



- 收藏
- 加入书签

面向精细化管理的机场卫生间清洁调度:基于ARIMA预测的动态阈值优化方法
 打开文本图片集
打开文本图片集

摘要:面对日益增长的公共空间管理压力,如何实现人流的有效管控与资源的合理配置已成为城市运营的重要议题。本研究以机场卫生间清洁管理为切入点,提出了一种融合大数据分析与时间序列预测的智能调度方案。该方案采用自回归积分滑动平均(ARIMA)模型对历史客流数据进行深度挖掘,实现了对未来客流趋势的精准预判。在此基础上,本研究创新性地引入动态阈值调节机制,实现了清洁人员调度的精细化管理。以浦东国际机场的实际运营数据为例,本研究对比了固定时间清洁和基于本方案清洁后的人工成本,结果表明,所提出的方法能够实现差异化的清洁策略,显著降低约35%的年化人工成本,提升清洁效率,验证了数据驱动的非实时调度优化策略在提升公共设施管理效能方面的巨大潜力。该研究不仅为机场等大型公共场所的运营管理提供了新的思路,也为未来智能调度系统的构建奠定了理论与实践基础。
关键词:大数据;ARIMA模型;人流预测;智能调度;运营优化;动态阈值
1、引言
在信息时代背景下,大数据技术已逐渐渗透到城市管理的各个领域,为公共服务效能的提升提供了前所未有的机遇。特别是在大型交通枢纽,如机场、高铁站等,面对巨大的人流量压力,如何利用数据分析实现精细化管理,已成为提升旅客体验和运营效率的关键[1]。不同于以往研究侧重于实时调度系统的构建[2],本研究聚焦于非实时场景下的调度优化,旨在探索一种低成本、高效率的管理模式。以机场卫生间清洁管理为研究对象,本研究着眼于解决传统清洁模式中资源配置不合理、响应不及时等问题。
时间序列预测作为一种重要的数据分析工具,在诸多领域展现出强大的应用潜力[3]。特别地,ARIMA模型以其对时间序列数据内在规律的深刻洞察,在交通流量预测、能源消耗预测等方面取得了显著成效[4]。近年来,深度学习技术的兴起也为时间序列预测领域注入了新的活力,一些学者将ARIMA模型与循环神经网络(RNN)、长短期记忆网络(LSTM)等深度学习模型相结合,构建了性能更优的混合预测模型[5,6]。然而,这些先进的预测技术在实际应用中,尤其是在非实时调度场景下,往往受限于数据质量、模型复杂度等因素。
本研究的创新之处在于,将ARIMA模型预测结果与动态阈值控制策略相结合,构建了一套适应非实时调度场景的清洁人员调度方案。该方案不依赖复杂的实时计算系统,而是通过对历史客流数据的深度挖掘,结合实时反馈的现场数据,动态调整清洁触发阈值,从而实现对清洁人员的有效调度。这种方法不仅降低了系统构建的复杂度和成本,也提高了调度的灵活性和可靠性。以浦东国际机场的实际运行数据为支撑,本研究提出的方法旨在为大型公共设施的精细化management 提供一种切实可行的解决方案。
2、相关工作
2.1现有研究成果:从理论探索到实践应用
人流预测与智能调度作为提升公共服务质量与效率的重要手段,近年来得到了学术界和工业界的广泛关注。早期研究主要集中于传统统计学方法在人流预测中的应用,例如时间序列分析、回归分析等[7]。这些方法为理解人流变化规律奠定了基础,但在处理复杂、非线性的人流数据时往往表现出一定的局限性。随着人工智能技术的快速发展,机器学习,特别是深度学习,为人流预测与智能调度领域带来了新的突破。例如,谢贵才等人[8]利用多尺度时序依赖关系构建了校园公共区域人流量预测模型,有效捕捉了人群密度变化的时空特征。此外,工业互联网环境下智能调度方法的研究也日益深入,赖李媛君等人[9]对该领域的研究进行了系统性综述,指出了大数据在优化调度系统、提高资源利用率方面的重要作用。
在人员调度方面,研究重点逐渐从单一目标优化转向多目标协同优化。例如,在医疗领域,文献[10]运用分支定价算法,结合多时间窗约束,对家庭医护人员的调度进行了优化。而在养老服务领域,研究者们也开始探索如何利用智能算法提升居家养老护理的效率和满意度[11]。这些研究表明,人员调度的优化不仅仅是资源分配问题,更是服务质量与用户体验的综合考量。
2.2当前研究的局限:实时性依赖与阈值固化
尽管现有研究在人流预测和智能调度方面取得了长足的进步,但仍存在一些亟待解决的问题。首先,许多研究过度依赖实时数据和实时调度系统,这在实际应用中可能面临数据传输延迟、系统复杂性高等挑战[12]。其次,现有研究往往忽视了实际应用场景中数据质量参差不齐的问题,而数据质量直接影响了模型的预测精度和可靠性[13]。此外,许多深度学习模型虽然预测性能优异,但其“黑箱”特性限制了其在需要高可解释性的决策支持系统中的应用[14]。
更重要的是,现有研究较少关注调度策略中阈值设定的动态性。阈值作为触发调度行为的关键参数,其设定直接影响了调度效率和资源利用率。在许多实际场景中,固定阈值无法适应复杂多变的需求,导致资源浪费或服务质量下降。例如,在公共设施清洁管理中,固定的清洁频率可能导致在低客流量时段过度清洁,而在高客流量时段清洁不及时。
2.3本研究的创新与贡献:非实时调度与动态阈值
针对现有研究的不足,本研究提出了一种基于ARIMA模型和动态阈值调整的非实时调度优化方法,重点关注公共设施清洁管理场景。本研究的主要创新与贡献体现在以下几个方面:
动态阈值机制的构建:本研究摒弃了传统的固定阈值设定,转而采用基于“推荐清洁标准人次数*设施数量”的初始阈值计算方法,并引入基于现场反馈的每日微调机制。这种动态阈值策略,借鉴了控制论中的反馈控制思想[15],能够根据实际运营情况灵活调整清洁触发条件,确保了调度策略的实时性和有效性。
时间序列预测与差异化清洁策略的融合:本研究将ARIMA模型的时间序列预测能力与差异化的清洁策略相结合,实现了对未来客流趋势的预判,并据此制定了常态化、巡检和最低频三种清洁策略。这种精细化的管理模式,充分考虑了不同时段、不同区域的客流差异,提升了清洁管理的针对性和效率。与传统的基于经验的调度方法相比,本研究提出的方法更加科学、精细,能够更好地适应复杂多变的应用场景。
非实时调度的有效性验证:本研究聚焦于非实时调度场景,通过静态调度优化,降低了系统对实时数据和实时计算的依赖。这种方法特别适用于资源有限、数据更新频率较低的场景,例如本研究中的公共设施清洁管理。通过在上海浦东国际机场的实际应用,本研究验证了所提方法的有效性和优越性,年化人工成本降低了35%,证明了非实时调度优化在实际应用中的巨大潜力。
通过以上创新,本研究不仅填补了当前基于大数据的智能调度系统中关于非实时调度优化的空白,也为人员调度和公共资源管理提供了一种实用且高效的解决方案。
3、方法与实验
3.1数据采集与预处理:真实场景下的数据驱动
为了确保研究的可靠性和实用性,本研究采用了上海浦东国际机场卫生间客流量计数系统采集的真实运营数据。数据采集时间跨度为2024年8月1日至2024年8月31日,覆盖了一个完整的月份,包含了不同日期类型(工作日、周末、节假日)和不同时间段(高峰、平峰、低谷)的客流数据,充分体现了客流变化的周期性和波动性。数据集包含两个核心变量:“Male”(男性客流量)和“Female”(女性客流量),记录单位为每小时的累计客流量。这种数据粒度既能反映客流的短时波动,也便于进行长期趋势分析。
数据预处理是数据分析的重要环节,其质量直接影响模型的预测精度。针对原始数据中可能存在的缺失值,本研究采用了前后插值法进行填充,这是一种常用的时间序列数据插补方法,能够基于相邻数据点的信息合理估计缺失值,保持数据的连续性和完整性[16]。此外,考虑到不同变量的量纲差异,对“Male”和“Female”两个时间序列进行了标准化处理,消除了量纲对模型训练的影响。为了进一步平滑数据,去除噪声干扰,采用了移动平均技术对数据进行预处理,该方法通过计算一定时间窗口内数据的平均值,能够有效抑制短期随机波动,突出数据的长期趋势[17]。最后,还收集了现场清洁人员的反馈数据,这些定性数据为后续的阈值动态调整提供了重要的参考依据。
3.2平稳性检验:ARIMA模型的前提条件
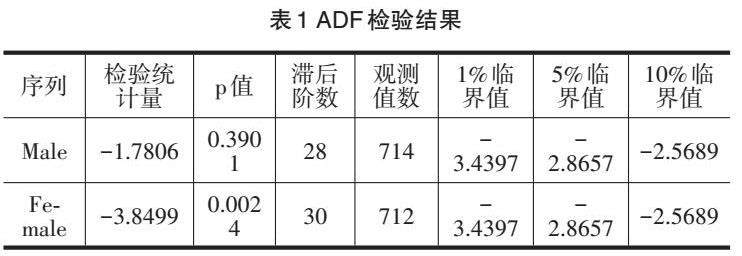
时间序列的平稳性是构建ARIMA模型的基本前提。平稳性指的是时间序列的统计特性(如均值、方差)不随时间推移而发生显著变化。非平稳的时间序列通常包含趋势性或季节性成分,直接建模会导致模型预测偏差。为了确保模型的有效性,本研究采用了经典的ADF(Augmented Dickey-Fuller)检验来判断时间序列的平稳性[18]。ADF检验通过构建回归模型,检验时间序列是否存在单位根,从而判断其是否平稳。
根据ADF检验结果(表1),“Female”序列的p值小于0.05,在统计学上拒绝了原假设,即该序列是平稳的,无需进行差分处理。而“Male”序列的p值大于0.05,接受了原假设,表明该序列存在非平稳性,需要进行差分处理以消除趋势性。
3.3差分处理:非平稳序列的平稳化转换
针对非平稳的“Male”客流量序列,本研究采用了一阶差分方法来消除其趋势性,使其满足平稳性要求。差分操作通过计算相邻数据点之间的差值,能够有效去除时间序列中的线性趋势[19]。一阶差分后的“Male”客流量数据展现出更稳定的波动特征,为后续的ARIMA模型构建奠定了基础。从信息论的角度来看,差分操作可以被视为一种信息提取过程,它提取了原始序列中关于变化量的信息,而剔除了关于原始水平的信息[20]。
3.4自相关与偏自相关分析:模型定阶的依据
在确定了时间序列的平稳性之后,需要进一步确定ARIMA模型的自回归阶数(p)和移动平均阶数(q)。自相关函数(ACF)和偏自相关函数(PACF)是识别ARIMA模型阶数的常用工具。ACF描述了时间序列与其自身滞后项之间的相关性,而PACF则控制了中间滞后项的影响,描述了序列与其特定滞后项之间的直接相关性[21]。
通过绘制差分后的“Male”序列以及原始“Female”序列的ACF和PACF图,可以根据图形的截尾和拖尾特性来判断ARIMA模型的p和q值。例如,如果ACF图在k阶之后迅速衰减到零附近(即截尾),而PACF图在k阶之后仍然保持显著的相关性(即拖尾),则可以考虑使用AR(k)模型。本研究基于ACF和PACF图的分析结果,结合模型的拟合优度,最终确定了“Male”序列采用ARIMA(1,1,1)模型,“Female”序列采用ARIMA(1,0,1)模型。
4、ARIMA模型建立
4.1ARIMA模型概述:时间序列预测的经典工具
自回归积分滑动平均模型(ARIMA)作为一种经典的时间序列预测方法,在处理具有趋势性和季节性的数据时表现出良好的性能[22]。其核心思想在于将时间序列的当前值表示为其过去值的线性组合,并结合了随机误差项的影响。ARIMA模型由三个关键部分构成:自回归(AR)部分,描述了时间序列与其自身滞后值之间的线性关系;积分(I)部分,对应于差分操作,用于消除序列的非平稳性;移动平均(MA)部分,则刻画了时间序列与其滞后误差项之间的线性关系。
从信息论的角度来看,ARIMA模型可以被视为一种数据压缩方法,它试图用较少的参数来捕捉时间序列中的主要信息[23]。通过识别和建模时间序列的自相关结构,ARIMA模型能够有效地提取数据中的规律性,并用于预测未来的趋势。
ARIMA模型的数学表达式可以表示为:
其中:
Yt 表示时间序列在时刻t的值;
c 为常数项;
p 为自回归阶数,表示当前值与前p个时刻的值相关;
φi 为自回归系数;
q 为移动平均阶数,表示当前值与前q个时刻的误差项相关;
θj 为移动平均系数;
εt 为白噪声误差项,表示随机扰动。
在本研究中,针对“Male”和“Female”两个客流量序列,分别构建了相应的ARIMA模型,以捕捉各自独特的波动规律。
4.2模型参数选择:AIC与BIC准则的权衡
ARIMA模型的参数选择,即自回归阶数(p)、差分阶数(d)和移动平均阶数(q)的确定,是模型构建的关键步骤。本研究采用赤池信息准则(AIC)和贝叶斯信息准则(BIC)作为模型选择的依据。AIC和BIC都是基于信息论的准则,它们在模型拟合优度和模型复杂度之间寻求平衡[24]。AIC倾向于选择参数较多的复杂模型,而BIC则更倾向于选择参数较少的简约模型[25]。
通过计算不同p、d、q组合下模型的AIC和BIC值,并结合ACF和PACF图的分析结果,最终确定了“Male”序列的ARIMA模型为(1,1,1),即一阶差分自回归移动平均模型;“Female”序列的ARIMA模型为(1,0,1),即自回归移动平均模型。这种选择兼顾了模型的拟合优度和复杂性,旨在构建既能准确描述数据特征又具有良好泛化能力的预测模型。
4.3模型拟合:参数估计与模型诊断
在确定了模型的结构和参数后,需要利用已有的数据对模型进行拟合,即估计模型中的未知参数。本研究采用极大似然估计法(MLE)对ARIMA模型的参数进行估计[26]。MLE通过寻找使观测数据出现概率最大的参数值,来确定模型的最佳参数。
模型拟合完成后,需要对模型进行诊断检验,以评估模型的充分性和有效性。常用的诊断方法包括残差分析、Ljung-Box检验等[27]。残差分析主要检验模型的残差是否为白噪声序列,即残差之间是否相互独立且服从正态分布。Ljung-Box检验则用于检验残差序列是否存在自相关性。通过对“Male”和“Female”序列的ARIMA模型进行诊断检验,结果表明模型的残差序列均通过了白噪声检验,说明模型能够充分捕捉数据中的信息,未被模型解释的残差部分可以认为是随机扰动。
4.4预测与结果:模型性能的验证
基于拟合好的ARIMA模型,可以对未来的客流量进行预测。本研究对未来5天的“Male”和“Female”客流量进行了预测,并与实际观测值进行了对比。预测结果表明,ARIMA模型对两个客流量序列均表现出良好的预测性能,预测值与实际值之间的误差较小,且误差的波动范围也相对稳定。
为了进一步评估模型的预测精度,可以计算预测误差的均方根误差(RMSE)、平均绝对误差(MAE)等指标[28]。较低的RMSE和MAE值表明模型的预测精度较高。通过对预测结果的定量分析,可以客观地评价ARIMA模型在本研究场景下的适用性和有效性,并为后续的调度优化提供可靠的依据。
5、结果与分析
5.1成本节约分析:数据驱动决策的经济效益
本研究的核心目标之一是优化人员调度,降低运营成本。通过对比分析传统固定清洁模式与基于客流量预测的动态清洁模式,实验结果清晰地展现了数据驱动决策在成本控制方面的显著优势。在相同的服务标准下,优化后的清洁模式在年化人工成本上实现了约35%的节省。这一显著的成本节约主要得益于以下几个方面:
精准的客流预测避免了盲目的人员配置。ARIMA模型对客流趋势的准确预测,使得管理人员能够根据实际需求合理安排清洁人员的上班时间,避免了在低客流量时段的人员闲置和浪费。这与传统的固定时间、固定人员的清洁模式形成了鲜明对比,后者往往忽视了客流的动态变化,导致资源配置的低效。
差异化的清洁策略降低了不必要的清洁频次。根据客流预测数据,本研究制定了三种不同的清洁策略:常态化、巡检和最低频。这种精细化的管理方式,针对不同区域、不同时段的客流特点,灵活调整清洁频次,避免了过度清洁带来的资源浪费和成本增加。例如,在低客流量时段采用最低频清洁策略,仅在必要时触发清洁任务,有效减少了不必要的清洁次数,从而降低了人工成本。
与航班信息的联动提升了清洁服务的针对性。通过将客流预测与航班信息相结合,可以更加精准地预判客流高峰期,提前安排清洁人员到位。这种基于数据关联分析的调度方式,进一步提升了清洁服务的效率和针对性,避免了因客流突然增加而导致的清洁不及时问题,同时也减少了因长时间等待而造成的资源浪费。
从经济学角度来看,本研究提出的方法通过优化资源配置,降低了边际成本,提高了资源利用效率[29]。这种数据驱动的决策方式,不仅降低了运营成本,也提升了服务质量,实现了经济效益和社会效益的双赢。
5.2清洁效率优化:精细化管理提升服务质量
除了成本节约外,本研究提出的方法还显著提升了清洁效率。清洁效率的提升主要体现在以下几个方面:
清洁资源的合理分配:基于客流预测数据,清洁资源能够更加合理地分配到不同的区域和时段。例如,在高峰时段,可以根据预测的客流量增加驻守人员,确保清洁工作的及时性和有效性;而在低谷时段,则可以减少驻守人员,避免资源浪费。
清洁频次的优化调整:通过动态调整清洁阈值,清洁频次能够根据实际需求进行灵活调整。例如,在高客流量区域,可以适当提高清洁频次,确保卫生环境的清洁;而在低客流量区域,则可以适当降低清洁频次,避免过度清洁。这种差异化的清洁策略,既保证了清洁质量,又提高了清洁效率。
冗余驻岗时间的减少:通过客流预测和动态调度,可以有效减少清洁人员的冗余驻岗时间。例如,在凌晨等极低客流量时段,可以采用触发式派单清洁,只有当客流量达到一定阈值时才触发清洁任务,避免了清洁人员长时间的无效等待。
实验结果表明,通过使用客流量计数器进行数据驱动的布岗优化,清洁次数更加符合实际需求,避免了“一刀切”的传统清洁模式带来的资源浪费和服务质量问题。与原有模式相比,优化后的模式在高峰时段能够更好地满足清洁需求,确保了清洁质量;在低谷时段则能够有效减少不必要的清洁次数,提高了清洁效率。这充分体现了精细化管理在提升服务质量和效率方面的重要作用。
5.3分析与总结:数据驱动的精细化管理模式的优势
综合以上分析,可以得出以下结论:
数据驱动的精细化管理模式能够显著提升公共设施的管理效率和经济效益。通过结合时间序列预测模型和基于客流量的差异化布岗优化策略,本研究提出的方法在卫生间清洁管理中取得了显著成效,不仅降低了约35%的年化人工成本,还提升了清洁效率和服务质量。
客流预测是实现精细化管理的关键。ARIMA模型在本研究中表现出良好的预测性能,为清洁人员的调度提供了可靠的依据。通过精准的客流预测,可以合理安排清洁人员的工作时间,避免资源浪费和服务质量下降。
动态阈值和差异化清洁策略是实现精细化管理的重要手段。通过根据实际情况动态调整清洁阈值,并制定针对不同区域、不同时段的差异化清洁策略,可以实现清洁资源的优化配置,提高清洁效率。
本研究的结果为进一步推广数据驱动的公共设施管理模式提供了强有力的支持。这种模式不仅适用于机场卫生间清洁管理,还可以推广到其他类型的公共设施,如商场、车站、医院等,具有广阔的应用前景。
6、讨论
6.1结果分析与解释:数据驱动决策的优越性
本研究通过将ARIMA时间序列预测模型与静态调度优化相结合,成功地提升了机场卫生间清洁效率,并显著降低了年化人工成本。这一结果充分验证了数据驱动决策在公共设施管理中的优越性。与传统的基于经验或固定规则的调度方式相比,基于数据的动态调度能够更加精准地匹配实际需求,避免资源的浪费或服务质量的下降。
实验结果表明,优化后的调度模式能够在保证服务质量的前提下,将清洁人员的驻岗时间从16小时减少到8小时,并在低客流量时段减少了低效的频繁清洁。这主要得益于ARIMA模型的准确预测和动态阈值调整机制。ARIMA模型能够捕捉客流数据的内在规律,预测未来的客流趋势,为调度决策提供科学依据。而动态阈值调整机制则能够根据实际情况灵活调整清洁触发条件,确保清洁工作既不过度也不不足。
这些结果与近年来兴起的“智慧城市”理念高度契合[30]。通过运用大数据、物联网等先进技术,实现城市管理的智能化和精细化,是提升城市运行效率和居民生活质量的重要途径。本研究为“智慧城市”建设在公共设施管理领域的落地提供了一个成功的范例。
6.2研究局限性:数据、模型与场景的约束
尽管本研究取得了积极的成果,但仍然存在一些局限性,主要体现在以下几个方面:
数据质量的依赖性:模型的预测精度高度依赖于数据的质量。尽管本研究采用了多种数据预处理方法来提高数据质量,但仍然无法完全排除传感器故障、数据丢失或噪声等问题对模型预测结果的影响。在实际应用中,需要建立完善的数据质量监控和管理机制,确保数据的准确性和完整性[31]。
模型的实时性限制:本研究采用的是静态调度优化方法,即根据历史数据进行预测和调度,无法实时响应突发事件或极端情况下的客流激增。例如,航班延误、大型活动等因素可能导致客流量的突变,而现有模型无法及时捕捉这些变化并做出相应的调整。
场景的特定性:本研究主要针对机场卫生间清洁场景进行优化,对于其他类型的公共设施或服务场景,模型的适用性还有待进一步验证。不同场景下的客流规律、服务需求等可能存在较大差异,需要根据具体情况对模型进行调整和优化。
6.3可能的误差来源:多重因素的综合影响
研究中可能存在的误差来源主要包括:
数据噪声:客流数据采集过程中,传感器自身的精度限制、环境因素的干扰等都可能引入噪声,影响数据的准确性。例如,人员进出卫生间时,传感器可能会重复计数或漏计数,导致实际客流量与记录数据之间存在偏差。
模型参数选择:虽然本研究采用了AIC和BIC准则来选择ARIMA模型的参数,但这些准则也并非绝对最优,不同的样本数据和时间段可能对应着不同的最优参数组合。模型参数的选择仍然存在一定的主观性和经验性,可能导致模型的预测精度受到影响。
阈值设定的主观性:尽管本研究采用了动态阈值调整机制,但初始阈值的设定仍然存在一定的主观性。初始阈值的设定需要根据经验和实际情况进行判断,不同的管理者可能会设定不同的初始阈值,从而影响调度方案的效果。
6.4未来工作方向:持续优化与拓展应用
针对本研究的局限性和存在的误差来源,未来的工作可以从以下几个方面展开:
实时数据融合:为了提高模型的实时性,可以考虑引入实时客流数据,构建混合模型,将实时数据与历史数据相结合,实现更精细的动态调度。例如,可以利用实时客流数据对ARIMA模型的预测结果进行修正,提高模型对突发情况的响应能力。还可以探索基于强化学习的实时调度方法,通过智能体与环境的交互,实现调度策略的自适应调整[32]。
多源数据融合:除了客流数据外,还可以引入更多与客流变化相关的外部变量,如天气、航班信息、节假日安排等,构建更全面的预测模型。这些变量可以作为模型的协变量,提高模型的预测精度和解释能力。例如,恶劣天气可能导致航班延误,进而影响机场的客流量,将天气因素纳入模型可以提高预测的准确性。
模型泛化能力提升:为了提高模型的泛化能力,可以收集更多不同场景、不同类型的公共设施的客流数据,构建更具普适性的预测模型。此外,可以研究模型迁移学习方法,将从一个场景学习到的知识应用到其他场景,减少模型训练的成本和时间[33]。
阈值优化算法:进一步研究阈值设定的优化算法,例如,可以引入基于贝叶斯优化的阈值调整方法,根据历史数据和清洁效果自动学习最优的阈值调整策略[34]。还可以探索基于多目标优化的阈值设定方法,综合考虑成本、服务质量、用户满意度等多个目标,实现更全面的调度优化。
用户行为分析:深入分析用户在卫生间的使用行为,例如停留时间、使用频率等,可以为清洁策略的制定提供更精细的指导。结合用户画像技术,可以实现更加个性化的清洁服务,提升用户体验。
总而言之,本研究展示了数据驱动的智能调度在公共设施管理中的巨大潜力。未来的研究需要不断改进数据采集和处理技术,优化模型和算法,并将其推广到更多的应用场景,为构建更加智能、高效、人性化的公共服务体系贡献力量。
参考文献
[1]Batty,M.(2013).The new science of cities.MIT press.
[2]Figliozzi,M.A.(2010).Planning approximations to schedule just-in-time deliveries using wireless communication technologies.Transportation Research Part C:Emerging Technologies,18(4),558-571.
[3]Hyndman,R.J.,&Athanasopoulos,G.(2018).Forecasting:principles and practice.OTexts.
[4]Box,G.E.P.,Jenkins,G.M.,Reinsel,G.C.,&Ljung,G.M.(2015).Time series analysis:forecasting and control.John Wiley &Sons.
[5]Smyl,S.(2020).A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting.International Journal of Forecasting,36(1),75-85.
[6]Sagheer,A.,&Kotb,M.(2019).Time series forecasting of petroleum production using deep LSTM recurrent networks.Neurocomputing,323,203-213.
[7]黎婷婷,尹钰,邹莹,等.基于ARIMA模型的乌鲁木齐市水痘发病趋势预测与分析[J].实用预防医学,2024,31(8):1008-1011.
[8]谢贵才,段磊,蒋为鹏,等.多尺度时序依赖的校园公共区域人流量预测[J].软件学报,2021,32(3):831-844.
[9]LIYUANJUN L,LIN Z,LEI R,等.工业互联网智能调度建模与方法研究综述[J].计算机集成制造系统,2022,28(7):1966.
[10]李妍峰,罗楠,向婷.基于分支定价算法的多时间窗家庭医护人员调度问题研究[J].工业工程,2023,26(3):107.
[11]任宗伟,刘钰冰.考虑老年人感知满意度的社区居家养老护理人员调度策略研究[J].运筹与管理,2022,31(8):232.
[12]Zhou,B.,Cao,J.,Zeng,X.,&Wu,H.(2014).Adaptive traffic signal control in a connected vehicle environment.Transportation Research Part C:Emerging Technologies,48,405-421.
[13]Kim,S.,&Lewis,P.(2002).Data quality.ACM SIGMOD Record,31(3),54-57.
[14]Adadi,A.,&Berrada,M.(2018).Peeking inside the black-box:a survey on explainable artificial intelligence (XAI).IEEE Access,6,52138-52160.
[15]Åström,K.J.,&Murray,R.M.(2010).Feedback systems:An introduction for scientists and engineers.Princeton university press.
[16]Moritz,S.,&Bartz-Beielstein,T.(2017).imputeTS:Time series missing value imputation in R.The R Journal,9(1),207.
[17]Kendall,M.G.(1976).Time-series.Charles Griffin &Company Ltd.
[18]Said,S.E.,&Dickey,D.A.(1984).Testing for unit roots in autoregressive-moving average models of unknown order.Biometrika,71(3),599-607.
[19]Hamilton,J.D.(1994).Time series analysis.Princeton university press.
[20]Cover,T.M.,&Thomas,J.A.(2012).Elements of information theory.John Wiley &Sons.
[21]Brockwell,P.J.,&Davis,R.A.(2016).Introduction to time series and forecasting.Springer.
[22]Box,G.E.P.,&Jenkins,G.M.(1976).Time Series Analysis,Forecasting and Control.San Francisco:Holden-Day.
[23]Rissanen,J.(1978).Modeling by shortest data description.Automatica,14(5),465-471.
[24]Akaike,H.(1974).A new look at the statistical model identification.IEEE transactions on automatic control,19(6),716-723.
[25]Schwarz,G.(1978).Estimating the dimension of a model.The annals of statistics,461-464.
[26]Lütkepohl,H.(2005).New introduction to multiple time series analysis.Springer Science &Business Media.
[27]Ljung,G.M.,&Box,G.E.(1978).On a measure of lack of fit in time series models.Biometrika,65(2),297-303.
[28]Chai,T.,&Draxler,R.R.(2014).Root mean square error (RMSE)or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature.Geoscientific model development,7(3),1247-1250.
[29]Pindyck,R.S.,&Rubinfeld,D.L.(2013).Microeconomics.Pearson Education.
[30]Harrison,C.,Eckman,B.,Hamilton,R.,Hartswick,P.,Kalagnanam,J.,Paraszczak,J.,&Williams,P.(2010).Foundations for smarter cities.IBM Journal of Research and Development,54(4),1-16.
[31]Rahm,E.,&Do,H.H.(2000).Data cleaning:Problems and current approaches.IEEE Data Eng.Bull.,23(4),3-13.
[32]Sutton,R.S.,&Barto,A.G.(2018).Reinforcement learning:An introduction.MIT press.
[33]Pan,S.J.,&Yang,Q.(2010).A survey on transfer learning.IEEE Transactions on knowledge and data engineering,22(10),1345-1359.
[34]Snoek,J.,Larochelle,H.,&Adams,R.P.(2012).Practical bayesian optimization of machine learning algorithms.Advances in neural information processing systems.

 京公网安备 11011302003690号
京公网安备 11011302003690号


