root家目录。
[root@master ~]# ls
anaconda-ks.cfg mysql-5.7.32-1.el7.x86_64.rpm-bundle.tar
(3)解压缩mysql离线安装RPM包
[root@master ~]# tar xvf mysql-5.7.32-1.el7.x86_64.rpm-bundle.tar
(4)安装mysql
[root@master mysql]# ls //列出mysql的rpm安装包
[root@master mysql]# rpm -ivh --nodeps mysql-community-server-5.7.32-1.el7.x86_64.rpm //依次将所有安装包安装完成
[root@master mysql]# systemctl start mysqld.service //启动mysql服务
[root@master mysql]# systemctl status mysqld.service //查看mysql服务状态
看到active (running)状态说明mysql正常启动,正在运行。
2、配置mysql数据库
(1)查看初始mysql数据库密码
初始的mysql数据库密码在/var/log/mysqld.log这个文件里,可以用命令grep 'temporary password'/var/log/mysqld.log,可以获取密码。
[root@master mysql]# grep 'temporary password'/var/log/mysqld.log
2021-03-31T05:19:00.608351Z 1[Note] A temporary password is generated for root@localhost: VMgIS>=n7TPF
红色标记的VMgIS>=n7TPF,就是mysql数据库初始密码。
(2)登录mysql数据库
[root@master ~]# mysql -uroot -p //登录mysql数据库
Enter password://在此处输入mysql数据库初始密码
mysql>
退出mysql的命令是:
mysql>\q
[root@master ~]#
(3)修改mysql默认登录密码
第一步需要修改/etc/my.cnf配置文件,使数据库免密登录
[root@master ~]# vim /etc/my.cnf
保存后,重启mysql服务
[root@master ~]# systemctl restart mysqld.service
再次登录mysql
[root@master ~]# mysql -uroot -p
Enter password:
在输入密码出回车即可免密登录
mysql> update mysql.user set authentication_string=PASSWORD('hadoop') where User='root';//将mysql登录初始密码设置为hadoop
Query OK,1 row affected,1 warning (0.00 sec)
Rows matched:1 Changed:1 Warnings:1
mysql>\q //退出mysql
Bye
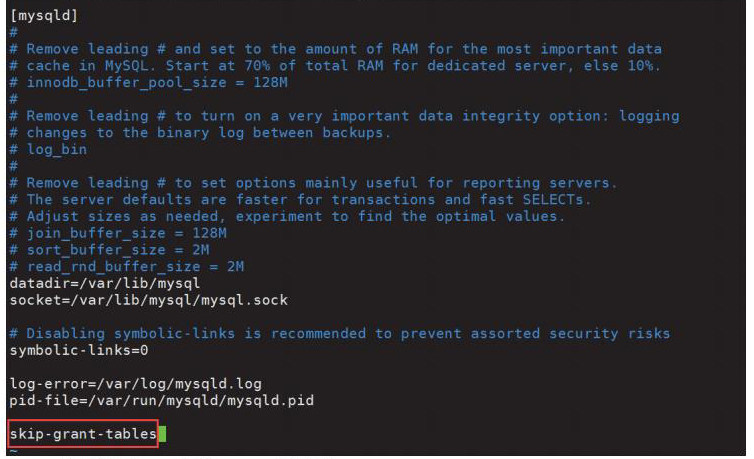
再次编辑my.cnf文件,将skip-grant-tables删除,保存文件并退出。
[root@master ~]# vim /etc/my.cnf
重启mysql服务
[root@master ~]# systemctl restart mysqld.service
再登录mysql,
[root@master ~]# mysql -uroot -p
Enter password:
输入hadoop密码即可正常登录mysql数据库。
登录后还需使用alter user修改mysql登录密码,否则使用数据库会报错
ERROR 1820(HY000): You must reset your password using ALTER USER statement before executing this statement.
mysql> alter user 'root'@'localhost' identified by 'hadoop';
Query OK,0 rows affected (0.00 sec)
(4)新建hive数据库
为了在mysql中保存hive的元数据,我们可以新建一个名为hive的数据库。
mysql> create database hive;
Query OK,1 row affected (0.00 sec)
下面我们为了能让Hive连接到Mysql,我们需要创建一个用户,并给这个用户设置一个密码。这个地方我们创建一个名为hive的用户,并给这个用户设置hive这个密码。由于我们这个用户hive的密码hive强度太低了,非常容易被破解,Mysql为了保证安全性,在创建用户时就验证密码强度,如果强度达不到要求就不允许创建。所以在mysql中,有一组参数validate_password插件应运而生。如果这里我们不修改validate_password相应参数,则无法创建hive用户。
可以通过show variables like 'validate%';来查看参数情况
mysql> show variables like 'validate%';
这个参数用于控制validate_password的验证策略
0-->low 1-->MEDIUM 2-->strong。
002、validate_password_length密码长度的最小值(这个值最小要是4)。
003、validate_password_number_count 密码中数字的最小个数。
004、validate_password_mixed_case_count大小写的最小个数。
005、validate_password_special_char_count 特殊字符的最小个数。
006、validate_password_dictionary_file 字典文件
这里有两个重要参数:
validate_password_length,validate_password_policy
我们需要将这两个参数值进行修改。
mysql>set global validate_password_policy=0;
mysql>set global validate_password_length=2;
这样我们就可以创建用户hive和这个用户的密码hive了
mysql> grant all on *.* to hive@localhost identified by 'hive';
Query OK,0 rows affected,1 warning (0.00 sec)
刷新mysql系统权限关系表
mysql> flush privileges;
Query OK,0 rows affected (0.00 sec)
mysql>\q
Bye
退出mysql,至此,mysql数据库中配置已经完成。
(5)将Mysql JDBC驱动传到root目录中
将mysql-connector-java-5.1.49.tar.gz解压缩到mysqlcon文件夹中
[root@master ~]# tar -zxvf mysql-connector-java-5.1.49.tar.gz -C /root/mysqlcon/
二、HIVE数据仓库环境配置
1、安装并配置数据仓库hive
(1)下载hive并传到/home/hadoop目录中
将apache-hive-3.1.2-bin.tar.gz解压缩
[hadoop@master ~]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz
将apache-hive-3.1.2-bin目录重命名为hive目录
[hadoop@master ~]$ mv apache-hive-3.1.2-bin hive
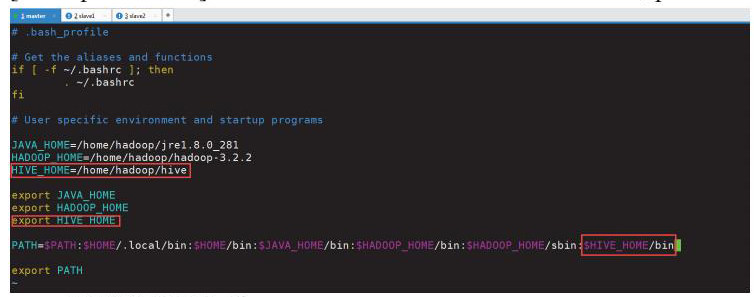
(2)配置环境变量
[hadoop@master~]$ vim .bash_profile
让环境变量生效
[hadoop@master ~]$ source .bash_profile
(3)修改hive配置文件
将hive-default.xml.template模板文件更名为hive-default.xml
[hadoop@master conf]$ mv hive-default.xml.template hive-default.xml
在/home/hadoop/hive/conf目录中创建hive-site.xml新文件,并进行如下配置
[hadoop@master conf]$ vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
</configuration>
(4)将mysql JDBC驱动程序复制到hive中
切换到root用户
[hadoop@master ~]$ su -
Password:
Last login: Wed Mar 3106:41:58 EDT 2021 on pts/1
[root@master ~]#
将/root/mysqlcon/mysql-connector-java-5.1.49目录中的mysql-connector-java-5.1.49-bin.jar
复制到hive中
[root@master mysql-connector-java-5.1.49]# cp mysql-connector-java-5.1.49-bin.jar home/hadoop/hive/lib/
以上完成数据仓库hive安装及配置
(5)启动hive
由于hive中所有的数据都是存储在HDFS中,所以我们需要先启动hadoop集群。由于我们在环境变量中做过相应配置,所以可以在任意位置直接启动hadoop集群。
启动hadoop集群:
[hadoop@master ~]$ start-dfs.sh
[hadoop@master ~]$ jps
1912 SecondaryNameNode
2168 ResourceManager
1706 NameNode
2574 JobHistoryServer
5966 Jps
启动hive:
注意:启动时若出现java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument
提示,则说明hive中依赖的guava.jar和hadoop内的版本不一致造成。
解决方案:
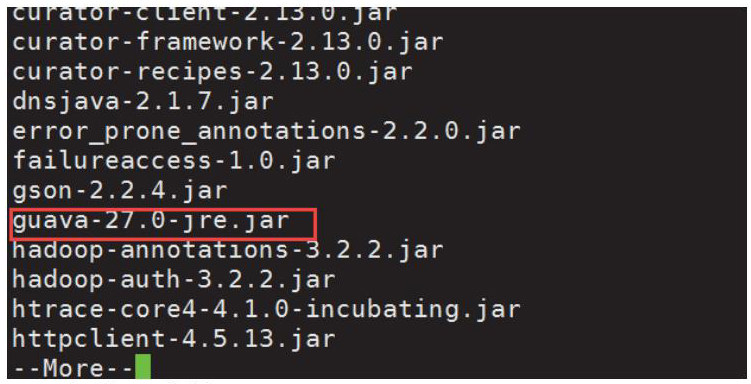
查看hadoop安装目录下share/hadoop/common/lib/目录内guava.jar
查看hive安装目录下lib目录内guava.jar的版本。
将低版本重命名为guava.jar.old,并将高版本拷贝到低版本的目录中。
查看hadoop内的guava.jar
[hadoop@master hadoop-3.2.2]$ cd share/hadoop/common/lib/
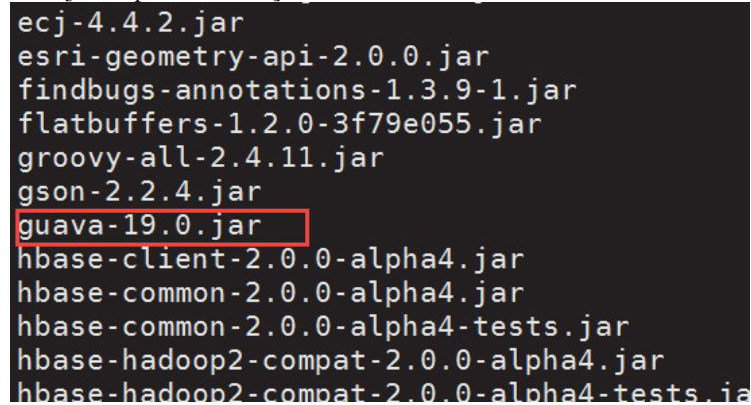
查看hive中的guava.jar
[hadoop@master ~]$ cd hive/lib/
[hadoop@master lib]$ ls
从hadoop和hive中可以对比得出,hive中的guava.jar版本低,所以将hive中的guava.jar重命名。
[hadoop@master hadoop-3.2.2]$ mv guava-19.0.jar guava-19.0.jar.old
将hadoop中高版本的guava-27.0-jre.jar复制到hive目录中
[hadoop@master hadoop-3.2.2]$ cp share/hadoop/common/lib/guava-27.0-jre.jar /home/hadoop/hive/lib/
此时可以启动hive
[hadoop@master ~]$ hive
Logging initialized using configuration in jar:file:/home/hadoop/hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
能出现hive>提示符,说明启动成功
下面测试下hive
hive> show databases;
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
以上提示分析得知:
错误原因为hive数据库MySQL在安装时没有初始化
解决方案:初始化数据库
[hadoop@master ~]$ schematool -dbType mysql -initSchema
再次启动hive:
hive> show databases;
OK
default
Time taken:0.683 seconds, Fetched:1 row(s)
hive>
通过show databases;查询数据库,有正常返回值,说明hive启动成功!
三、总结
由于HIVE需要将元数据保存在mysql中,首先需要在操作系统中完成mysql数据库的部署,本文由于在离线环境中进行问题处理和分析,读者也可根据自己情况进行在线环境的部署。数据库部署后,即可开始进行开源数据仓库HIVE的应用,开源大数据平台Hadoop采用分布式文件系统方式存储数据,而开源数据仓库工具HIVE可以使用类SQL语句的方式来分析存储在Hadoop中的数据,开源大数据平台和开源数据仓库工具在实验和科研环境中都有着很广泛的应用,方便对于大数据平台的统计分析。
参考文献:
[1]余和.自动化运维与监控的大数据平台分析[J].电子技术. 2022,51(07)
[2]靳志,成胡伟,卞雪梅.电信行业企业级大数据平台建设思路研究[J].中国新通信. 2022,24(13)
[3]符春.大数据平台聚类分析系统的设计[J].电子技术与软件工程. 2022,(13)
[4]唐燕,刘仁权,王苹.基于 Hadoop 的高校大数据平台的设计与实现[J].信息技术,2017(12):28-29.
[5]李烽谢颖.省级民政大数据平台设计与研究[J].中国信息化. 2022,(06)

 京公网安备 11011302003690号
京公网安备 11011302003690号


