



- 收藏
- 加入书签

橡树岭国家实验室对机器学习应用于核材料衡算与控制领域的探索
 打开文本图片集
打开文本图片集
摘要:随着计算能力的快速发展,机器学习算法在多个应用领域展现了巨大的优势和潜力。核材料衡算与控制过程中产生的数据具有维度多、数量大的特点,这种丰富的异构数据集适合利用机器学习算法分析,通过选择合适的数据处理方法与机器学习模型,有望实现对新数据的快速准确分类和对异常数据的自动检测。本文介绍了橡树岭国家实验室在核材料衡算与控制领域应用机器学习算法的探索。
关键词:机器学习;主成分分析;K均值聚类;衡算与控制
1. 引言
机器学习算法通过利用已有数据对选定模型进行训练,并利用训练后的模型对新数据进行快速预测分类。其中用于训练的数据的质量、模型的选取和模型参数设置都会影响最终的预测效果。核材料衡算与控制产生的数据覆盖较长流程,包含多种数据类型,数据维度较多;衡算数据完整记录了每一批材料的转移与变化,数据数量较大。这些结构特点使得机器学习算法可以被用于分析核材料衡算与控制数据,通过合适的数据处理、模型选择与参数设置,有望实现对新数据的快速准确分类和对异常数据的自动检测,大大简化衡算过程、缩短衡算时间。基于近年来计算能力和大数据技术的快速发展以及机器学习算法的广泛应用,国际原子能机构保障监督部在2018年发布的“研究和发展计划”中也提出了“探索全新数据分析方法”的规划[1]。
为了探究机器学习算法在核材料衡算与控制领域的应用,美国橡树岭国家实验室(ORNL)基于其相关单位在核材料后处理过程中产生的衡算数据,利用主成分分析(PCA)、K均值聚类算法、Q残差分析等方法进行分析,试图训练模型来实现对数据的自动分类和异常检测[2]。本文简要介绍了相关算法的基本原理及ORNL的研究结果。
2. 数据来源
ORNL的高通量同位素反应堆(HFIR)是美国用于研究的最高通量反应堆中子源。HFIR的主要任务之一是同位素生产,其中包括为深空探测任务生产238Pu。毗邻HFIR的放射化学工程发展中心(REDC)是一个高放射性物质工作屏蔽设施,用于制备同位素生产过程中所需的靶和开展靶的辐照后处理。在238Pu的生产过程中,Np靶首先在REDC生产,然后转移到HFIR中受辐照,最后被转移回REDC进行后处理以提取238Pu。
局域网材料衡算系统(LANMAS)是美国能源部用于监测和衡算现场特种核材料的软件程序。只要发生可报告的“事件”,就会向LANMAS输入记录。ORNL提取了HFIR和REDC中与238Pu生产相关的所有事件记录,产生了一个有约10000个条目,对应约2500个独立事件的数据集。
3. 相关机器学习算法及应用
为了理解LANMAS数据库由哪些典型的事件类型构成,首先将数据库作为一个整体来考虑,使用PCA来发现数据的结构特点(即主要分布趋势),并对数据进行“降维”。随后将K均值聚类算法应用到这个降维数据中,实现对数据的自动分类,并通过检查原始数据库中与每个分类相对应的具体条目来确定这些分类所对应的实际事件类型。最后,为了观察真实数据与异常数据间的区别,在数据库中主动引入多种类型的异常数据,并计算真实数据与异常数据各自的Q残差值进行对比。
3.1 主成分分析
PCA可以在尽可能保留数据原始信息的基础上降低数据集的维度。以最简单情况为例,将一组二维数据降维成一维数据。原始二维数据结构中,PCA的目标是选择一条直线,用二维数据在该直线上的投影来近似表示原始二维数据,该直线需要满足两个性质[3]:
最近重构性:原始数据到这条直线的距离都足够近;
最大可分性:原始数据在这条直线上的投影尽可能分开。
具体来说,最近重构性要求通过该直线表示的数据相较于原始数据具有最小的误差,即最大限度保留原始信息;最大可分性要求原始数据在直线上的投影具有最大方差,即尽可能反映出数据间的差异。
显然,低维空间与原始高维空间必有不同,因为对应于最小的d-k个特征值的特征向量被舍弃了,这是降维导致的结果。但舍弃这部分信息往往是必要的:一方面,舍弃这部分信息之后能使样本的采样密度增大,这正是降维的重要动机;另一方面,当数据受到噪声影响时,最小的特征值所对应的特征向量往往与噪声有关,将它们舍弃能在一定程度上起到去噪的效果[3]。
LANMAS数据库中的每组数据包含47个维度,这些维度构成了与238Pu生产活动全流程相对应的数字信息或分类信息。为了将该数据应用于机器学习,我们首先需要对其中的分类信息(即非数字信息)应用一次性编码,将其转化为数字信息。
通过对原始数据集中的9816个数据进行PCA降维,可以在三维空间下发现明显的聚类结构,具体结果如下节所示。
3.2 K均值聚类分类
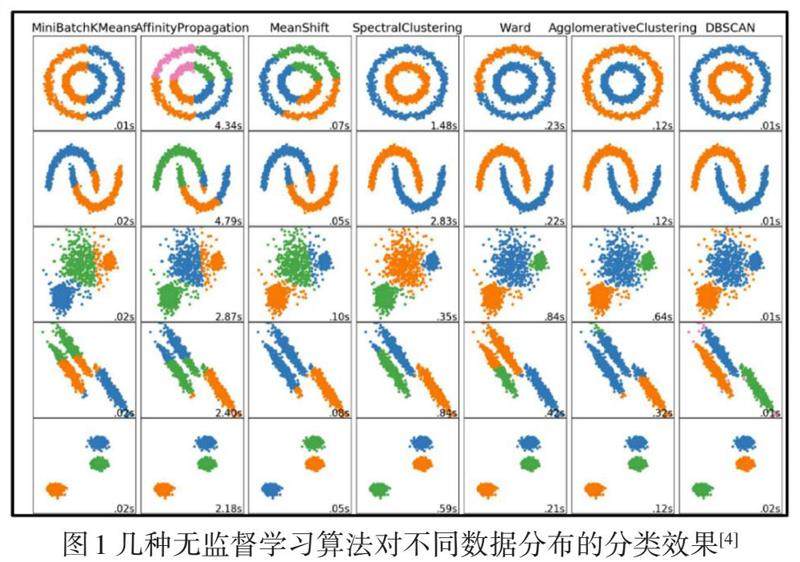
机器学习根据训练数据的构成具体可分为监督学习(supervised learning)和无监督学习(unsupervised learning)。监督学习指输入的数据除“特征”(feature)外同时包含该组数据的“标签”(label)或“分类”(classification)。例如,通过训练卷积神经网络来识别图像中的物体,需要输入数据集包含每组数据的标签(如停车标志、汽车、椅子、人等)。相对应的,无监督学习是指输入的数据仅包含特征而不包含分类信息,但可以通过多种算法对输入数据进行自动“聚类”(clustering),部分无监督学习对不同数据分布情况的聚类效果如图1所示。
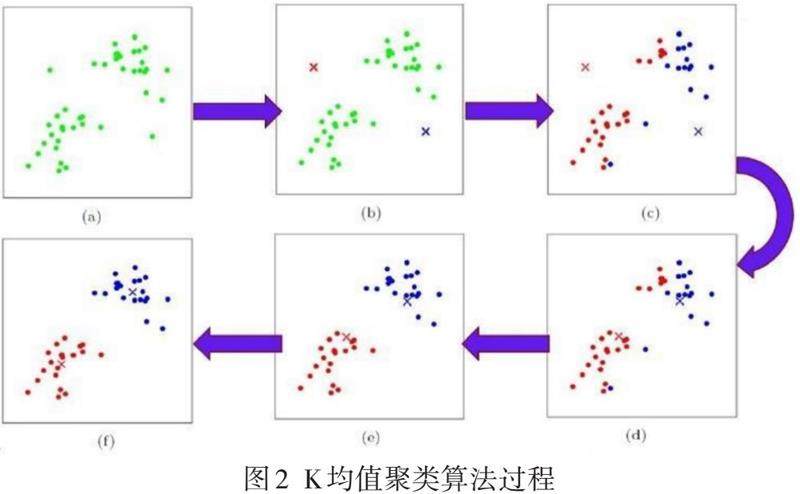
核材料衡算与控制中产生的数据不包含标签或分类,因此属于无监督学习。这里选择使用K均值聚类算法(k-means clustering algorithm)对其进行分析。K均值聚类算法是一种迭代求解的聚类分析算法,其步骤是:
(1)预先将数据分为K组,随机选取K个对象作为初始的聚类中心;
(2)计算每个对象与各个聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心,聚类中心以及分配给它们的对象就代表一个聚类;
(3)每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算;
(4)不断重复过程2和3直到满足某个终止条件。
终止条件可以是:
a)没有(或最小数目)对象被重新分配给不同的聚类;
b)没有(或最小数目)聚类中心再发生变化;
c)误差平方和局部最小。
K均值聚类算法的过程如图2所示。
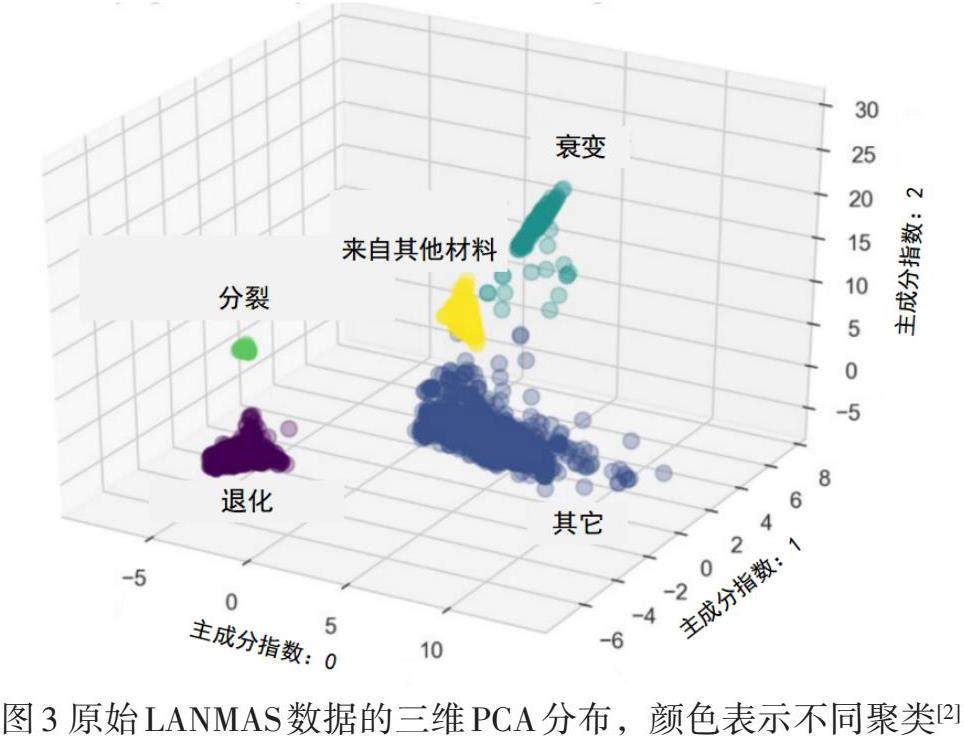
原始数据经过三维PCA和K均值聚类后得到结果如图3所示,颜色表示不同聚类,所有数据可以大体上分为5个聚类,通过观察每个聚类中的典型数据,可以得出每个聚类对应的具体过程,分别为“衰变”、“来自其他材料”、“分裂”、“退化”和“其他”。图中可以看到,“分裂”事件在图中非常集中,这是由于不同分裂事件具有相同的种类和性质,而“衰变”事件在图中占据相对较大的范围,这说明在238Pu生产过程中,有多种典型的衰变过程被记录下来。
3.3 Q残差分析
从原理上讲,原始数据与通过PCA投影得到的数据间的Q残差值应该较小,因为PCA算法是在降低数据维度的同时维持最小的信息损失。在此基础上推论:如果新数据与训练集数据来源于相似的分布,那么其原始数据与重构数据之间的Q残差值应该较小,反之,则新数据可能与训练集数据具有不同分布,新数据可能存在异常。
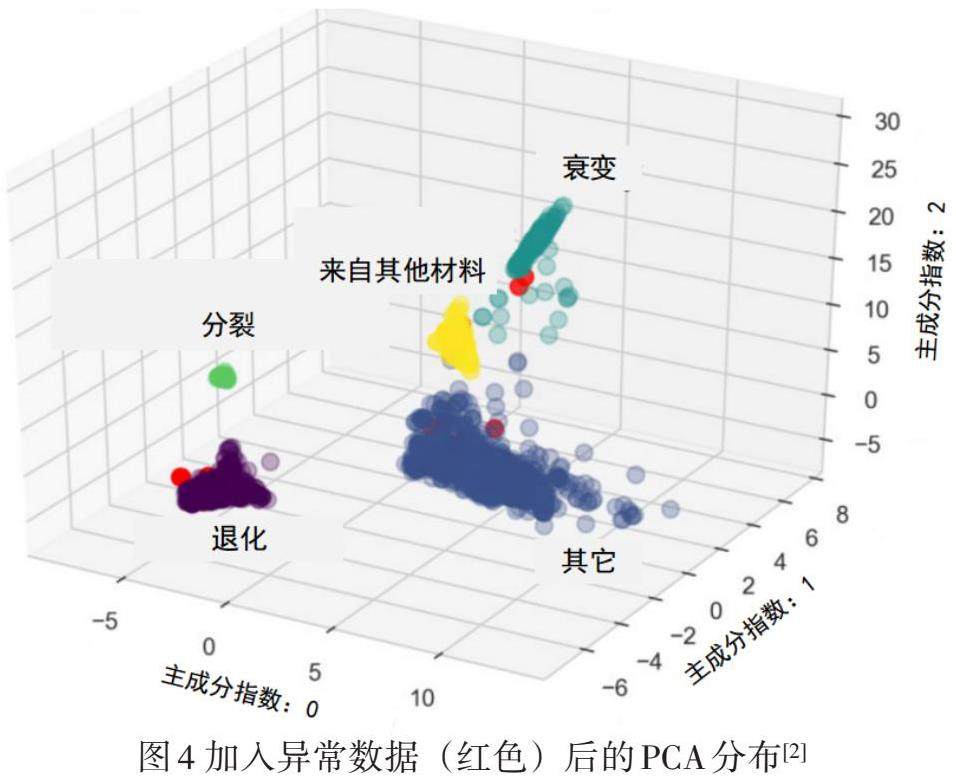
为了验证这一结论,首先对原始数据进行处理,使每个数据存在20%的概率发生三种错误之一:替换错误、书写错误、小数点错误。其中替换错误通过记录错误的质量平衡区名称实现,书写错误通过随机替换条目中的一位数字实现,小数点错误通过在包含小数点的条目中随机移动小数点实现。考虑到大多数过程中一次出现多个错误的事件发生概率较小,因此这里假定同时只发生一种错误,错误概率分别为:34%替换错误、33%书写错误、33%小数点错误。
新的数据经过PCA降维后的分布结果如图4所示,其中异常数据标记为红色。可以看到,真实数据与异常数据之间无明显分布差异。为了进行异常检测,还需要进行进一步的分析。
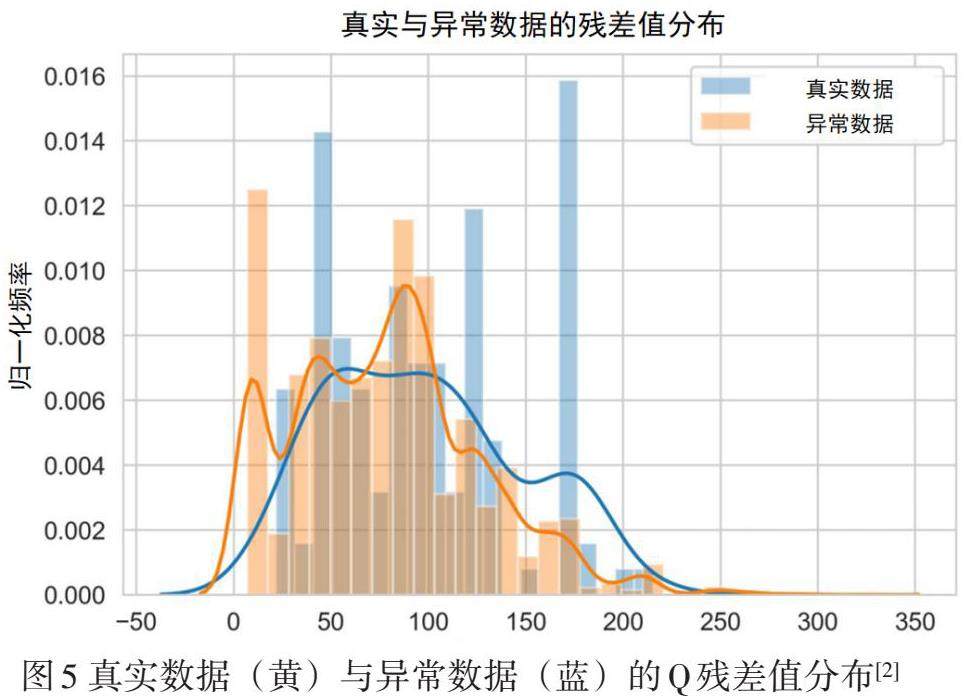
真实数据与异常数据的Q残差值分布如图5所示,条形图表示每个Q残差值的归一化频率,曲线显示这些分布的平滑近似。结果表明,异常数据的Q残差值有所增加,但整体分布具有较大重叠且不易区分。值得一提的是,异常数据中某些Q残差值出现频率较高,如45、130和175,这可能与经过PCA后得到的聚类结构有关。结果表明无法简单通过Q残差值的对比来判断单个数据是否存在异常,但异常数据的Q残差值相较于真实数据具有统计结果上的变化,这表明可能可以通过别的方法对两者加以区分。
4. 总结
ORNL的研究结果表明,PCA算法可以对衡算数据加以简化,简化后的数据在三维空间中观察到明显的聚类结构,并可通过K均值算法加以分类。然而结果表明利用Q残差分析无法判断单个数据是否存在异常。未来可以从多个角度去改进探索,如采取更加科学细致的数据处理方法、选用更加复杂准确的学习模型等。
参考文献
[1]International Atomic Energy Agency Office of Safeguards "Research and Development Plan: Enhancing Capabilities for Nuclear Verification" STR-385 (2018).
[2]Drescher A, Adams M B, Stewart S, et al. Machine Learning Approaches for Nuclear Material Accounting Data from Irradiation and Reprocessing[R]. Oak Ridge National Lab.(ORNL), Oak Ridge, TN (United States), 2020.
[3]周志华. 机器学习[M]. 清华大学出版社. 2016.
[4]Shoman N, Cipiti B B. Unsupervised Machine Learning for Nuclear Safeguards[R]. Sandia National Lab.(SNL-NM), Albuquerque, NM (United States), 2018.

 京公网安备 11011302003690号
京公网安备 11011302003690号


