



- 收藏
- 加入书签

基于机器视觉的铁路设备分类研究
 打开文本图片集
打开文本图片集

摘要:铁路设备的准确分类是铁路系统日常检测极其重要的一个环节。本文通过机器视觉产品将被摄取目标转换成图像信号,通过图像预处理提高图像设备特征,对从网络上获取的5类铁路设备图片进行分析、处理并制作成了训练数据集和预测数据集,建立了基于LeNet-5型卷积神经网络模型来实现对铁路设备的识别。采用MATLAB编程实现设计模型的分类仿真及验证,基于仿真和预测结果,可知设计模型能够对铁路设备图片进行有效识别。
关键词:铁路设备,机器视觉,深度学习,LeNet-5卷积神经网络
引言
铁路作为我国基础性、全局性、战略性的重大基础设施和重要基础产业,正在产生释放巨大的经济社会效益,具有强劲的发展潜力和强大的带动作用。虽然我国铁路取得了令人称叹的进步,但一些铁路关键核心技术尚未完全自主可控,基础理论研究与前沿引领、现代工程及应用型技术创新还不深入,信息化智能化水平还不高[1],尤其是在相关设备的检修过程中,传统的检修方式受人为因素影响较大。因此铁路设备与人工智能、机器视觉的结合需要给予重视。目前对铁路设备识别的方法主要有:设施设备分类编码、基于射频技术感应、X 射线[2]分类等。但上述方法有以下缺点:识别过程繁琐、获得信息不直观、准确度受外部影响较大等。相关技术的研究和发展更为迫切。
因此,寻找快速准确的设备分类方法有很大的必要,这有助于图像分析研究工作,可为铁路部件检测、维护等研究工作提供智能化的解决方法,具有切实研究应用价值。这为我们基于机器视觉的铁路设备分析的深度学习奠定了基础。
1层级设计
1.1深度学习神经网络选定
自2013年R-CNN将卷积神经网络(Convolutional Neural Network, CNN)引入目标检测(Object Detection)领域以来,目标检测技术取得了长足发展,尤其是后面涌现的 Fast RCNN、YOLO、SSD 等算法,更是进一步的将目标检测引入了深度学习领域。
经过近些年的发展,基于深度学习的目标检测网络大致可分为两大类:Two-Stage类和One-Stage类。
Two-Stage 类是指将目标检测的实现分为两步:(1)产生候选区域(Region Proposal, RP):通过特定的算法,利用图像的纹理、边缘、颜色等特征信息,找到可能存在目标对象的位置框,以此来减少运算量,加快检测效率;(2)对候选区域进行分类操作和目标对象的准确定位:通过提取相应的特征,对候选区域的目标对象进行分类,同时对分类的对象进行位置校正,输出准确的目标信息(包括类别信息和位置信息),RCNN 系列是典型的 Two-Stage 类方法。Ono-Stage 类是指将目标检测过程中的目标分类与目标位置定位统一到一步完成,在分类的过程中也进行目标位置的预测。YOLO系列算法和 SSD 算法都是 One-Stage 方法的代表。
随着深度目标检测算法的不断革新,越来越多拥有高精度和高速度的检测网络不断涌现,本项目考虑到在列车行驶前景下对目标检测精度及检测速度的需要,拟采用多种经典检测算法进行实现与检验。
1.2基于LeNet-5结构的卷积神经网络设计流程
提出基于机器视觉的铁路设备分析的深度学习项目,通过建立LeNet-5型卷积神经网络模型来实现对铁路设备的识别,尝试结合 Faster R-CNN网络模型的铁路异物侵限检测算法来提高识别的精确度及基于深度残差网络(ResNet)特征的尺度自适应视觉目标跟踪算法来适应更复杂的场景,另外通过MATLAB的编程语言来实现模型的仿真和验证,最终尝试通过硬件来进行仿真及应用。为了更好的区分每种图片的类别,我们执行以下命名规则:信号机命名为‘XHJ’、转辙机命名为‘ZZJ’、控制台命名为‘KZT’、继电器命名为‘JDQ’、警冲标命名为‘JCB’。
1.3目标素材收集及处理
通过收集列车行驶前方视觉视频,并对视频转化为帧图片的形式来收集数据集。为了提高模型泛化能力,尽可能选取多个不同场景的列车行驶视频,并且要尽可能全面的涵盖目标在视频画面中的所有状态。
由于列车行驶周围环境较为单一。为了避免相邻视频帧的图像目标状态相似度过高,因此在选取的视频中每隔四帧选取一帧,并将每一帧图片重命名为0000xxxx.jpg 的格式后作为数据集,最终总共得到3722张图像作为数据集,在训练时随机选取数据集的70%,共2605张图像作为训练集;选取数据集的30%,共1117张图像作为测试集。数据集的类别可分为四类:轨道、信号机、隧道、列车。VOC2007相同的标记方式,VOC数据集是目标检测中常用的数据集,它包含 Annotation、ImageSets、JPEGImage三个文件夹。
Annotation 文件夹存放的是xml格式的标签文件,该文件是对图片的解释,每个xml文件都对应 JPEGImages 文件夹中的一张图片。 ImageSets文件夹下的Main文件夹中存放的是txt文件,将原始数据集按照一定比例分为训练集(train.txt)、验证集(val.txt)和测试集(test.txt),每个 txt文件中存放的是图片的名称。 JPEGImages 文件夹存放的是数据集的所有图片,包括训练和测试图片。
2模型设计
本文研究的是让计算机对5种铁路设备进行分类识别,这5种设备是:信号机、转辙机、控制台、继电器、警冲标。为了保证准确率,从网络上选择约25张每种设备的图片用于制作数据集,同时使用数据增强技术对部分图片进行旋转处理,最终得到了约500张图片组成的数据集。
2.1模型的层级设计
从以上论述可以发现,我们所需识别的图片不复杂,而且数据集中图片的数量也不大,所以选择LeNet-5的结构来构建模型。
(1)输入层
输入层图片的大小直接影响着整个模型的准确率和训练时间。若图片太小,则会导致损失信息较多,准确率低;若图片过大,其训练时间会增长,不利于模型的普适性。本文选择的输入图片的分辨率为56*56。
(2)卷积层1
卷积层中卷积核的大小设置为5*5,卷积核的数量暂时设为6。由于图片的边缘信息也需要利用,所以需要填充,每边填充的大小为2。根据公式:卷积后的大小=卷积前的大小+双边填充数-卷积核大小+卷积核大小与双边填充数之差可以得到卷积后每张特征图的大小仍为56。故经过一次卷积后得到了6张56*56大小的特征图。
(3)池化层1
池化层中过滤器的大小为2*2,步长为2。这样就可以把原来图片缩小至原来的1/4。经过池化层1处理后,就得到了6张14*14大小的特征图。
(4)卷积层2
卷积层2中卷积核的大小为5*5,卷积核改为16个,但不填充。由于此次不填充,故图片中每行的最后五个像素点作为一个整体参与本行的最后一次卷积运算,最后一个像素点仅参与一次运算。所以经过本层运算完后就可以得到96张10*10大小的特征图。
(5)池化层2
池化层2中过滤器的大小也为2*2,步长为2。经过处理后就可以得到92张5*5的特征图。(6)全连接层
将上一次得到的256张5*5的特征图平坦为一维向量,其长度为96*5*5=2400。所以整个神经网络的输入神经元数为2400个。由于是5分类,将平坦层的输出设置为5即可。
2.2模型设计的具体实现
(1)图片集预处理
在图片开始训练之前,由于我们的图片集是由网络图片经过增强技术处理后得到的,所以首先对图片进行预处理。本文将会将会使用到以下三种图片:500张尺寸为56*56大小的彩色图片;500张尺寸为56*56大小的黑白二值图片;500张尺寸为128*128大小的彩色图片。彩色图片只需将原图片转化大小即可,这里使用的是MATLAB中的imread、imresize以及imwrite函数。
Imread函数用于读取每张图片的存储路径;imresize函数能够在保证图片整体信息不改变的情况下按照要求的尺寸对图片整体进行放大或缩小;imwrite函数则是将处理好的图片按照指定格式和名称进行存储,其中使用图片类的大写字母来对其命名,例如警冲标命为‘JCB’。
二值黑白图片的处理过程则是在彩色图片的处理基础上加入graythresh函数、im2bw函数。Graythresh函数是确定图片的二值化阈值,im2bw函数则是将图像二值化。通过上述的图片预处理,就得到了满足训练要求的数据集。
(2)卷积神经网络各层的函数
得益于MATLAB中的Deep Learning Toolbox工具箱,卷积神经网络中各层的定义十分简洁。
1)输入层
输入层的定义通过使用imageInputLayer函数实现,需要输入的参数是图片的尺寸和颜色,“1”表示输入的是二值图片,“3”表示输入的为彩色图片。
2)卷积层
卷积层由convolution2dLayer函数实现,需要输入的参数有:卷积核的大小和数量、是否要填充以及填充的多少等。在卷积层的输出加入ReLu激活函数,增强模型的非线性能力。
3)池化层
池化层采用maxPooling2dLayer函数,传入的参数有:过滤器的大小以及步长。本文采用的网络结构为LeNet-5结构,其特点是有两层卷积层和池化层。之后的卷积层与最大池化层的设置方法与上述类似。
4)全连接层
全连接层的设置通过fullyConnectedLayer函数传入类别数即可实现。
(3)模型训练的函数实现
训练的过程使用的是trainNetwork函数,输入需要训练的数据、定义好的卷积神经网络模型等参数就可以开始训练。
(4)模型预测的函数实现
由于之前在处理图片的时候,每张图片是按照其所属的类别进行命名,所以在判定预测是否准确时,只需要将预测结果与其图片的命名进行比对即可。
3仿真分析
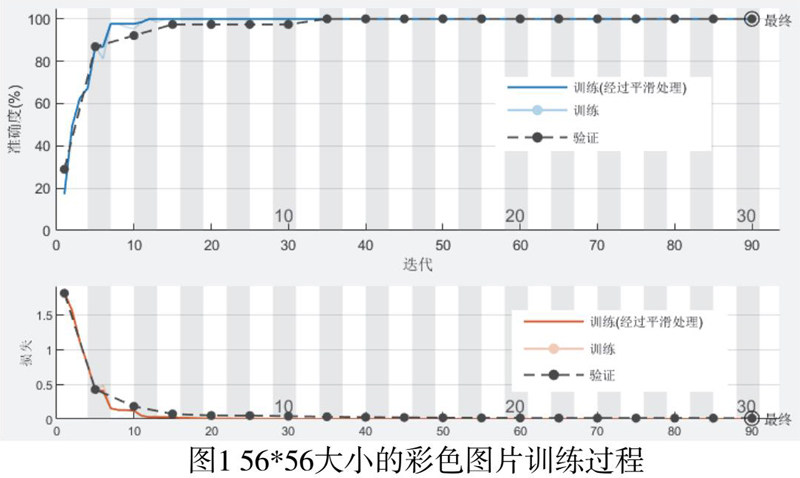
使用尺寸为56*56的彩色图片训练进行仿真在本次对仿真中将使用56*56大小的彩色图片,除了图片规格不一致外,其他参数均与第一组仿真保持相同。
如图1所示,用彩图训练的整体过程与用黑白图片训练的过程大致相似,但可以发现彩图在经过15次迭代后才趋于平稳,而黑白图片在经历13次迭代后就逐渐平稳。同时还可以看出用彩图训练时长为24秒这与黑白图所花时间相同,但其验证的准确率达到了98.46%,明显高于二值黑白图的结果。
从图2的举例可以看出:计算机识别结果与真实值相同,而且每张小图的色彩较为清晰。
4结语
在铁路系统的实际运行中,为了更好地利用铁路系统大量的维修视频、图片等资源,发挥其潜在价值。搭建了基于LeNet-5型卷积神经网络的,建立了5类典型铁路设备数据集,分别采用56*56的二值黑白图片、56*56的彩色图片和128*128的彩色图片进行仿真研究,基于分析研究结果优化了神经网络结构,并给出了测试精度和计算机测试运行时间结果。
参考文献:
[1]张宇宁.基于机器视觉的铁路道岔检测研究[D].郑州大学,2014.
[2]王雒瑶. X射线焊缝缺陷图像降维及分类检测算法研究[D].西安石油大学,2018.
[3]Fatih Demir,Abdulkadir Sengur,Varun Bajaj. Convolutional neural networks based efficient approach for classification of lung diseases[J]. Springer International Publishing,2019,8(1):1-8.
[4]董景峰,杨若怡,周康康,谢明江.机场行李提取中行李箱图像识别与旋转仿真[J].物流技术,2020,39(02):122-129.
[5]魏秀琨,所达,魏德华,等.机器视觉在轨道交通系统状态检测中的应用综述[J].控制与决策,2021,36(2):257-282.
基金项目:本科创新创业培训计划(202110150048)。
通讯作者:刘杨(1981),女,博士,副教授,主要从事智能交通方向研究。

 京公网安备 11011302003690号
京公网安备 11011302003690号


