



- 收藏
- 加入书签

地区文化产业发展数据挖掘系统
 打开文本图片集
打开文本图片集
摘要:近20年来,我国的文化产业持增长状态,数据量显著增多,随着因特网和大型数据库的上台,“信息如山但知识如沙”的问题越来越明显。如何让我们从数据中寻找那些被隐藏的有用信息变成了一个热门的话题。呼和浩特原意为绿色的城,它集草原文化、历史文化、民族文化于一体,广播影视业、图书出版业等多种产业并存,这篇设计简要介绍了我国呼和浩特地区的文化产业现状,并根据其数据进行一些简单的数据挖掘操作,通过简单的数据挖掘,找出文化产业间的联系与趋势,根据联系与趋势给出相应的对策。
关键词 文化产业 数据挖掘
Abstract
Held over the past 20 years, China's cultural industry growth status, the data volume increased significantly, as the Internet and a large database, "information mountain but knowledge such as sand" problem is more and more obvious. How to let us find the useful information is hidden from the data became a hot topic. Hohhot original intention for the green city, it sets the prairie culture, history and culture, national culture, radio, film and television industry, book publishing and other industries, this article design brief introduce the situation of Hohhot areas in China's cultural industry, and according to the data carry on some simple data mining operations, through simple data mining, and find out the relation between culture industry and trends, according to the trend of contact and corresponding countermeasures are presented.
Key words: cultural industry, data mining
一、我国文化产业现状
中国大部分文化企业的企业规模小、水平低并且资源不集中。中国文化产业中有90%以上的企业都是中小型企业,由于每个中小型企业都有自己独特的体质和企业文化,这致使我国整个文化产业市场的市场化程度偏低,从全局视角上看,中国的文化产业现在还处在薄弱状态。
中国文化及相关产品的消耗虽然高速增长,但是文化产业企业少。中国文化产业在近几年来发展非常迅速。中国文化产业与美国,英国,法国等这些发达国家对比而言依然存在着相当大的距离,所以我国文化产业市场的发展空间十分宽广。
中国文化产业内部存在“此消彼长”的现象,在“反四风”的趋势下,舞台演出制作公司及演出市场有六成倒闭,艺术工艺品、画廊等行业持续低落;中国的主题公园,文化产业园以及影视基地大多数存在大面积亏损。除此之外,我国文化产业借用资本市场有了不同寻常的成长,文化企业在创业这一模块中的表现的十分亮眼,被资本市场当作“新宠”,同时BAT等大型龙头互联网企业也纷纷致力于文化产业发展中,我国文化产业无时无刻发生着变化。
二、问题的提出
呼和浩特集草原文化、历史文化、民俗文于一体,在当今能源短缺、空气污染严重等多种不利因素下,文化产业作为一个低投入、无污染、耗能低并且收入高的一种新型产业,慢慢的成为人们的新宠。探索呼和浩特市地区文化产业中的规律与趋势将成为不可争议的事实。
三、数据收集与分析
通过查询内蒙古自治区呼和浩特市统计局中2005至2015这11年的国民经济和社会发展统计公报,在这几篇报告中的第九节文化、卫生、和体育中筛选出有关文化的数据,经过整理我们可以得到下面(如表1所示)这张表格。
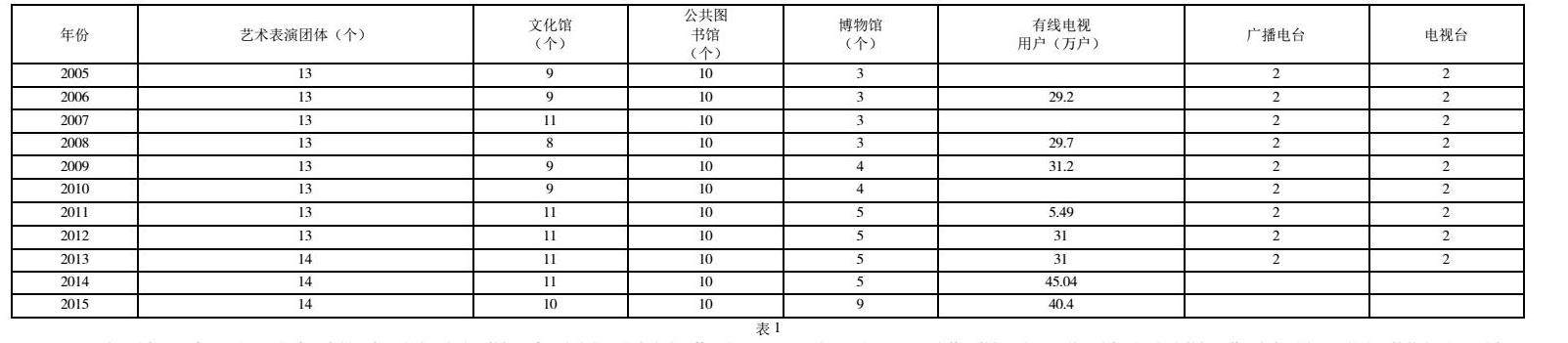
通过上表,我们可以直观地发现电视台、广播电台、公共图书馆的数据一直没有变化,艺术表演团体只在2013年那里变化了一次,并且变化幅度为1。博物馆的折线图变化不大,一直呈上升趋势,文化馆数量一直存在波动,但始终在10前后徘徊,最后我们可以发现,有线电视用户这一折线空缺点很多,而且波动很大,我们可以先通过数据挖据方法找出有线电视用户人数与其他类别之间的关系,从而分析出有线电视用户的成长趋向,最后根据得出的结论来辅助有关部门进行决策。
四、数据缺失的原因
在数据库的搭建与维护中,以现在的技术手段,我们不能避免数据属性值缺失的问题。所以,在大部分情况下,信息系统不是完善的。有很多原因可以导致数据缺失,常见的数据缺失原因大概为下面这几类。
(一)有些信息暂时无法获取
例如在上述2005年的数据中,可能由于当时科学技术不发达,统计局无法统计出当时有线电视用户的人数,就致使这一部分属性值存在缺失。
(二)有些信息是被遗漏的
如上述2010年的广播人口覆盖率以及电视综合人口覆盖率,可能是因为输入时认为不重要、忘记填写了或对数据理解错误而遗漏,也可能是由于数据采集时设备存在故障、存储介质落后、传输媒体的不先进、以及一些人为因素的原因。
(三)有些对象的某个或某些属性是不可用的
如2014年与2015年的广播电台和电视台被广播电视台取代了,也就是说,对于这个对象来说,该属性值原本是存在的,但是因广播电台和电视台属性合并成广播电视台,原来的属性不存在了。
(四)有些信息(被认为)是不重要的
如艺术团体组成人数,以及他们每年的人口数量变化。
(五)有些信息获取的代价太大
如拥有电视的人口,统计局不可能每年花费大量的资金及人力去统计每年有多少人拥有电视,只能每五年或每十年统计一回。
因为有数据缺失的存在,人们才会使用数据挖掘方法弥补或避免这些缺失问题,并探寻数据中被隐藏的关系。
五、数据挖掘的方法
数据挖掘大体可分为四大类,他们分别是分类算法、聚类算法、关联规则、预测(回归性分析),每一大类中又存在着不少经典的算法。常用的数据挖掘方法有。
(一)决策树
决策树是一种数据分类算法,它凭借信息论的原理,对数据进行分类,适用于离散值属性、连续值属性,生成一个近似于流程图并且结果在树底端的树状构造图。
(二)聚类分析
聚类分析是一种聚类算法,是将一个数据集合划分成两个或多个类别的过程,聚类之后的每个分类子集中的数据有比较多的共同点,不同子集中的数据相似度低。
(三)关联规则
关联规则在数据挖掘中的研究方法比其他方法活跃,它的最初是为了寻找超市买卖数据库中不同货物中间的关系,其中一个比较经典地例子是:70%购买牛奶的顾客倾向于同时购买面包。
(四)统计分析
统计分析是WEB网站中基本而通用的方式,是通过点击率、求中值求平均和等等信息来分析用户动向的方法,统计分析虽然不能够对数据进行更深层次的分析,但是这些已经分析出来的数据对于服务站点的优化与辅助市场做出决策等的帮助很大。
(五)贝叶斯网络
贝叶斯网络算法是一种可以快速生成并且适合预测性建模的分类算法,它通过两个或两个以上的独立属性去推测另一个已有属性中空缺数据的大概率的取值。
(六)人工神经网络
人工神经网络是一个模拟大脑中神经原细胞,对数据开始分布,经过信息手段建立的数学模型。
六、数据挖掘的选择
我们将本文第三部分中筛选好的内容导入sql server 2005数据库后会直接明了的看出,有些地方的数据值是没有的,在对这些没有值的数据进行处理前,我们需要领会数据的值是如何丢失的和缺失的情势有哪些。我们把数据在一起不存在丢失值的属性叫做完全变量,数据中存在缺失值的变量叫做不完全变量,我们将不同的数据缺失机制大体上可以分为下面三类:
(一)完全随机缺失
数据中数据内容的丢失与不完全变量和完全变量之间没有任何逻辑上的关系。
(二)随机缺失
数据存在的丢失值仅仅依靠不存在丢失值的属性。
(三)非随机、不可忽略缺失
不完全变量中数据存在的空值依靠于不完全变量自身,我们无法忽略这种丢失。
有很多种数据挖掘办法都可以在含有空值数据的前提下对已有数据直接开始数据挖掘。其中比较常用并比较好理解的方法有贝叶斯网络和人工神经网络两种方法。我们通常用贝叶斯网络来展示两个或两个以上属性之间连接概率的图形方法,它给我们提出这个相对比较好理解的展示信息的原因与结果,以此寻找数据中被隐藏的联系。在贝叶斯网络中,用数据节点表现变量,有向边表现两个变量之间的依存关系。如果在任何一个对象中的缺失值数量很大时(比如一个变量有10个数据,但缺失9个,无论我们挖掘多少次、如何挖掘那些空缺值一定是没有缺失的那个值),所以在这种情况下不建议使用贝叶斯网络。人工神经网络这种方法通常也能十分有效的遏制空缺值,但这种方法在数据的处理方面的研究与实施有待提升。
大部分数据系统都是人们对数值开始处理这一首要阶段采用多种不同的处理方法对空值进行有效的处理。一个问题可能用一个方式或多种处理丢失值的方式。不论用何种方法对数据进行处理,我们都没法避免我们自己的自身成分对原系统产生影响,如果数据集中存在的空值过多,我们将这些存在空值过多的数据补充全面是十分艰难的。从理论上来说,贝叶斯网络相对人工神经网络考虑较多,但是只有被挖掘的数据集较小或满足某些特定条件时完全贝叶斯分析才是可行的。而现阶段,人们不经常在挖掘操作中使用人工神经网络这种方法,而且人工神经网络预测出的结果与现实相比误差较大。综上所述,结合我的数据,我们会发现贝叶斯网络的种种条件都适合我的数据,所以我选择用贝叶斯网络对已有数据进行数据挖掘。
贝叶斯网络算法是一种可以快速生成并且适合预测性建模的分类算法,它通过两个或两个以上的独立属性去推测另一个已有属性中空缺数据的大概率的取值。通过图1我们会发现,不管其他变量如何变化,电视台、广播电台、公共图书馆、艺术表演团体这几个变量几乎不变,所以我们可以通过贝叶斯网络建立文化馆、博物馆和有线电视用户的数据库,从而建立这几个数据列之间的联系,最后挖掘出相对有用的信息。
七、数据挖掘过程
(一)创建数据库
打开并运行sql server 2005,建立名为地区文化产业的数据库,并建立地区文化产业的数据文件及地区文化产业的日志文件。
在地区文化产业数据库中建立表名为“地区文化产业”的数据表,设置地区文化产业表的列名以及数据类型等,我们已经确定用贝叶斯忘了进行挖掘,贝叶斯网络能有效处理空值,我们设置文化馆、博物馆以及有线电视用户的值都可以取空,值得注意的是,一定要设置mark列为主键,否则下面的数据挖掘不能成功的运行。
将筛选完的数据录入到地区文化产业数据库中的地区文化产业数据表表中(如图1所示)
(二)进行数据挖掘
打开SQL Server Business Intelligence Development Studio工具,新建一个Analysis Service项目,命名为地区文化产业(如图2所示)
建立SQL Server Business Intelligence Development Studio工具与SQL sever 2005通过Windows用户进行连接,让SQL Server Business Intelligence Development Studio获取地区文化产业数据库中的数据。
选择地区文化产业表(如图3所示)建立数据源视图。
在SQL Server Business Intelligence Development Studio平台中建立数据挖掘向导,通过贝叶斯网络对数据进行数据挖掘
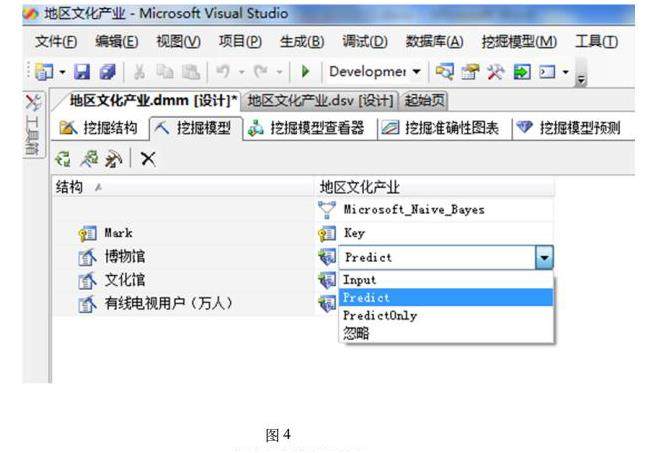
生成挖掘模型(如图4所示)
值得注意的是,除了主键以外,博物馆、文化馆和有线电视用户三个选项都有Predict、Input、PredictOnly和忽略四个选项,Input和忽略比较好理解,比较难理解的是Predict与PredictOnly,Predict可以理解为这一列既可以作为输入列又可作为输出列,而PredictOnly只能作为输出列。通过折线图我们可以观察到有线电视用户中有几个值是空缺的,我们可以输入博物馆和文化馆的信息,来预测有线电视中的空缺值。通过部署,我们可以得到链状挖掘模型,如果生成的挖掘模型为环状,各个列之间的数据不会相互独立,后续的工作将不能向下进行。
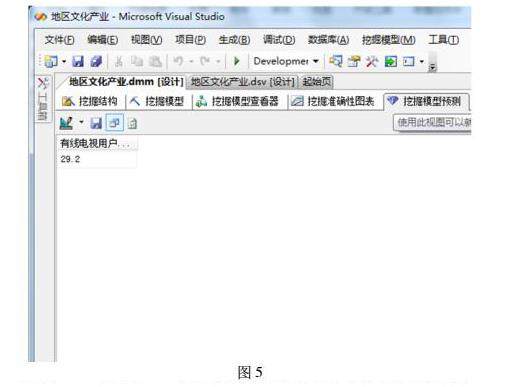
以2005年为列,点击单独查询输入、选择事例表,将2005年其余两个可知项对应数据输入,有线电视用户缺失,点击查询后,我们会得到(如图5所示)结果。
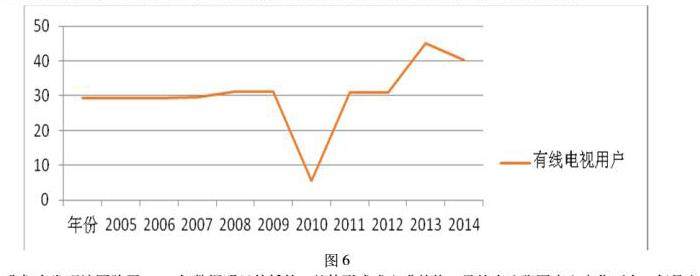
根据上述方法,可以将2007年还有2010年的有线电视用户全部补充全,补全的结果为2007年是29.2万人、2010年是31.2万人,根据结果,我们可以做出(如图6所示)有线电视用户数量的折线图,
我们会发现该图除了2011年数据明显偏低外,整体形式成上升趋势,虽然在这张图表上变化不大,但是它的单位是万人,实际增长的数额十分巨大。
八、贝叶斯网络的缺点
十七世纪的欧洲人有这样一个观点,他们都相信天鹅是白色的,因为当时的他们看不到其他颜色的天鹅,因为当时所能见到的天鹅的确都是白色的,根据大多数人的经验主义,天鹅是白色这一理论便成为唯一真理。那么,在这一前提下见到黑色天鹅的概率是多少?拿到今天也无法计算,也根本没有人想过要计算这种不切实际的问题。直到17世纪90年代,有人在澳大利亚地区偶然的看见了一只黑色天鹅,尽管黑色天鹅只有一只,但它让人们意识到以前被认为是真理并不完全正确,明白天鹅有可能是黑颜色。
这用事实验证了经验总结的片面性,虽然你观察了海量的数据并证明了天鹅是白色的,但是只要有一只天鹅是黑色的、或者有一只天鹅是其他颜色,前面通过海量数据得出的结论也就被推翻了。
我们所做的贝叶斯网络也存在这种问题,通过上面得出的结论可以看出,2005年的有线电视人数为29.2万人,他与2006年的有线电视人数一样,虽然2005年没有测量,但人数一定不是29.2万人,贝叶斯网络只能推测出那一年的人数为29.2万人的概率相对较大,所以结果为29.2万人。
贝叶斯网络算法是一种可以快速生成并且适合预测性建模的分类算法,它通过两个或两个以上的独立属性去推测另一个已有属性中空缺数据的大概率的取值。尽管黑天鹅这一事件存在的可能性非常非常低,但是一旦它出现就会影响整个贝叶斯网络模型,最后产生不正确的结论。
九、结论
目前,呼和浩特市地区文化势头良好,采用计算机科学与技术,对呼和浩特市地区文化产业发展有非常重要的深远意义,而且通过数据挖掘系统的运用,可以进一步推动呼和浩特市地区文化产业发展,数据挖掘这一平台给其提供了一个非常好的资源整合方式,也是知识服务工程的重要探索和尝试。本文通过对浩特市地区文化产业发展现状分析、数据收集与整理、数据缺失原因、数据挖掘方法、数据挖掘选择、贝叶斯网络操作流程图、数据挖掘过程和贝叶斯网络的缺点的论述,根据统计资料运用数据挖掘系统分析得出呼和浩特地区有线电视用户增长十分迅速,可以看出广播影视业的发展前景十分宽广,图书出版业折线趋于平稳,发展前景不大,人们应该将更多的经历投向于广播影视业,图书出版业维持现状就好。显而易见,数据挖掘系统在地区文化产业发展领域中意义重大。
参考文献:
1、呼和浩特市2005-2015年国民经济和社会发展统计公报。
2、叶朗:《中国文化产业年度发展报告(2010)》,北京大学出版社2010年版。
3、于建伟:《中国文化产业开始发力》,期刊名称《财经届》。
4、乔珠峰 田凤占 黄厚宽 陈景年:《缺失数据处理方法的比较研究》,学术期刊《计算机研究与发展》2006年Z1期。
5、纳西姆·尼古拉斯·塔勒布:《黑天鹅》,中信出版社。

 京公网安备 11011302003690号
京公网安备 11011302003690号


