



- 收藏
- 加入书签

印刷质量事故数据向DeepSeek问题库转化的方法研究
摘要:本研究旨在探索将印刷质量事故数据有效转化为DeepSeek 问题库的方法。印刷质量事故数据来源于实际生产过程中的各种故障记录,这些数据蕴含着丰富的经验和知识,对于提升印刷质量和效率具有重要意义。然而,这些原始数据往往杂乱无章,难以直接应用于智能化分析和决策支持。因此,本研究通过一系列预处理步骤,包括数据清洗、标注和格式转换,旨在将这些原始数据转化为结构化的、易于机器理解和处理的问题库。DeepSeek 作为一种先进的问答系统,能够基于大规模知识库提供精确的问题解答服务。本研究将探讨如何将印刷质量事故数据与DeepSeek 模型相结合,构建适用于印刷行业的问题库,并为后续的智能化分析和应用提供基础。
关键词:DeepSeek;事故数据;印刷质量事故
1.前言
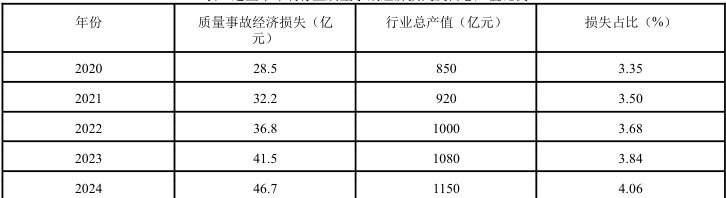
质量事故是制约印 速发展的重要原因之一。近年来,市场竞争日趋激烈,顾客对印刷品 流失,顾客抱怨,甚至是法律上的纠纷。根据有关资料显示,在过去的五年 损失已达几十亿元,而且这个数字还在逐年增加。如表1 所示,质量事故造成的经济损失在工业产值中所占的比重也呈逐年上升趋势。
DeepSeek 问题库通过分析历史事故数据,能预测潜在风险和质量事故,帮助企业采取预防措施。它还能提高生产效率,通过快速查询相似案例解决方案,减少生产中断。此外,它提供质量改进建议,通过对比分析案例,帮助企业优化生产流程,提升产品质量。
2.印刷质量事故数据概述
2.1 印刷质量事故类型
在多色印刷过程中,套印错误是一个常见的问题,它指的是不同颜色的油墨在重叠时没有精确对齐,这种色彩重叠的不精确性会严重影响印刷品的视觉效果和信息的有效传递。据相关统计,套印错误在所有印刷质量事故中占据了大约20%的比例。这种错误不仅会导致产品报废,还会增加生产成本,从而对品牌形象造成损害。
图文不清是指印刷品上的文字或图案边缘出现模糊不清或有重影的现象,这种情况在印刷过程中大约占15%的比例。图文的不清晰会直接影响印刷品的可读性和视觉效果,从而降低产品的整体质量,并且影响信息的准确传递,对产品的市场表现产生不利影响。
纸张皱折是影响打印质量的另一个重要因素,它会破坏打印的平坦性和美感。在所有打印问题中,纸张皱折大约占 12%的比例。纸张皱折不仅会导致打印效果不佳,还会提高废品率,进而影响印刷品的整体质量,对印刷品的美观和实用性造成负面影响。
油墨干燥不充分是印刷过程中另一个需要关注的问题,它会导致印刷物表面出现粘污现象。这种情况在所有印刷相关事件中大约占10%的比例。油墨干燥不充分不仅会延长生产周期,增加生产成本,还会降低生产效率。此外,它还可能影响顾客的满意度,因为印刷品表面的粘污会直接影响产品的外观和质量。
2.2 数据来源与收集方法
数据的来源是多元化的,主要分为企业内部数据库和生产记录两大类。企业内部数据库中存储了各种关键信息,包括但不限于订单详情、生产过程中的关键参数、以及产品经过质量检测后的各项指标数据。而生产记录则详细记录了设备的运行状态、原材料的使用情况,以及在生产过程中出现的产品质量问题等重要信息。
在数据收集方面,采用了人工录入和系统自动采集两种方法。对于那些无法通过自动化手段采集的数据,我们采取了人工录入的方式,并且企业为此制定了详尽的规范和流程,以确保数据的准确性和完整性。与此同时,系统自动采集则利用先进的技术手段,高效且准确地收集设备运行数据和质量检测数据。然而,对于那些非结构化的数据,如照片、视频等,仍然需要人工进行整理和录入。举个例子,一家印刷企业通过系统自动采集设备的运行参数,并结合人工录入的质量事故描述和原因分析,成功建立了一个全面而详尽的质量事故数据库。
3.DeepSee技术原理与应用
3.1 DeepSeek 模型简介
基于 Transformer 架构构建的 DeepSeek 模型在自然语言处理领域能力卓越,它利用了 Transformer 架构核心的自注意力机制(Self-Attention Mechanism),这种机制使得模型在处理序列数据时能够动态地关注输入序列的不同部分,从而有效地捕捉文本中的长距离依赖关系以及丰富的语义信息。与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,DeepSeek 模型无需顺序处理序列数据,这不仅大幅提高了计算效率,还增强了模型的并行性。因此,它能够更加高效地处理大规模文本数据,为自然语言处理任务提供了强大的支持。
3.2 在印刷行业的潜在应用场景
智能客服方面:以 DeepSeek 作为印 客户问题,且世纪开元智能客服能达到响应速度提升30%、准确率提高 10%-20% 的作用。生产流程优化层面:借助 DeepSeek 分析印刷生产数据,用于预测设 生产成本。质量检测与问题诊断部分:通过 DeepSeek 实时检测印 以此指导操作人员进行调整。智能设计范畴:依靠DeepSeek 依据需求生成设 世纪开元应用DeepSeek 可实现客户需求规范化,达成提升设计方案生成速度和智能 及提高客户满意度的目的。
4.数据转化前处理
4.1 数据清洗
在进行数据清洗的过程中,我们通常会采用Python 编程语言中的pandas 库来进行数据的处理工作。通过使用pandas 库中的 drop_duplicates函数,我们可以有效地删除数据集中的重复项,以确保数据的唯一性。此外,为了处理数据集中的缺失值,我们会利用isnull函数来识别这些缺失值,然后通过dropna函数将它们从数据集中移除,从而保证数据的完整性。除了这些自动化的方法,我们还会进行人工检查,通过逻辑判断来修正那些可能由于各种原因导致的错误数据。通过这些综合性的数据清洗步骤,我们能够显著提高数据集的准确性和完整性,为后续的数据分析和处理工作打下坚实的基础。
为了更直观地展示数据清洗的效果,下面提供了一个示例表格,其中包含了清洗前后数据的对比。通过对比表格中的数变化,以及清洗工作对数据质量的提升。

通过观察表格中的数据,可以清晰地了解到数据集在清洗前的具体情况。在清洗前,数据集的总量达到了1000 条记录。然而,在这些记录中,存在着一些问题,包括重复的数据条目,数量达到了50 条;还有缺失数据的情况,共计80 条;以及错误的数据条目,数量为 30 条。在经过一系列的清洗工作之后,我们成功地移除了那些重复和错误的数据条目。同时,对于那些缺失数据的条目,我们也采取了相应的措施,使得这些数据得到了大幅的减少。最终,数据集的总量经过清洗后变为了950 条。通过这一系列的清洗工作,数据的质量得到了显著的提升,为后续的数据分析和处理工作奠定了坚实的基础。
4.2 数据标注
数据标注是给数据添加有意义的标签和描述,帮助 DeepSeek 模型更好地理解和学习数据。对于印刷质量事故数据,我们确定了包括设备故障、操作不当、原材料问题和环境因素在内的事故原因类别。准确标注这些原因有助于模型分析事故根源,预防事故。
影响程度分为轻微、一般、严重三个等级。轻微影响仅对产品外观造成微小瑕疵,不影响使用;一般影响会影响产品性能或外观,但产品仍可使用;严重影响则导致产品无法使用,需报废或返工。标注影响程度有助于企业评估事故严重性,合理分配资源处理。
处理措施记录了针对事故采取的具体方法,如更换设备部件、调整操作流程、更换原材料等,为企业提供解决方案参考。若事故由原材料质量问题引起,处理措施可能是更换供应商并严格检测新批次原材料。
4.3 格式转换
将原始的印刷质量事故数据转换为DeepSeek 模型通常接受的JSON、文本等格式的数据输入,在这一格式转换过程中借助Python 的相关库进行数据处理。
经过清洗和标注的印刷质量事故数据经代码转换为 JSON 格式字符串并作格式化输出后更易于阅读,其中ensure_ascii=False 参数可确保中文字符正确显示而非转义为ASCII 码,indent=4 参数能让JSON 数据结构因缩进4 个空格而更加清晰。对于转换为文本格式,可以将数据按照一定的格式进行拼接。示例代码如下:
\#假设data 是清洗和标注后的印刷质量事故数据,是一个列表,每个元素是一个字典 [
"事故编号":"001",
"事故类型":"套印不准",
"事故原因":"设备故障,传动齿轮磨损",
"影响程度":"严重",
"处理措施":"更换传动齿轮,重新校准设备"
"事故编号":"002",
"事故类型":"色彩偏差",
"事故原因":"油墨调配不当",
"影响程度":"一般",
"处理措施":"重新调配油墨,调整印刷参数"
上述按照指定格式将印刷质量事故数据 且以换行符分隔各事故信息、用两个换行符分隔不同事故以便阅读处理的代码,通过格式转换使数据满足DeepSeek 模型输入要求,为后续问题库构建及模型训练奠定基础。
5.问题库评估与优化
5.1 评估指标设定
为全面、客观评估DeepSeek 问题库在印刷质量事故处理中的性能和效果而确定的关键评估指标如下:准确率(Accuracy),其为分类模型正确预测的样本数占总样本数的比例,于印刷质量事故问题库中表示问题库给出的正确回答数量占总回答数量的比例,越高则说明问题库的回答越准确,计算公式为:

5.2 评估方法与工具
人工标注这一行为,即邀请印刷行业的专家以及经验丰富的质量管理人员组成评估团队,进而对问题库的回答开展人工标注活动,评估团队依据预先制定的评估标准针对每个回答加以判断,确定其正确、完整、有用等情况。就一个关于印刷过程中出现色彩偏差问题的回答而言,评估人员会从回答是否准确指出色彩偏差的原因、是否提供有效解决措施、语言表达是否清晰易懂等方面实施评估。
自动评估工具使用一些自然语言处理的评估工具如 BLEU(Bilingual Evaluation Understudy)、ROUGE(Recall-OrientedUnderstudy for Gisting Evaluation)等,BLEU 主要用于评估生成文本与参考文本间相似度,于本研究中可用来评估问题库回答与标准答案或专家回答间的相似度,ROUGE 侧重于评估生成文本对参考文本关键信息的召回情况,使用BLEU 评估工具时把问题库回答当作生成文本、将专家给出的标准答案当作参考文本并通过计算BLEU 得分评估回答准确性与相关性,这些自动评估工具能快速处理大量数据以提高评估效率但存在一定局限性无法完全替代人工评估。
5.3 优化策略
调整 DeepSeek 模型超参数(如学习率、隐藏层大小、注意力机制参数等)的操作,通过实验和分析以找到最优参数组合来提高模型学习能力与泛化能力,可使用网格搜索(Grid Search)或随机搜索(Random Search)等方法,像在网格搜索中要定义参数网格,学习率在[0.001,0.0001,0.00001]取值、隐藏层大小在[128,256,512]取值,之后对各参数组合训练评估以选性能最优组合。
补充数据方面,需依据评估中所发现问题,补充更多印刷质量事故数据以及相关领域知识,若发现问题库针对某些特定类型事故(像新型印刷设备故障导致的事故)回答准确率偏低,便收集更多此类事故数据并加以标注后添加进问题库,以此丰富模型知识储备,与此同时,收集一些行业标准、技术规范、最新研究成果等作为补充知识来提高问题库回答的准确性与权威性。
优化知识图谱:对已构建的知 的完善等方面内容。在评估时若发现知识图谱中部分实体关系标注不准确致使 关系 注与修正,可借助更先进的实体识别及关系抽取技术提升其质量。通过引入深度 NER)模型更精准地识别印刷质量事故数据中的实体,再利用图卷积网络(GCN)等技术抽取并优化实体关系,以此提升知识图谱的准确性与完整性。
结论
综上所述,DeepSeek 问题库在印刷质量事故处理中的应用取得了显著成效。通过构建基于印刷质量事故数据的问题库,并对其进行评估与优化,有效提高了问题库的准确性和覆盖性。在实际应用中,DeepSeek 问题库不仅能够帮助印刷企业快速准确地诊断和解决设备故障,还能为 策支持,优化生产工艺,提高印刷品质量。此外,问题库的应用还显著降低了印刷质量事故的发 率。因此,DeepSeek 问题库在印刷行业中具有广泛的应用前景和重要的实践价值。未来,我们将继续完善和优化 DeepSeek 问题库,探索更多应用场景,为印刷行业的智能化和高质量发展贡献力量。
参考文献
[1] 刘正超,孔祥祯.面向智能制造工程的"人工智能"课程教学问题库的建设[J].科技视界, 2024, 14(2):18-21.
[2] 楚小桃.人工智能专题类问题解析— 田忌赛马 人鬼过河"博弈类问题求解[J].中国科技教育, 2022(10):62
[3] 邓菡彬.人工智能的问题可能是人本身的问题——陈抱阳访谈[J].西湖, 2020(11):8.
[4] Shen Gaohan,Liu Jianping."DeepSeek+"融合出击 智慧"申蓝"再出发——洋山 VTS 创新实践海事人工智能应用新模式[J].中国海事, 2025(3):78-78.
[5] Wang Y M , Chen T J .The rise of AI in healthcare education: DeepSeek and GPT-4o take on the 2024 Taiwan Pharmacist Exam[J].Journal of the Chinese Medical Association, 2025, 88(4):338-339.

 京公网安备 11011302003690号
京公网安备 11011302003690号


