



- 收藏
- 加入书签

基于BXG算法的企业员工离职预测
 打开文本图片集
打开文本图片集

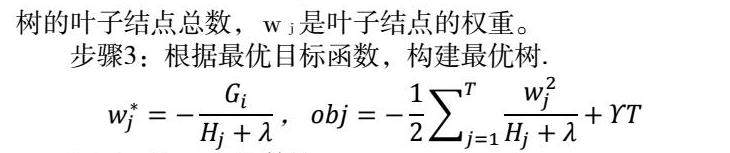
摘要:员工的非正常离职会给企业的生产经营和员工管理造成一些困扰,提前预测员工离职对企业管理是非常必要的,也为企业留人、用人提供科学依据。本文在探索简单分类、集成分类和多层感知分类的基础上,选择了分类效果较好的XGBoost算法,引入BorderlineSMOTE数据增强、GridSearchCV网络搜索改进XGBoost算法,构建了基于BorderlineSMOTE-XGBoost-GridSearchCV(BXG)员工离职预测算法,并进行实验分析,对离职员工的召回率稳定在70%以上。
关键词:离职分析与预测;数据增强;网格搜索;XGBoost
引言
员工的非正常离职会给企业的生产经验和员工管理造成一些困扰,提前预测员工离职对企业管理是非常必要的,也为企业留人、用人提供科学依据。利用大数据技术及思维实现决策科学化、管理精准化、服务人本化,通过新技术实现“聪明的服务”,精确监管,精准预测员工离职,避免优秀人才流失,为企业人才工作提供可持续发展的未来,才能真正保障企业人才结构的不断优化,从根源上推动中国经济的稳步健康发展[1]。
1.相关工作
员工离职预测一般有两类方法,一类是结合传统的统计方法,如:夏功成等根据定性仿真算法(QSIM)和员工离职行为常识、专家知识的定性模拟技术,构建员工离职过程模型,实现员工离职预测的虚拟实验研究[2],引入了人为因素,结论有一定的的主观性。二类是应用机器学习算法,如:张勇等针对特定企业历年的离职率,构建一阶一变量(GM (1,1))的灾变灰(grey-model)预测模型,预测下一次异常离职出现[3],对员工异常离职做了有效预警,缺陷是不能预测个体员工是否离职。李强等以特定企业人力资源数据为研究对象,以stacking集成逻辑回归-随机森林-adboost算法构建预测模型[4];王冠鹏等以Kaggle平台开源数据为研究对象,利用均方差和lasso模型筛选员工离职相关变量,与SVM、XGBoost、逻辑回归、随机森林四种分类算法组合训练,选择预测效果最佳的均方差变量筛选-随机森林分类组合[5];闫泓序等组合应用主成分分析-大规模数据聚类-分类与回归算法,构建基于画像的员工离职预测模型[6],二类算法的准确性较好,但都用企业自身数据。
2.模型构建
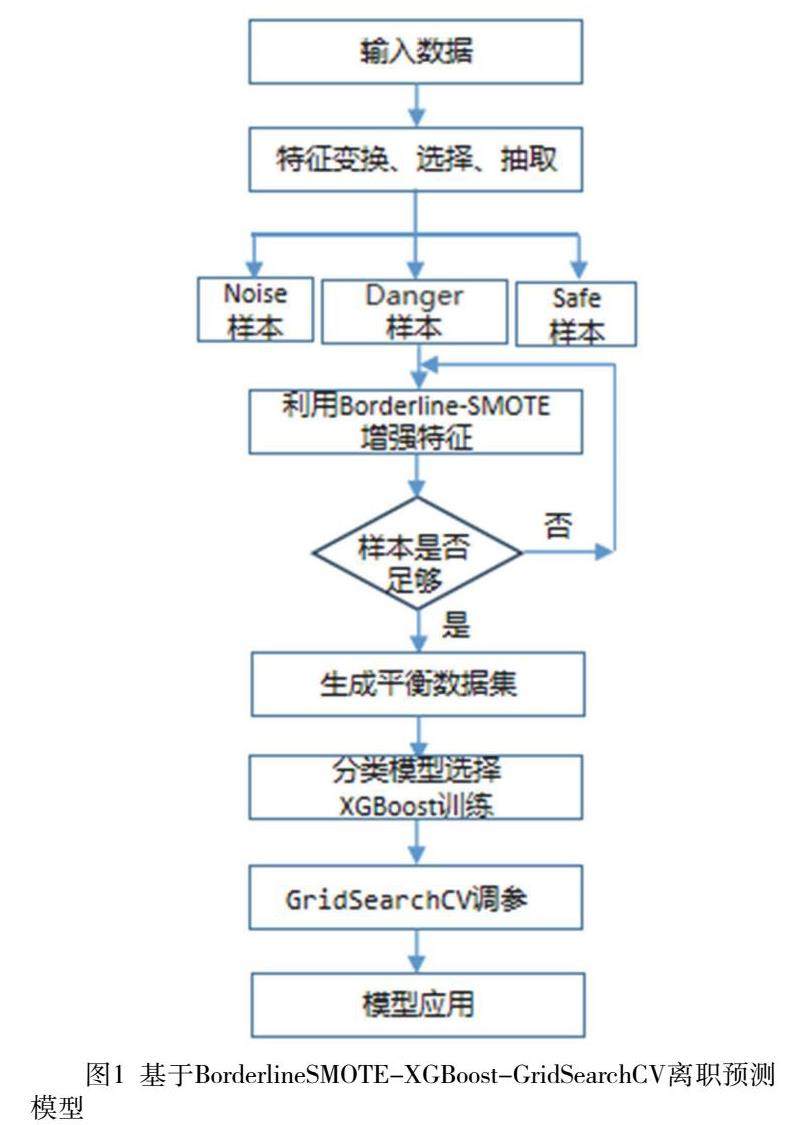
针对数据的不平衡性,在XGBoost分类算法中引入Borderline-SMOTE数据增强算法,而且XGBoost分类算法的参数多,参数的取值对分类效果有显著影响,嵌入GridSearchCV网格搜索,构建了BXG员工离职预测分析模型,如图1。
2.1 Borderline-SMOTE算法
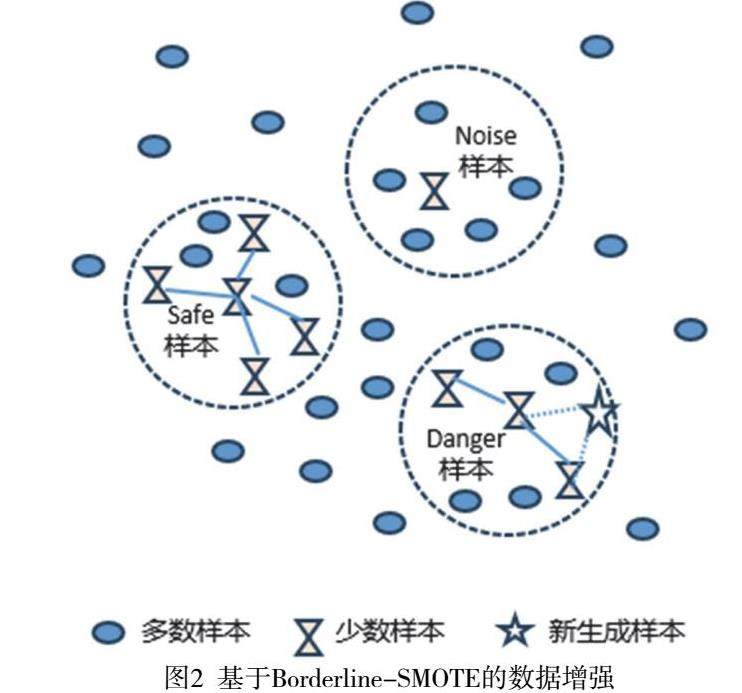
为解决数据不均衡问题,增强少数类样本,引入Borderline-SMOTE算法。Borderline-SMOTE算法(Borderline Synthetic Minority Oversampling Technique)是一种对少数类的边界样本进行线性直插合成的过采样技术, Borderline-SMOTE采样时先将少数类样本分为3类[7],如图2。
Safe样本:周围一半以上为少数类样本。
Danger样本:周围一半以上为多数类样本。
Noise样本:周围均为多数类样本。
该算法仅使用Danger类边界上的少数类样本来合成新样本,从而改善样本的类别分布。Borderline-SMOTE又可分为Borderline-SMOTE1和Borderline-SMOTE2,Borderline-SMOTE1在对Danger点生成新样本时,在K近邻随机选择少数类样本,Borderline-SMOTE2在对Danger点生成新样本时,则是在k近邻中的任意一个样本,而不关注样本类别。假定整个训练集是T,少数样本是Min,多数样本是Max,并且
Min={min1,min2, …,minmin_num},Max={max1,max2,…,maxmax_num},
min_num和max_num是少数样本和多数样本数量,实现算法的具体过程如下[8]:
(1)对少数类Min中的任一min i样本,利用KNN计算mini样本在整个训练集T中近邻样本数m和在多数样本集Max中近邻样本数m’(0≤m’≤m)。
(2)如果m’=m,mini的近邻都是多数类样本,mini属于Noise样本,终止下一步计算;如果m/2≤m’<m, ,即mini的近邻的多数类样本数多于少数类样本数,mini归类到Danger样本;如果0≤m’<m/2,mini是Safe样本,终止下一步计算。
(3)Danger样本是少数类Min的边界值,Danger ⊆Min,设定Danger={min’1 , min’ 2,…,min’dnum}(0≤dnum≤min_num),对于每一个Danger样本,计算其近邻的少数类样本数k。
(4)生成s*dnum个合成样本(1<s<k),对任一m’,利用KNN在少数类样本Min中随机选择样本,计算在min’ 和其MIN之间的变异系数difi,(i=1,2,…,s),利用公式生成合成样本:
synj= min’ i+rj*difj (j=1,2,…,s;0<rj<1)
2.2 XGBoost算法
XGBoost(eXtreme Gradient Boosting)是基于CART树(Classification and Regession Tree)的集成机器学习算法,使用梯度提上框架,将每一棵树的预测值加到一起作为最终的预测值[9]。如要预测员工是否离职,给定若干属性构造决策树推测离职概率,XGBoost算法是不断生成新的决策树T1,T2,…,Ti,如图3。
先通过最小残差学习到一个通过通话时长变化属性构建的决策树得到预测值VT1p和VT1F,再继续通过真实值与此时的预测值的残差构建下一个决策树,依次类推,当达到迭代次数上线或是残差不再减少时停止,生成由T1,T2,…,Ti的和形成的决策树,即经多次迭代的决策树的强分类器。实现XGBoost算法的4个步骤如下[10]:
步骤1:构造目标函数
每次迭代建立一个新的决策树并减少残差,其目标函函数:
目标函数的第一部分是损失函数,n为样本数量,第二部分是表示树结构的复杂性的正则项,由K棵树正则化而生成。
步骤2:将目标函数进行泰勒二阶展开,将树结构引入目标函数,目标函数参数化,第t棵树的优化目标:
Ij是一个集合,结合中每个值代表一个系列样本序号,整个集合就是被t棵树决策树分到了第j个叶子节点上的训练样本,λ是叶子结点权重的超参数,γ是控制叶子结点个数,T代表回归树的叶子结点总数,wj是叶子结点的权重。
步骤3:根据最优目标函数,构建最优树.
2.3 GridSearchCV算法
XGBoost模型包含了20余个参数,引入GridSearchCV算法优选参量变量,进一步优化XGBoost分类模型。GridSearchCV算法包含网格搜索(GridSearch)和和交叉验证(Cross Validation,CV),网格搜索是在指定的参数范围内,按步长依次调整参数,遍历所有可能参数的组合利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数;交叉验证用于防止模型过于复杂而引起的过拟合,将数据样本切割成较小训练集和验证集,分别用于模型训练和结果测试,GridSearchCV算法实现步骤[9]:
(1)构建待调参数字典,构建分类模型中所有需要调整的参数及其可选取值。
(2)定义分类器,将需要调整的参数放入分类器中,得到一个对象clf,该对象将作为网格搜索的基础,以此来调整参数。
(3)建立网格搜索对象,构建GridSearchCV对象,处理多种参数、交叉验证的网格搜索器,同时并行化搜索,寻找最优参数。
(4)评估模型性能,使用所获得的最优参数对模型进行训练和评估,得到测试集的正确率或其他指标,进一步寻找改进该模型的方式。
3.数据处理与结果讨论
3.1数据预处理
(1)无效值处理
性别、籍贯、用户星级等终端属性用中位值替代。
终端型号、终端品牌、终端操作系统等通过获取年龄、职业、属地、在网时长等相同的其他用户对应字段替代。
是否已婚、是否有老人、是否已育以零替代缺失值(0表示否)。
通话数据集中的应用名称、应用分类,非空仅占约1%,值太少,直接丢弃。
通话数据集中的“对端归属长途区号”为空的记录,“漫游类型”字段的内容为本地或国际漫游出访,为本地时,长途区号设为本地区号,为国际漫游时,长途区号设为国际漫游号。
用户个人属性表(DataTech_Resign_Train_Attr)中的字段籍贯(ORIGIN)、性别(SEX)存在非法值-99、用户星级字段等非法值处理。
(2)数据匹配
时间不匹配:基础数据集(属性、通勤、消费)的时间是5月份,用户基本信息数据是4月份,这两个数据集一人一条,通话、上网、轨迹为4月的,且一人多条。
用户数不匹配:数据为10000用户,公共数据集约20000(每个数据集包含不同的用户数。
(3)日期处理
根据记录具体时分秒,判断在各个时段内用户的活动情况,比如是工作时间通话多一点,还是在深夜通话多一点,以此刻画用户是商务人士还是夜猫一族等。
(4)数据拼接
根据user_id横向拼接各个数据集,把一个用户id对应多条记录变换成对应一条记录。形成有效的训练数据集,每个user_id有39个变量。
3.2特征构造与选择
(1)特征变换
户个人属性从职业类别、是否高薪职业、薪酬级别、学历级别、退休或在职状态等角度变换数据。
业务使用数据从通话时长级别、通话时长平均时间、主叫时长、被叫时长、未接通电话次数等角度变换数据
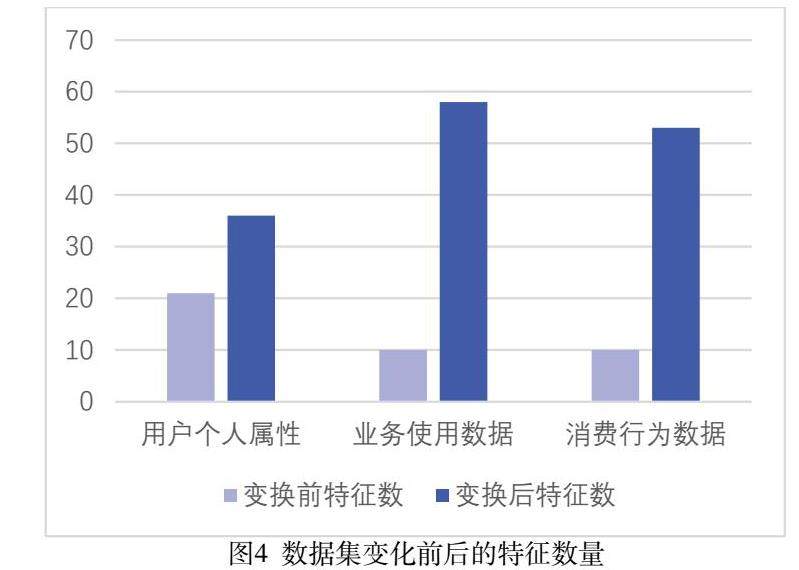
消费行为数据从每月、上月、上上月、累计三个月的出账费、流量费用、通话费用;三个月的出账费、流量费用、通话费用等角度变换数据。数据集特征变换前后的数量如图4。
特征数由41增加到147,考虑到每个数据集都有重复的user_id,'USER_FLAG'、'CITY_ID'、'COUNTY_ID'、'INCOME_LEVEL_ID'等7个无效特征,12个特征的值为空,实际特征数量是127个。
(2)特征选择
为避免维度灾难、降低学习难度、减少过拟合、增强对特征和特征之间的理解,而且并不是所有特征对结果都有显著效果,有些特征可能影响模型性能。采用基于统计的selectbest()方法和f_classif样本方差F值检测,通过对每一个特征进行统计分析,计算出特征之间的关联程度,从高到低排序,选择前K个特征训练模型。
(3)特征标准化
不改变数据的分布情况,为无量纲化各个特征维度和消除数据横向差异(即特征间差异),采用StandardScaler()标准化方法对特征进行处理,标准化之后的特征值在-1~1之间。
3.3特征增强
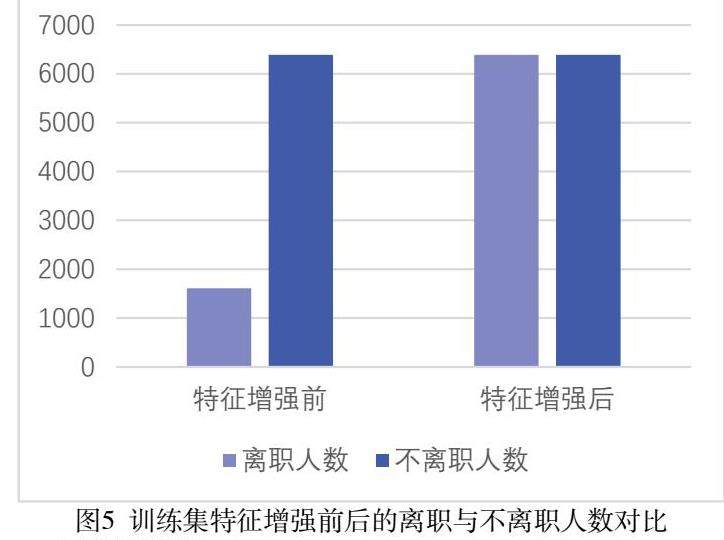
机器学习模型训练要足够比例的数据集才能实现较好的拟合或减小过拟合。总体样本中离职与不离职人数分别是2023人和7977人,两者比例是0.25,一个严重不平衡二分类问题,需要增加少数样本数据的数据量,确保离职样本与不离职样本数平衡。将数据集随机排列,80%划归为训练集,20%划归为测试集,对训练集用Borderline-SMOTE算法进行数据增强,实现了离职样本与不离职样本数据量平衡,如图5。
3.4分类算法
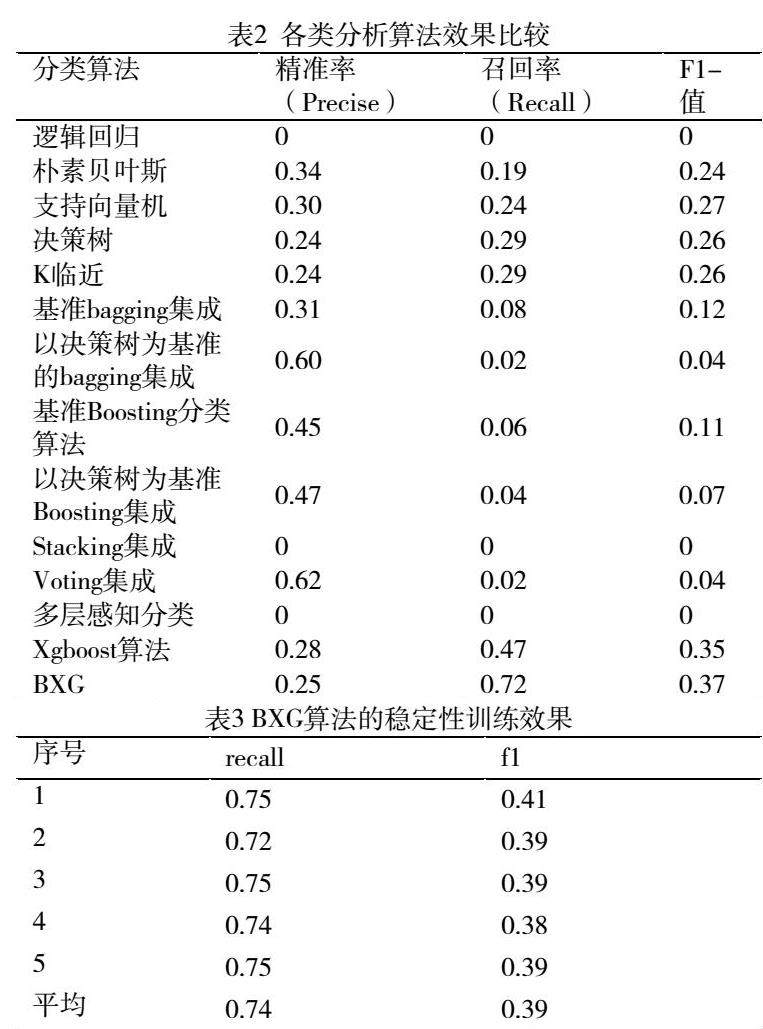
评价分类效果的指标precision、 recall、f1-score、AUC 、accuracy_score等指标中,预测员工离职最重要的指标是recall和f1值,尽可能发现预离职的员工。本文分别使用逻辑回归、朴素贝叶斯、SVC、决策树、K临近等简单分类;基准Bagging分类、以决策树为基准的bagging集成分类;基准boosting集成分类、以决策树为基准Boosting集成、xgboost等boosting集成分类;Stacking集成分类;Voting集成分类;神经网络(MLPClassifier)分类算法,各类分类算法效果如表2。
从表2中可知,逻辑回归、Bagging集成算法、Boosting集成算法、Stacking集成算法、Voting集成算法的召回率和f1值较小,分类效果差;朴素贝叶斯、支持向量机、决策树、K临近4个简单分类算法效果其次;Xgboost算法的召回率和f1值分别为0.47和0.35,分类效果先对较好。
通过BorderlineSMOTE数据增强和GridSearchCV参数优化进一步改进算法,
XGBoost参数网格搜索结果: n_jobs=4;cv=5;learning_rate =0.1;n_estimators=177;max_depth=3;min_child_weight=3;gamma=0.2;subsample=0.9;colsample_bytree=0.7;reg_alpha=100;objective='binary:logistic',nthread=4;scale_pos_weight=1,seed=27);param_grid = param_test7;scoring='roc_auc'。对训练样本按2:8交叉验证,BXG算法召回率0.74,f1值0.39,5次随机验证结果稳定,如表3。
4.结语
以往员工离职预测数据存在采集难及数据样本不均衡等问题,本文利用员工个人属性数据和手机通讯消费数据,在数据整合、特征构造、筛选、缩放和特征增强的基础上,初步探索简单分类、集成分类和神经网络分类等,选择了分类效果好的XGBoost算法,引入基于过采样BorderlineSMOTE数据增强和GridSearchCVGridSearchCV网络搜索改进XGBoost算法,构建了BorderlineSMOTE-XGBoost—GridSearchCV算法,并进行实验分析,对离职员工预测效果稳定。
参考文献:
[1]人力资源社会保障部.《“互联网+人社”2020行动计划》(人社部发〔2016〕105号)〔DB/OL〕.http://www.mohrss.gov.cn/xxgk2020/fdzdgknr/zhgl/rlzyshbzxxh/202010/t20201031_394112.html,2016-11-01
[2]夏功成,胡斌,张金隆.基于定性模拟的员工离职行为预测[J].管理科学学报,2006,9(4):81-89,92.
[3]张勇,巩天雷,张玉忠.基于灾变灰预测的企业雇员离职预警模型研究[J],数学的实践与认识,2008,38(20):72-76.
[4]李强,翟亮.基于Stacking算法的员工离职预测分析与研究[J],重庆工商大学学报(自然科学版),2019,36(1):117-123
[5]王冠鹏,秦双燕,催恒建.员工流失的影响因素分析与预测[J],系统科学与数学,2022,42(6):1616-1632.
[6]闫泓序.余顺坤基于画像的员工离职预测模型研究[J],中国管理科学,2022,30(12):16-26.
[7]潘正军,赵莲芬,袁丽娜,王红勤.基于 Borderline-Smote 算法改进的 FastText 中文情感极性分析[J],计算机应用与软件,2021,38(11):295-299.
[8]Han H, Wang W, Mao B. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning, Lecture Notes in Computer Science (2005),3644(PART I):878-887
[9]陈浩男,高雪莲.基于XGBoost和网格搜索的变压器油中溶解气体含量预测[J],河北师范大学学报(自然科学版),2022,46(6):576-581.
[10]贾颖,赵峰,李博,葛诗煜.贝叶斯优化的 XGBoost 信用风险评估模型J/OL].计算机工程与应用,https://kns.cnki.net/kcms2/detail/11.2127.TP.20230626.1704.002.html,2023-06-27.
作者简介:
陈昊 1990,女,浙江杭州,中电海康集团有限公司,硕士,研究方向:项目管理。

 京公网安备 11011302003690号
京公网安备 11011302003690号


