



- 收藏
- 加入书签

基于Hadoop的推荐算法优化
 打开文本图片集
打开文本图片集


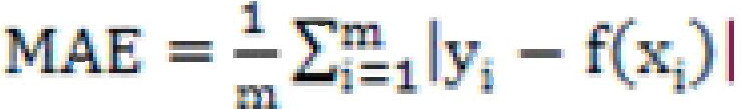
摘要:在现代化的今天,我们的周围被数量众多的数据所环绕,如何从这些数据中得到自己想要的内容成为了不可逃避的话题。由于数据量每天都在大量增加,继续使用传统的推荐系统来进行数据的推荐已经不在适合,可能会出现推荐不准确、数据处理速度过慢等情况,导致用户无法准确的得到自己想要的结果。针对以上情况,本实验使用Hadoop框架,利用Hadoop分布式计算的特点并行处理大量数据,提高运行的效率[1]。并采用均值漂移聚类算法对数据集进行处理,解决矩阵稀疏性的问题,使推荐精度提高。
关键词:Hadoop 均值漂移聚类 推荐算法
0 引言
大数据时代的来临,使大量的资源信息充斥着人们的生活,无论信息生产方还是信息消费方,这都给他们带来了比较大的问题。每一天都要面对着成千上万的数据信息,如何在这众多的数据中得到自己想要的数据无疑成为了一件令人头疼的事。在此情形下,推荐系统应运而生。对于用户和信息,推荐系统能够主动将他们建立联系,不仅可以帮助用户去发现对自己有用的信息,而且对于某些信息,系统会去推测用户是否对其感兴趣,并将其认为用户可能会感兴趣的物品推送到用户的面前,不仅用户享受到了可以快速得到自己心仪物品的便利,推送方也得到了推行的成果[2]。但是在单机模式下,计算速度严重限制了其发展,在这种情况下,我们想到了可以使用hadoop来解决该问题,而对于推荐的准确度,是以用户对物品的评分为前提的,如果用户对物品的评分的数据量不足,会出现推荐准确度不高等问题,由此我们提出使用聚类算法来解决推荐精度不高这一问题。
1 Hadoop系统
Hadoop是一个分布式的系统架构,它可以对数据进行分片的处理,即将海量的数据分到不同的节点中进行各自的处理从而提升自己的计算效率[3]。Hadoop中两个最重要的组成部分是HDFS和Map Reduce。HDFS主要用于进行数据的存储,与MySQL进行数据的存储不同,HDFS是用于分布式的系统上,也就是说它可以管理多台机器上的数据或者文件。同时HDFS对硬件的要求也不高,可以部署在一些廉价的硬件上面。同时它也具有着高吞吐量的特点,因此对于那些数据集特别大的数据,可以起到明显的优化效果[4]。而Map Reduce则为海量的数据提供了计算,它的计算来源就是HDFS中存储的数据。
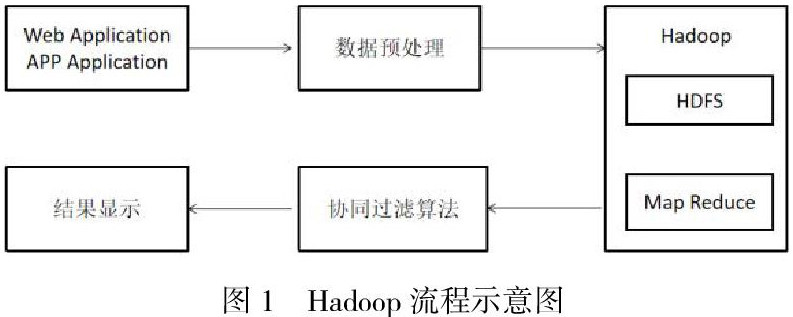
Hadoop主要有以下几个优点:①可靠性。Hadoop的存储方式是按位存储且经历了长时间的考验,因此深受人们的信赖。②可扩展性。Hadoop一般是有一个主节点和多个从节点的构建方式,从节点的数量可以随着需要动态的进行增加。③有效性。Hadoop的众多节点之间是可以进行数据的交换与移动,同时这种特性也保证了各个节点之间的动态平衡性,因而处理数据的速度也就变得很快。④容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。同时Hadoop的成本也比较低,是开源的。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,项目的软件成本会大大降低。使用Hadoop的大致流程图如下:
2 协同过滤与均值漂移算法
2.1协同过滤算法
协同过滤算法是是一种比较经典的推荐算法,它主要是通过获得用户对于物品的过往评分,得到用户评分的标准,从而推测出用户可能会喜欢哪些相似的物品,然后对这些相似的物品进行排序,再将排序后的结果,从高到低对用户进行推荐[5]。一般是将用户对物品的评分来构建以用户为行坐标,以物品为纵坐标的二维矩阵,矩阵的内容为用户对物品的评分。最后通过计算数据的相似度来由高到底的进行推荐。计算相似度的方法一般有Pearson相关系数法,余弦相似度等,本文采用的方法是余弦相似度法[6],公式如下:
其中,,分别是用户u和用户v对所有的物品的评分,表示用户u和用户v共同进行了评分的物品,是用户u对物品i的评分值,用户v对物品i的评分值[7]。然而并不是所有的用户都会对物品进行评分,因为在矩阵中会有很多的空位,这样会导致计算得到的结果不准确,为了缓解矩阵稀疏这一问题,引入了均值漂移算法来对矩阵的稀疏性进行处理,然后再进行相似度的计算。
2.2均值漂移聚类算法
均值漂移聚类算法是先初始确立一个中心点,同时也设置一个长度d,计算在以中心点为圆心,d为半径的圆中所有的点与中心点的向量,得到所有的向量后,计算其和的平均值,称为是偏移均值,将中心点移动到偏移均值处,重复以上步骤,直到满足一定条件时结束[8]。
在得到中心点集后,会寻找到目标用户的最近邻,做出评分预测,并将预测得到的结果写会到矩阵中,将原本没有数据的区域,填上我们所计算得到的预测值,这样可以有效的降低矩阵的稀疏性。最后再进行协同过滤计算,得到推荐结果。公式如下:
其中,Sh表示以x为中心点,半径为h的区域,k表示包含在Sh范围内点的个数,xi表示的是包含在Sh范围内的点[9]。
3实验与分析
3.1实验环境
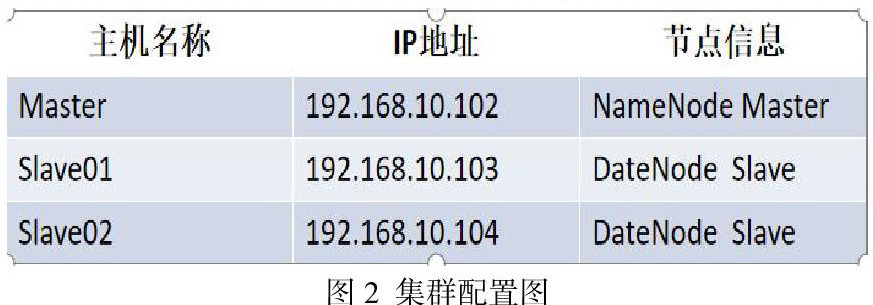
本文的实验平台基于VMware进行搭建,实验环境是CentOS7操作系统,在操作系统上搭建Hadoop集群。集群主要包括一个主节点和两个从节点。每个节点上的实验环境相同,最后在集群上运行MapReduce并行化协同过滤算法,对不同的推荐算法进行实验并比较。集群的配置如下:
3.2比较标准
基于本文提出的对稀疏矩阵进行优化处理后得到的矩阵,与未优化的矩阵进行对比运算。本文用实际评分与预测评分值之间的差值平均绝对偏差MAE[10]作为评价指标来反映算法的准确性,公式如下:
其中,y表示实际的评分数据,x表示经过均值漂移聚类算法得到的预测的评分数据。MAE的值越小,表示推荐算法越准确。
3.3实验分析
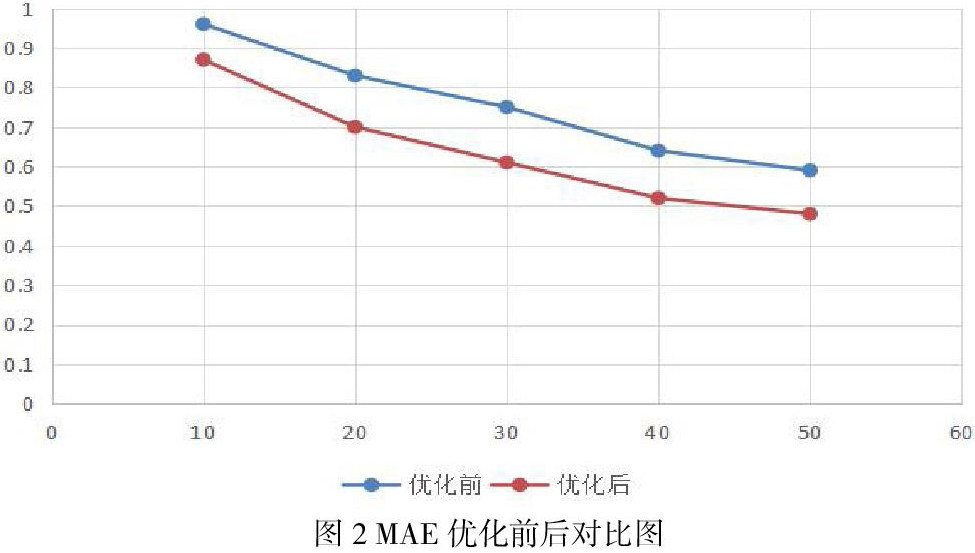
分别使用协同过滤算法直接进行测试,和使用均值漂移聚类算法进行矩阵稀疏的处理之后再进行协同过滤算法进行测试。将二者的结果进行比较,结果如下图所示:
4结论
本文通过使用均值漂移聚类算法,首先对用户-物品的评分矩阵进行处理,降低矩阵的稀疏性之后再使用协同过滤算法进行相似度的计算,提升了推荐的准确率。通过大数据 Hadoop 平台,对庞大的数据集进行分析提取,不但得到了相应的推荐数据,同时也提高了处理的速度,满足了在短时间内即可得到推荐的要求。
参考文献
[1]蒋春燕.基于Hadoop技术的图像视频处理的研究与应用[J].2016
[2]李玉.基于社会化媒体热点发现的高校图书馆书目推荐研究[J].2015
[3]伍午阳.基于大规模网络语料的中文新词发现技术研究[J].2017
[4]沈力.基于大数据的智慧电网技术[J].2019
[5]郭小雨,尤海鑫.大数据环境下智能推荐系统中协同过滤算法研究[J].科技经济导刊.2021
[6]郎鹏程.基于用户协同过滤推荐技术的研究与实现[J].2017
[7]潘超.资源库的设计与推荐系统的研究[J].2015
[8]吕佳.基于核均值漂移聚类的改进局部协同训练算法[J].重庆师范大学学报.2020
[9]刁泽浩.自由活体动物的动态跟踪算法研究[J].2018
[10]杨慧慧.基于Hadoop的协同过滤推荐算法的研究[J].电子世界.2019

 京公网安备 11011302003690号
京公网安备 11011302003690号


