



- 收藏
- 加入书签

藏文不自由虚词添置规则研究
 打开文本图片集
打开文本图片集

摘 要:随着计算机的普及和网络资源的共享,人类已迈进了信息化的时代,计算机成了我们不可缺少的使用工具。同样,藏文信息处理领域也不可缺少。目前藏文虚词研究方面文献很少:2013年公保才让等通过藏文语法中对虚词的定义为线索;分析藏文文本,识别虚词。按照藏文虚词的添置规则进行校对。提出了基于规则和藏文语法相结合的校对算法。2014年高定国等藏语虚词在藏语文本中的作用和使用方法的基础上,分析了计算机识别藏语虚词的难度,提出了计算机识别藏语虚词的方法。2017年拉巴顿珠等材用规则和统计相结合的方法,建立了较为全面的虚词知识库和规则库,并给出切分用虚词分块算法。2019年索南尖措等使用Python语言实现藏文不自由虚词校对算法,细化了校对过程。他们发表的文献和所做的研究对后人做藏文不自由虚词校对研究有着极大的贡献。
本文是参考以上几个文献基础上进行研究和撰写的《藏文不自由虚词添置研究与实现》。对各种虚词进行深入研究,使计算机能够迅速快捷地识别藏文不自由虚词、修改添置正确。提高了藏文虚词的添置准确率,并后续藏文信息处理做出了一定的基础。
关键词:藏文不自由虚词;藏文不自由虚词添置规则;藏文不自由虚词兼类库;
1 藏文不自由虚词分析与研究
藏文是由词构成词组,经过词和词组构成句子,句子和句子将构成语篇。它们之间的连接离不开虚词。虚词又可以分为自由虚词和不自由虚词,其中不自由虚词的添置有一定的要求,它是受前一个音节字的后加字的约束。所以本文着重研究了不自由虚词。
1.1藏文不自由虚词的分类
不自由虚词可以分为以下几种:
(1)终结词 (སླར་བསྡུ།): 用于在句末表示所要表达意思完结。共有 11 个。
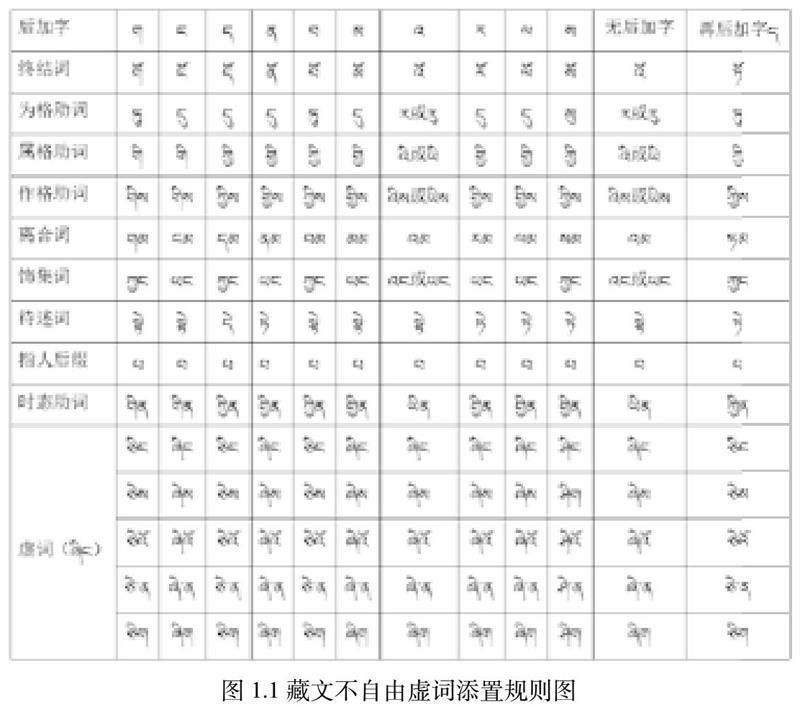
其变体形式形式化的描述为 {གོ,ངོ,དོ,ནོ་,བོ,མོ,འོ,རོ,ལོ,སོ,ཏོ}。添置规则如下图1.1 所示。
(2)为格助词 (ལ་དོན།): 作为业格 (ལས་སུ་བྱ་བ།)、位格 (དགོས་བྱེད།)、于格 (གནས་གཞི།)、做“同体”补语 (དེ་ཉིད།)、做时间状语 (ཚེ་སྐབས།) 等 5 种。其变体形式化的描述为 {སུ,ར,རུ,དུ,ན,ལ,ཏུ}。
(3)属格助词 (འབྲེལ་སྒྲ།): 表示领有与所属关系。其变体形式形式化的
描述为 {གི,ཀྱི,གྱི,འི,ཡི}。
(4)作格助词 (བྱེད་སྒྲ།): 表示行为的实施。其变体形式形式化的描述为
{གིས,ཀྱིས,གྱིས,འིས,ཡིས}。
(5)离 合 词 (འབྱེད་སྡུད།): 在 句 中 既 作 连 词, 又 当 助 词 用,其 变 体 形 式 形 式 化 的 描 述 为 {གམ,ངམ,དམ,ནམ,བམ,མམ,བམ,རམ,ལམ,སམ,ཏམ}。
(6)饰集词 (རྒྱན་སྡུད།): 一般用在名词后起副词作用,用在动词后转做
连词。其变体形式形式化的描述为 {ཀྱང,ཡང,འང}。
待述词 (ལྷག་བཅས): 作连词表示连贯、复指、并列 关系。其变体形式形式化的描述为 {ཏེ,དེ,སྟེ}。
(7)时态助词(ད་ལྟ་བ་གསལ་བྱེད།):用在助动词现在时后面表示动作在进行中。
其变体形式形式化的描述为 {གིན,ཀྱིན,གྱིན,ཡིན}。
(8)虚词 (ཞིང་།) 等 : 作关联、引语、疑问语气助词等。其变体形式
形式化的描述为 {ཞིང,ཞེས,ཞེའོ,ཞེ་ན,ཞིག,ཅིང,ཅེས,ཅེའོ,ཅེ་ན,ཅིག,ཤིང ཤིག,ཤེའོ,ཤེ་ན,ཤིག}。
1.2藏文不自由虚词的添置规则与特殊情况
传统藏文《三十颂》是虚词使用的理论,根据它的不自由虚词添置规则的口诀进行解释
ཀྱང་ཡང་འང་གསུམ་རྒྱན་སྡུད་དེ། །
ག་ད་བ་ས་དྲག་མཐར་ཀྱང་། །
ང་ན་མ་ར་ལ་མཐར་ཡང་། །
འ་དང་མཐའ་མེད་འང་དང་ཡང་། །
以上五句是不自由虚词饰集词的使用口诀,意思是与按照饰集词前一音节字的后加字来判断添置饰集词,也就是当前一音节字的后加字为ག་ད་བ་ས།时,饰集词使用ཀྱང་།;前一音节字的后加字ང་ན་མ་ར་ལ།时,饰集词使用ཡང་།依此类推。
其他不自由虚词的口诀也与饰集词类似,讲述的内容都是不自由虚词的添置受前一音节字的后加字的限制。因此让学者方便了解添置规则我将它转成图,如图1.1所示
藏文不自由虚词添置过程中,大部分不自由虚词依据图1.1所示实行添置,但以但有些特殊:再后加字ད་有经常会省略:在藏文中后加字ན、ར、ལ后面的再后加字ད་基本情况下都是略去,这时若按照规则实行添置,则会添置错误。例:བསྐྲུན་ཏོ,若依据上图1提到的规则实行校对,不自由虚词ཏོ།应该为添置错误,因为后加字为ར།,所以不自由虚词应添置终结词རོ།,但是由于གྱུར།略去了再后加字ད།,所以根据再后加字为ད的规则去校对添置终结词虚词ཏོ没有错误。
ཞེས与ཤེས:依据图1.1所示在后加字ས་应该添置ཤེས,但由于ཤེས་既是实词也是虚词,实词时候是“知道”的意思,因此添置ཞེས代替ཤེས།。
1.3处理藏文不自由虚词相关技术与难点
藏文虚词的自动识别根据以《三十颂》的虚词添置规则理论及探索收获作为根本,通过传统的文法规则和规律性语料库的统计,设计出相应的虚词库及消岐算法,让计算机大量藏文文本中智能识别实词与虚词,并在识别过程中提取虚词加以特殊标记称之为虚词的识别。
本课题基于python语言进行研究与实现,字典的不自由虚词兼类主要采用了从大规模的语料库中获取了本研究所需的语言信息并建立了相应不自由虚词库最大匹配处理技术,通过训练的情况进行优化并藏文虚词在信息处理过程中的不自由虚词添置有误进行了提高。
由于有些藏文不自由虚词的特殊情况引起了一下几个难点:
1.兼类性。一些不自由虚词既是实词又是虚词。例:སུ།(谁)ངོ་།(脸)、མི།(人)等,这些藏文不自由虚词的兼类性添加了计算机判断藏文不自由添置规则的难度。
2.组合性。有部分藏文不自由虚词与一个组合在一起。例:ཡི་གེ、གོ་རིམ།等。这些里参与不自由虚词,但它不是不自由虚词。是一个不可分割的组词,因此这类大大添加了识别藏文不自由虚词的难度。
3.黏着性。在一个不自由虚词的前一个音节字没有后加字或后加字为འ་时,不自由虚词འི་ཡི་འིས་ཡིས་ར་རུ་འང་འམ།等这些黏着在前一个音节字词尾。例:དཔྱིད་ཀར་སླེབས།,句子中དཔྱིད་ཀ没有后加字,而虚词ར།黏着在དཔྱིད་ཀ词上,与ཀར།字组成同形。这些黏着变体性添加了识别藏文不自由虚词添置规则的难度。
4.结合性。有些不自由虚词与指人名词后缀添加在本来名词的后面变成表示事物或动作相关的名词。例:ཟླ་བ།(月亮)、དཀར་པོ།(白色)等。这类藏文不自由虚词也会增加了难度。
2 藏文不自由虚词添置规则算法
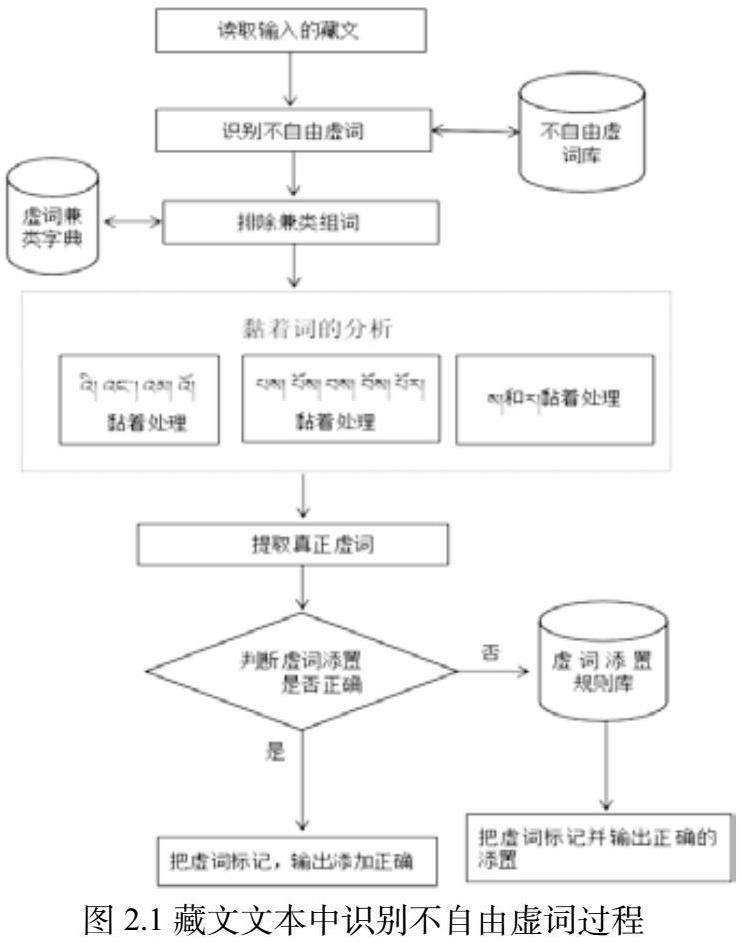
读懂藏文的人在读藏文句子时,主要通过语义来判断藏文不自由虚词,可计算机不像人一样将语义来识别。所以根据藏文不自由虚词添置规则和计算机识别藏文不自由虚词的难点解析,将制定了以下几个步骤:
第一步:读取的藏文文本跟不自由虚词库进行字典匹配寻找及识别出不自由虚词。
第二步:读取的藏文文本跟不自由虚词的兼类库进行字典匹配寻找及识别出有兼类性的不自由虚词排除。
第三步:读取的排除兼类性的藏文文本中的黏着性的虚词进行分析和处理。
第四步:提取了该藏文文本里所有不自由虚词,并充分利用不自由虚词添置规则进行分析是否添置有误。
第五步:处理识别出来的藏文不自由虚词,有误进行修改正确添置规则。
以上算法如图2.1所示
3 藏文虚词研究结果分析
3.1识别藏文不自由虚词
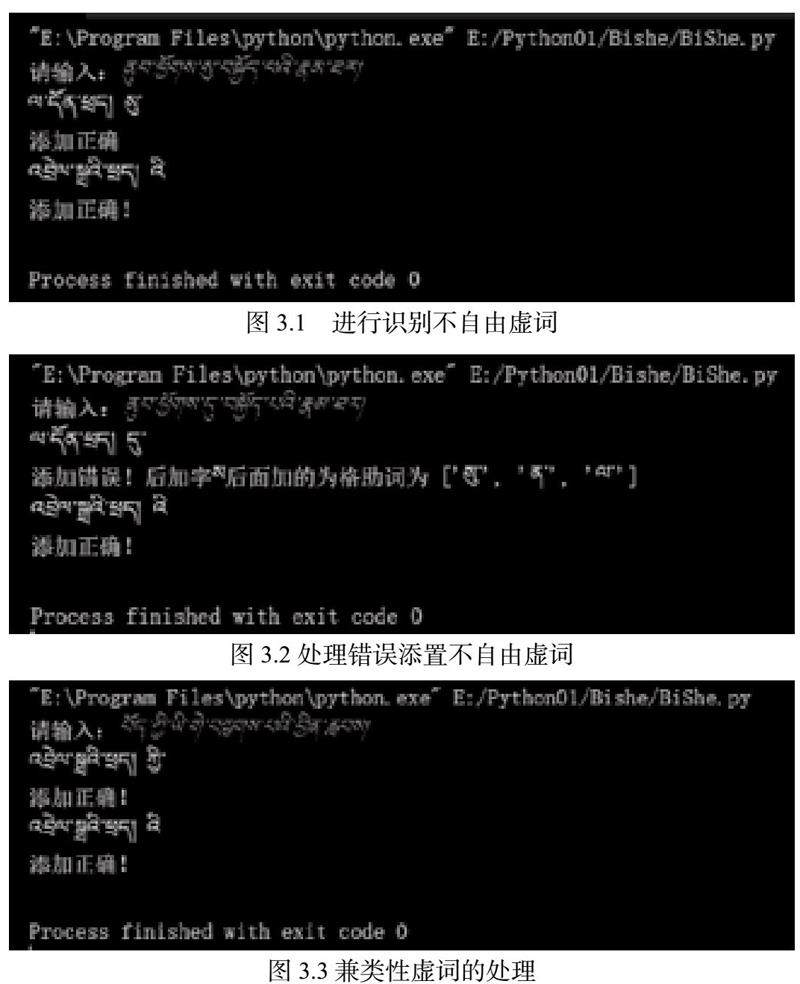
藏文不自由虚词的识别的结果如图3.1所示
从如图3.1看出,在输入读取的藏文句子中是识别出来终结词སུ།和属格助词འི།。况且属格助词འི།是黏着性虚词。因为上面藏文虚词不自由虚词虚词添置正确,不用处理正确的添置。
如果不自由虚词添置有误的结果如图3.2所示
从图3.2看出,在输入读取的藏文句子中是识别出来添置有误的不自由虚词。上面的为格助词དུ།使用错误,因为ཕྱོགས།词的再后加字为ས།。按照藏文不自由虚词的添置规则后加字ས།后面接续的为格助词应该为སུ།或者ན་ལ།也可以。所以计算机识别不自由虚词和处理都是正确。
3.2藏文不自由虚词的兼类性处理
藏文的不自由虚词的如图3.3所示
从图3.3看出计算机识别出来了两个不自由虚词。按照藏文虚词来讲ཡི།是属格助词的虚词,但这里没有识别出来。因为它是跟ཡི་གེ组词的一个名词这里并不是一个单纯的虚词。
3.3藏文兼类虚词库的不健全引起错误
对本文实现结果分析,发现大部分错误是因为库的不健全导致的。如图3.4所示
根据匹配字典的藏文虚词识别规则,例:ཡང་དག是一个不在库里的词,它会把ཡང་།识别成藏文虚词。按理ཡང་།识别不自由虚词是没有错误,但由于藏文虚词有组合性的问题。这时候的ཡང་།不是个虚词是跟དག组合的一个名词。这样的错误比较好处理,在库里加上即可。补充字典来健全完善该类问题。
结束语
让计算机智能校对藏文不自由虚词添置,不仅能够省去人工校对的麻烦,还能提高工作效率。此次论文在完成过程中按照不自由虚词分类和规则周全的介绍了藏文不自由虚词添置。让计算机进行识别兼类性和黏着性,以及组合性结合性的不自由虚词。研究藏文不自由虚词是藏文信息处理的基本工程。在建立藏文兼类虚词规则库时,由于语料中的词性是人工进行增加。至今在藏文信息处理领域没有通用及标准的词性集集合,因此,对兼类不自由虚词添加的词性的精确度相对不敢保证;藏文兼类虚词库和不自由需词库拥有可填充和扩展性。还是由于个人的能力欠缺,该课题的功能和性能都有待完善。因为,本课题研究结果与实际人工分析虚词还有一定的差距。还要在往后的研究处理中继续大规模的语料收集进行深刻探究。
参考文献
[1] 公保才让 安见才让.藏文虚词添置校对算法研究与实现.青海民族大学藏文信息处理和软件研究所
[2] 高定国 扎西加 赵栋材.计算机识别藏文虚词的方法研究.西藏大学藏文信息技术研究中心
[3] 拉巴顿珠 欧珠 赵栋材.藏文自动分词系统中虚词识别算法研究.西藏大学藏文信息技术研究中心
[4] 索南尖措 陈家威.基于Python的藏文不自由虚词校对算法研究与实现.西藏大学信息科学技术学院

 京公网安备 11011302003690号
京公网安备 11011302003690号


