



- 收藏
- 加入书签

基于SVM的货币行业股票价格预测
 打开文本图片集
打开文本图片集


摘要:本文通过SVM算法对数字货币行业的股票价格进行深入分析,由于我国现阶段把区块链作为重点发展的对象,而数字货币与区块链有着紧密的联系,数字货币行业受到了投资者的普遍关注。本文基于SVM算法进行股票价格的预测,以处理好的数据为基础,设立特征向量,通过不断地数据调整,对模型进行优化及检验,最终建立起本文的模型。其中本文所采用的数据经过标准化和归一化的处理;特征向量是依据收盘价、开盘价、最高价和最低价而建立的;模型优化的指标为均方误差MSE,优化的参数是惩罚系数C和核函数的gamma,通过不断的调整,最终选取出均方误差最小的C和gamma,建立起本文的模型。本文建立的模型为C=1,gamma=2,此模型的均方误差为0.001971316。选取好模型之后,使用模型进行分析预测,并将预测的股票价格与真实的价格进行比对,得到两者之间的相关系数为0.993。
关键词:支持向量机(SVM);数字货币;股价预测;量化投资
绪论
在股票发展的几百年中,人们对于股票的价格分析一直保持着极大的兴趣。进入到二十一世纪,人们的物质生活水平显著提高,留有更多的资金去投资,而股票就被视为一个良好的投资工具。在中国,股票的发展也有三十来年,有过牛市也有过熊市,而国人对于股市的热情却越来越高。
传统的股票分析方法有技术分析和基本面分析,虽然这两种方法在我们分析股票时被广泛应用,但根据有效市场假说理论看来,如果市场是半强势有效市场,技术分析和基本面分析都会失效。
为了进一步分析股票价格,经济学家使用计量经济学和统计学的方法来构建模型,但这些模型没有考虑到投资者的主观行为,所以在预测短期股票价格的时候,常常会“失灵”。
近年来,机器学习逐步进入大众的视野并成为许多金融工程师分析股票价格的利器,它能解决很多传统方法不能解决的问题。机器学习的基本分类是监督学习和无监督学习,两者之间最主要的区别就在于监督学习一定要有训练集和验证集;而无监督学习则只有一组数据,在这组数据中寻求规律,在现实生活中我们主要使用的是监督学习来预测股票的价格。监督学习从训练集中训练出一个模型,然后运用训练好的模型去预测股票的价格。根据结果的好坏可以不断地修改模型,从而提高模型的可信度,更好的预测价格。
一、国内研究成果
李辉等人在2017年提出一种两层特征选取及预测的方法,第一层特征选取高效剔除部分非预测相关特征,缩减了特征规模,第二层选择出最优特征组合,提升了模型的预测准确率。黄同愿等人在2018年中通过选择最优的径向基核函数,利用网格寻参遗传算法和粒子群算法对最佳核函数参数进行对比寻找最优的模型,构建的SVM 模型能够准确的预测股票的反转点。张贵生等人在2019年提出近邻互信息特征选择的SVM-GARCH模型,通过近邻互信息的方式融合了与目标指数数据关系密切的周边证券市场的相关变化信息,其结果表明在时序数据除噪,趋势判别以及预测的精确度等方面均优于传统的ARMA-GARCH模型。
二、国外研究成果
Trafalis.T和Ince.H在2008年中利用支持向量回归预测模型对股票的价格进行了分析预测,并和 MLP和ARMA进行对比分析,得出SVM的预测精确度远高MLP和ARIMA的预测精确度。KhemchandaniR 和chandras在2007年中在时间序列方面提出了利用正则最小二乘模糊支持向量回归算法来处理股价预测,由于时间序列的样本信息具有时差性,不同的时间它的信息有效程度是不一样的,时间越近的样本所带信息量更有效,因此对近期的数据样本采取更高的权重。
不管是国内还是国外,都使用了支持向量机对股票的价格进行分析预测,并且随着机器学习的发展,还出现了算法结合的情况。但是不同的国家实际情况不同,我们要结合每一个国家的具体情况,运用机器学习进行分析。
三、支持向量机概述
支持向量机(Support Vector Machine),简称为SVM,是Vapnik等人在1992年提出来的。它是一类可以用于分类和回归的模型。它的流行主要归于两个方面:一方面,它的结果比较准确;另一方面,它建立在比较优雅的数学理论。支持向量机以VC维理论和结构风险最小化原则为基础,在解决小样本、高维度、非线性等分类问题中具有独特的优势。
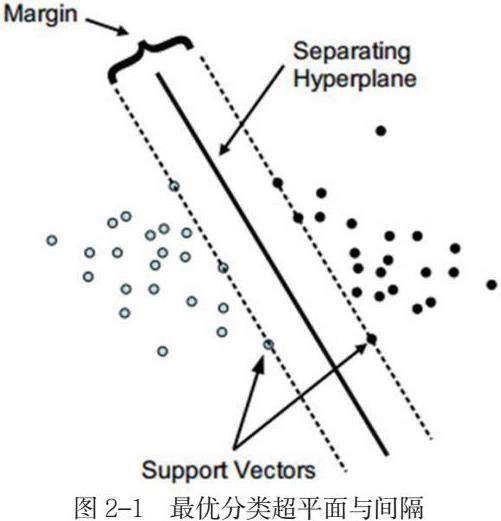
SVM的基本思路就是找到一个将全部样本分为两类的最优平面。这一个最优平面的要求就是正确的将样本分类,并且两类样本中距离平面最近的点的间距要达到最大。当样本是线性可分的,那么就可以直接寻找到一个最优的分类面;当样本是线性不可分的,那么就需要引入核函数,将低维数的样本映射到高维的空间中,使得样本线性可分,继而找到最优的分类面。如图2-1中所示,中间的黑色实线就是要找的最优平面,而图中的支持向量(Support Vectors)则是由两类分类样本中距离最优平面最近的点所组成的平面,它们与最优平面平行。
支持向量机的算法流程:首先可以将数据分为线性可分和线性不可分的情况。对于线性可分的情况,假定我们拥有的数据集为(Xi,Yi),i=1,2…n,X∈Rd,Y∈{-1,1},分类函数的一般形式为f(x)=w·x+b,分类超平面的函数为w·x+b=0。而我们的约束条件为:
满足上述约束条件并且使得||w||2最小的,就是最优的分类面,也就是图2-1中的 Separating Hyperplane。而要求得最短的距离就是满足一定的约束条件:
据此可以解出w*和b*,所以超平面函数:w*·x+b*=0
决策函数为:f(x)=sgn(w*·x+b* )
对于线性不可分的情况,常引入核函数,通过高级数的多项式模型来解决这个问题。将非线性的情况转化为高维特征空间的线性情况,然后再去寻找最优的分类超平面。
线性不可分中的目标函数和决策函数的内积xi·xj要用核函数φ(xi)·φ(xj)来替代。常见的核函数有高斯核函数、sigmoid核函数。
支持向量机优点:第一,适用于小样本的情况,简化分类和回归的问题。它的目标是得到现有样本信息下的最优解。第二,凸优化问题,SVM的解就是全局唯一的最优解,可以很好的找到全局最优解。第三,具有良好的泛化能力,可避免“维数灾难”的出现。但支持向量机也存在一些缺点:第一,它只给出两类分类的算法,而在实际生活中,一对多的情况经常发生,支持向量机并不能很好的适应实际情况。第二,对于大规模的样本,支持向量机处理起来很费时间,训练的时间会很长。第三,它的优劣很大程度上取决于核函数的优劣,而在选取核函数的过程中,常常存在主观随意性,会造成结果的不准确。
数据处理
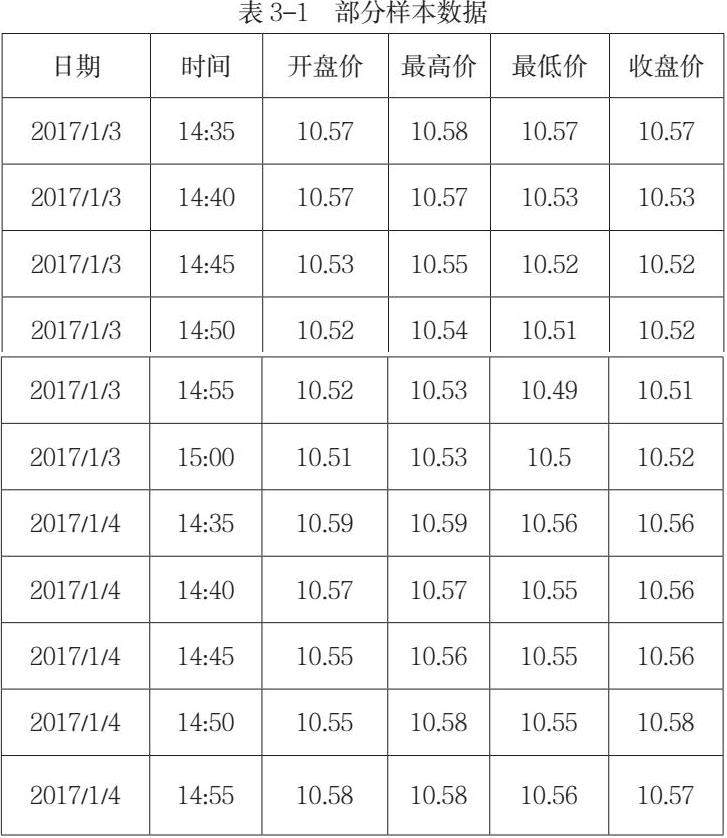
本文采用的是数字货币行业的31只股票数据。数据来源于雅虎财经网页的历史交易数据,数据时间是从2017年1月到2019年12月,部分数据如表3-1所示。机器学习对于数据是十分敏感的,数据质量的好坏对于最终的模型的优劣起着决定性的作用。有时候对于数据的选取和处理,其重要程度会超过对于机器学习算法的选择。
我们初始收集到的数据,会存在诸如数据缺失等问题,要对数据进行“清洗”。本文主要对数据进行以下处理:
(1)缺失值处理:因为在本文中样本比较充裕,行业数据比较多,所以在训练模型的时候对于缺失项可以予以删除,即把整一行的数据都删除。但是对于每一个股票来说,数据是有限的,所以对于缺失的数据采用平均值的方法进行填充。
(2)标准化和归一化处理:因为每一个股票的价格都是不一样的,有一些股票的价格很高,有一些股票的价格很低,这样不利于数据的对比,并且在寻找全局最优解的时候,放缩的速度很慢,所以对于所有的股票来说都要进行标准化处理。归一化的目的是将所有的数都归到0和1之间,这样有利于提高运算速度。本文要使用的数据全部进行标准化和归一化的处理,也就是将开盘价、收盘价、最高价和最低价都通过标准化和归一化将它们全部归到[0,1]间,采用的归一化的方法是线性函数法中的最大最小值法。
特征向量
以《基于SVM算法的多因子选股模型实证研究》文章为依据,投资者对于最后半个小时的交易热情会上升。如若看到最后半个小时的价格在上升,那么投机者就会加大购买的力度;反之则会加快抛售的力度。在所有的样本中,选取60%作为训练集,20%作为交叉验证集,剩余的20%作为验证集。
在本文中选取的特征向量是一个加权平均价格。首先在上面数据的处理中我们得到每五分钟的价格,然后通过筛选得到最后半个小时的每5分钟的最高价、最低价、开盘价和收盘价。根据道氏理论,在所有的价格中,收盘价是最重要的,所以对收盘价赋予最多的权重,公式为3-1所示:
收盘价*0.4+(开盘价+最高价+最低价)*0.2 (3-1)
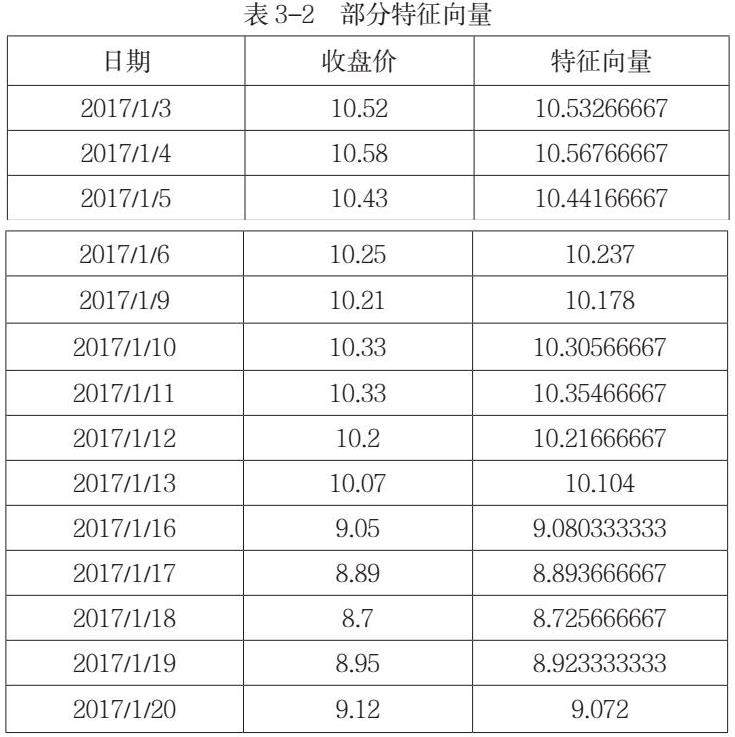
这样就可以得到最后半个小时每一个五分钟特征价格,在半个小时的时间跨度中,这样的价格一共有6个,将这6个价格取平均值,就得到了本文需要的特征向量。表3-2显示了一部分本文所需的特征向量。
特征向量也和数据一样需要进行归一化的处理,从上述表格中我们可以看到,得到的特征向量和每一只股票的价格有关。不同的股票之间的价格差异很大,所以归一化处理是必要的。一般来说归一化处理包括以下几种方法:
1.线性函数法
对于样本数据x(n),归一化的样本数据具体包括3种表示方法,分别为:最大最小值法、均值法和中间值法。其中,最大最小值法是将样本归一化到[0,1]范围;而均值法可以将数据归一化到任意范围内,不过最大值和最小值的符号不能改变,中间值法将数据归一化到[-1,1]范围内。三种方法分别如式子(3-2)、(3-3)、(3-4)所示:
其中,min(x(k))表示样本数据的最小值,max(x(k))表示样本数据的最大值,u表示样本数据的均值,mid为样本数据的中间值,A为调节因子,是一个常数,目的是调节样本数据的范围。
2.对数函数法
对于样本数据x(n),归一化后的样本数据y(n)可以用下面的公式表示:
对数函数法主要应用于数据的数量级非常大的情况。
3.反余切线法
对于样本数据x(n),归一化后的样本数据y(n)用公式表示为:
反余切函数法主要用于将角频率等变量转换到[-1,1]范围。
本文中选择的归一化方法是线性函数法的最大最小值法,通过找到收盘价和特征向量的最大最小值,利用公式将所有的价格都转换到[0,1]的范围,转换后的部分价格如表3-3所示:
四、模型优化
在使用训练集得到模型之后,运用相应的指标对模型进行分析是十分重要的,并且不同模型的评价标准也不同。由于均方误差指标能够很好地帮助我们去判断模型的优劣程度,故本文中主要选取均方误差(MSE)来对模型的优劣进行评判。它的公式如(4-1)所展示:
均方误差是参数的估计值与参数的真实值的差值的平方的期望,其值越小说明精确度越高。
在使用机器学习预测股票价格,参数的选择十分重要。在支持向量机中,我们主要调节的是核函数的参数gamma和惩罚系数C。在本文中我们选用的核函数是高斯核函数,高斯核函数属于径向核函数,相比于sigmoid核函数以及线性核函数,径向核函数在性能上更加优越,而高斯核函数又是径向核函数性能比较好的函数。在文中,我们规定惩罚系数C的取值范围为[1,1000],这主要考虑到两个方面:当惩罚系数C趋于无穷大时,那么就不允许出现分类误差的样本存在,即会得到一个过拟合的模型;当惩罚系数C趋于0时,那么将不再关注分类是否正确,只要求间隔越大越好,即会出现欠拟合的问题。所以在本次实验中C的取值范围是相对比较合理的。
做好一切的准备之后,我们就开始进行实验。实验所选用的工具是R语言。首先我们先将处理好的数据导入R语言,然后需要选择好特征向量和预测值并将样本进行分类,在机器学习中,常见的分类方法是将样本数据分为三部分,分别是训练集、验证集和预测集,它们之间的比例为6:2:2。在模型训练中通过训练集和验证集得出最优参数,通过测试集来预测模型的精确程度。最后就是模型的建立,我们首先在惩罚系数为10,高斯核函数的gamma=2的环境下建立模型,通过R语言训练得到了预测数据,通过MSE的公式计算得到均方误差,计算所得的均方误差为0.001971318。此时我们可以发现均方误差是比较小的。
接下来我们通过固定C来调整gamma,在本次实验中我们选择的步长为20。因为gamma对MSE的影响是先减小后变大,所以我们选定惩罚系数C=10,gamma=40的环境下建立模型,此时计算得到的均方误差MSE为0.005605438。通过对比这两个均方误差我们可以发现在gamma为2的情况下拟合得更加好。
然后我们尝试固定gamma来调整C,惩罚系数C的步长为10。因为C对于MSE的影响是一直增加的,所以我们在gamma=2,惩罚系数为1的情况下建立模型。在这里我们计算得到的均方误差为0.001971316。对比这两个均方误差我们可以发现在C=1的情况下拟合得更好,也即预测地更加准确。
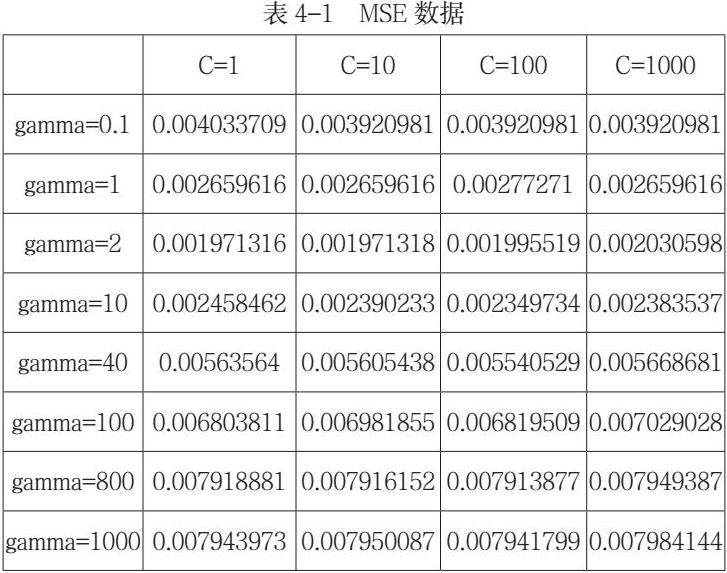
最后我们在不同的gamma和C下试验,在本文中gamma的步长为10和20,而C的步长选定为10,试验结果如表4-1:
从表中的数据我们看出,最小的MSE是在C=1且gamma=2的情况下。从每一列的数据来看,随着gamma的增加MSE先变小后变大;从每一行的数据来看,得到的不同的惩罚系数对于MSE的影响并不大,说明惩罚系数已经趋于无穷了,在本文所选取的C和gamma中,在C=1的时候就已经趋向于无穷,所以对于结果的影响并不是很大。
在本次实验中,得到的模型是惩罚系数C=1,gamma=2。在这个模型下,MSE为0.001971316,模型的误差很小,说明本文所得到的模型能够很好对数字货币行业的股票价格进行预测。
基于已经得到的模型,来进行最后的验证分析,在验证的环节中我们使用相关系数来作为我们的验证结果的评价。相关系数越接近1,则预测价格与真实的价格就越接近。在惩罚系数C=1,gamma=2的模型下,预测价格与真实价格的相关系数为0.993,与1十分接近,这说明预测的效果比较好。
五、研究展望
支持向量机是一种非常实用的机器学习模型,在生活中的很多领域都有用途。它在解决小样本、高纬度数据以及非线性问题上上都有显著的优势,而且已经推广应用到函数拟合等其他的机器学习问题中,对支持向量机的学习和应用一直是机器学习领域的重点。
本文主要通过支持向量机来进行股票价格的预测,研究的重点是股票价格波动情况,通过给予不同价格不同的权重作为特征向量来研究收盘价的情况。对于数字货币行业的样本选择体现了对国家现阶段重点任务的关注。选取的三年数据也很好的概括了走势,选取一年的数据,会显得没有代表性,而十年数据的选择又显得没有效率。从最后的结果来看,本文的模型具有较好的泛化能力,能够对股票价格的预测起到良好的帮助作用。
本文的不足与展望:
特征向量选取的少,仅使用一个特征向量来构建模型。在日后的研究中,要使用多个特征向量,更好的预测股票价格。
本文选用高斯核函数来进行优化,参数的选取也比较的合理,能够较好的拟合模型,但是难以应用到实际,在实际生活中还会存在很多的问题,需要不断地对模型进行各个方面的改进,使之能够运用到实际的生活领域。
本文仅仅使用支持向量机来进行股票价格的预测,没有与其他的模型进行比对,在日后的学习研究中,可以尝试使用其他的模型做回归,得到更好的模型。
参考文献:
[1] 厉国强. 基于机器学习的股指预测算法[D]. 天津工业大学, 2017.
[2] 赵玉涵. 基于机器学习方法的股票价格趋势预测研究[D]. 河南理工大学, 2017.
[3] 冉杨帆 蒋洪迅. 基于BPNN和SVR的股票价格预测研究[J]. 山西大学学报(自然科学版), 2018, 41(1):1-14.
[4] 王禹. 基于Cart树和Boosting算法的股票预测模型[D]. 哈尔滨理工大学,2018.
[5] 林娜娜 秦江涛. 基于随机森林的A股股票涨跌预测研究[J]. 上海理工大学学报. 2018, 40(3):267-273,301.
[6] 扈香梅. 浅谈基本面分析和技术分析在股票市场的应用[J]. 新西部(中旬刊), 2014, (3):62,64.
[7] 杨用斌, 杨唯实. 基本面分析和技术分析流派市场价格博弈--基于方法相关性下的研究[J]. 经济问题,2013(11): 78-81.
[8] 杨永洁. 基于优化MACD模型的股票价格变化趋势预测方法[J], 广西科学院学报, 2017, 33(1): 65-70.
[9] 焦成焕, 吴桐. 数字货币属性及发行实践研究[J]. 海南金融, 2019, (9):36-42
[10] 王智. 基于机器学习对优质股的选择[J]. 软件开发, 2018, (7): 60-62.
[11] 周渐. 基于SVM算法的多因子选股模型实证研究[D]. 浙江大学,2017.
[12] 阚子良, 蔡志丹. 基于优化参数的IS-SVM模型股票价格时间序列预测[J]. 长春理工大学学报(自然科学版)2018 ,41(1): 131-133,138.
[13] 傅泊森. 基于线性回归模型研究互联网行业公司股票价格影响因素[J]. 2019, (6)金融在线, 2019 (6):106-108.
[14] 李学峰. 为什么要进行公司基本面分析[J]. 创新思维, 2019, (4):30-32.
[15] 扬寒冰. 机器学习算法在股票价格预测中的应用[D]. 南开大学,2016.
[16] Patel, Jigar Shah, Sahli Thakkar, Priyank Kotecha, K. Predicting stock market index using fusion of machine learning techniques[J]. Expert Systems with Application. 2015,42(4):2162-2172
作者简介:
章银松(1997-),性别:男,籍贯:浙江。学历:研究生,职称:无,研究方向:期权定价和机器学习,作者单位:上海大学。

 京公网安备 11011302003690号
京公网安备 11011302003690号


