



- 收藏
- 加入书签

纵向联邦学习日照银行客户画像精准服务研究
摘要:为解决区域性银行客户数据分散、共享困难导致的客户画像精准度低问题,提出一种基于纵向联邦学习的精准服务方法。以日照银行为例,应用联邦逻辑回归和安全提升树(SecureBoost)模型,结合同态加密和差分隐私技术,实现数据在不出本地的情况下跨机构融合。实验表明,该模型准确率接近集中式模型,优于单一数据源模型,证明了其在提升客户画像精准度和隐私保护方面的有效性。研究显示,纵向联邦学习能在遵守数据合规和隐私保护的前提下,实现银行客户画像的精准服务。
关键词:纵向联邦学习;客户画像;隐私保护;同态加密;差分隐私;精准服务
一、引言
数字经济和金融市场竞争促使银行客户服务向精准化和个性化发展。客户画像的准确性和丰富性直接影响银行客户满意度和盈利。对区域性银 精 准客 画像有助于服务地方经济和特定客户群。然而,银行客户数据分散在不同部门和外部合作伙伴 成 孤岛,阻碍了精准客户画像的构建。同时,隐私保护法规趋严,限制了数据跨机构流动,影响集中式客户画像的构建。
联邦学习(Federated Learning)是一种新兴的分布式机器学习技术,由Google 首次提出,原本应用于移动设备端,近期在金融行业展现出了巨大潜力。联邦学习的基本思想是数据不出本地环境,只通过模型参数或梯度进行加密通信,从而保障数据隐私并实现多方协作。特别是纵向联邦学习(Vertical Federated Learning),适用于多个机构拥有相同客户但拥有不同特征的场景,能够高效安全地实现跨机构数据融合。
本研究针对日照银行客户画像服务,提出了一种银行业纵向联邦学习方法。该方法结合联邦逻辑回归和安全决策树(SecureBoost)模型,整合客户特征数据。证明了该方法在提高客户画像准确性和保护隐私方面的优势。研究的主要贡献是:为日照银行定制纵向联邦学习方案,应用同态加密和差分隐私技术提升安全性,并通过实验验证了其有效性和实用性。
二、相关研究综述
(一)客户画像与精准服务研究现状
客户画像,即用户特征分析,是通过大数据技术从客户数据中提取需求、偏好和行为习惯等信息的分析方法。该技术起源于互联网和电商领域,现在银行业也广泛使用,以实现精准营销、风险控制、客户关系和挽留等业务。
客户画像构建传统上依赖集中式数据仓库和数据挖掘技术,如决策树、逻辑回归等。但这些方法常因数据维度有限而难以精准描绘客户。银行虽有金融数据,却缺少电商和社交数据;第三方平台则缺少银行的风险评估和资产信息,导致数据分散和“数据孤岛”问题,成为银行客户画像研究的主要挑战。
(二)联邦学习研究进展与应用
联邦学习(Federated Learning)由 Google 公司于 2016 年提出,其最初目的是解决终端设备之间数据隐私保护条件下的模型协同训练问题(Bonawitz et al, 2019)[1]。根据数据在参与方分布的不同,联邦学习可分为横向联邦学习和纵向联邦学习两种模式。横向联邦学习适用于各方拥有相同的特征但样本不同的情形,而纵向联邦学习则适用于各方拥有相同的样本但特征维度不同的情形。
联邦学习作为金融行业数据共享的解决方案,受到广泛关注。金融机构如中国工商银行、微众银行等,通过联邦学习技术在信用评估、精准营销和反欺诈建模等方面取得成果。同时,学术界开发了针对金融业务的联邦学习模型,如安全提升树、联邦逻辑回归等,为银行业应用提供理论和技术支持。
纵向联邦学习模式适合银行客户画像服务,无需共享原始数据,通过加密技术或安全多方计算传输中间结果,防止隐私泄露。差分隐私技术也用于增强数据保护。研究表明,此模式能保护隐私,高效融合跨机构数据,提升模型精度和泛化能力(罗玮 等,2024)[2]。
(三)隐私保护技术研究进展
隐私保护技术是联邦学习落地应用的重要保障,主要包括同态加密、安全多方计算和差分隐私三大类技术。
1.同态加密(Homomorphic Encryption)
允许在不解密密文的情况下直接对密文数据进行数学运算,保证了联邦学习过程中梯度信息或中间计算结果传输的安全性(李亚红 等,2025)[3]。尤其是在纵向联邦学习中,被广泛用于保护模型训练过程中的敏感信息,防止其他参与方反推原始数据。
2.安全多方计算(Secure Multi-party Computation,SMPC)
允许多个参与方在不泄露各自数据的情况下协同完成复杂的计算任务,各参与方仅获取最终计算结果,而无法获取其他方的原始数据。在联邦学习中广泛应用于安全聚合阶段,有效避免了数据共享过程中的隐私泄漏风险,并提升了模型整体安全性和可信性。
3.差分隐私(Differential Privacy)
通过在数据或计算结果中注入适当的随机噪声,使单一用户的数据难以被逆向推导,从而有效保护用户隐私信息。近年来,差分隐私被广泛融入联邦学习的模型训练过程中,用于抵御模型反推攻击和数据窃取攻击,提升联邦学习模型的隐私保护能力。
同态加密、安全多方计算和差分隐私等技术的成熟与应用,与联邦学习的融合,构建了完善的隐私保护框架,为银行客户画像和精准服务领域的联邦学习应用提供了坚实的技术支持。
三、方法设计
(一)纵向联邦学习总体框架设计
本研究提出的纵向联邦学习框架,旨在满足日照银行与电商平台在客户画像服务上的数据融合需求,同时保护隐私安全。框架设计为三层结构。
1. 日照银行和电商平台各自维护本地核心数据和外部特征数据,不共享原始信
2. 设立联邦协调服务器,负责安全聚合与分发模型梯度或中间参数,通过加密数据交换确保服务器不接触明文数据。
3. 结合差分隐私、同态加密、安全多方计算等技术,确保数据在协作过程中不(二)纵向联邦学习模型构建与训练过程
本研究开发了银行客户画像模型,采用联邦学习算法。模型通过日照银行初始化参数,各参与方计算本地梯度并加密传输至主动方,主动方合并梯度更新全局模型参数,直至收敛。在安全提升树中,模型适用于金融复杂非线性分类问题,主动方确定决策树节点最优划分,被动方提供加密特征信息,主动方确定最佳分裂特征与阈值,迭代生成完整决策树。
(三)数据协同方式设计
纵向联邦学习中,数据协同包括用户对齐和特征融合。用户对齐使用隐私集合求交协议(PSI),通过哈希协议计算用户ID 交集,各方交换加密ID 匹配共有用户,确保信息不泄露。特征融合要求本地特征工程和处理,模型训练时仅传输加密的中间结果,如梯度或特征指标,实现协同与隐私保护。
(四)隐私保护技术实现细节
为保护联邦学习中的数据隐私,本研究采用同态加密和差分隐私技术。使用 Paillier 算法实现密文计算,保持数据加密状态下的求和运算,确保主动方更新模型时无法获取被动方的明文数据。在差分隐私方面,通过在模型参数或梯度计算中加入随机噪声,如拉普拉斯或高斯分布的扰动,并根据隐私预算参数 ϵ 调整噪声大小,有效防止敏感信息泄露,增强训练隐私安全。
(五)系统实现与部署方案
本研究基于开源FATE 框架,为日照银行业务实现系统。搭建阶段,部署FATE 并联通主动方与被动方节点,各节点安装服务并建立通信通道,服务器仅聚合模型梯度。设计数据接口与安全通信,统一接口转换数据格式,部署TLS 协议保护数据传输。优化层面,采用并行计算与异步通信提升效率,定期审计日志确保安全合规。
四、实验分析
(一)实验数据设计与模拟方案
为确保研究的合规性和数据敏感性,本研究通过仿真模拟日照银行实际业务,构建了包含 10000 名客户的数据集。这些客户数据包括银行端的账户余额、贷款情况、信用等级等信息,以及第三方电商平台的网购行为、消费频率和信用评分。数据特征涵盖人口统计、银行业务、风险指标、消费行为、信用类指标和社交活跃度。预测目标包括客户流失情况、购买新理财产品的情况以及信用风险分类。
(二)实验实施过程与参数设定
本研究设计了三种模型:单方模型仅用单一数据源建模;传统集中式模型在数据共享的理想状态下训练;纵向联邦学习模型结合联邦逻辑回归、SecureBoost、同态加密和差分隐私。模型训练参数包括7:3 的训练测试集划分,1024 位的Paillier 算法密钥,隐私预算参数在0.5 到2.0 之间,100 轮训练,梯度下降法和决策树优化算法,以及准确率、召回率、精确率和AUC 作为性能评价指标。
(三)实验结果分析与对比评价
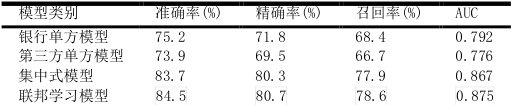
针对客户流失预测模型的实验结果,数据显示银行单方模型的准确率为75.2%、精确率为71.8%、召回率为68.4%且 AUC 为 0.792,而第三方单方模型分别为 73.9%、69.5%、66.7%和 0.776;集中式模型的各项指标分别提升至 84.5%、80.7%、78.6%与 0.875;联邦学习模型的准确率、精确率、召回率及 AUC 分别为 83.7%、80.3%、77.9%和0.867。分析发现,联邦学习模型显著优于单方模型,性能表现接近集中式模型,且模型与集中式方案的差距小于1%,验证了纵向联邦学习在隐私保护条件下融合数据的高效性。
表1 客户流失预测模型实验结果
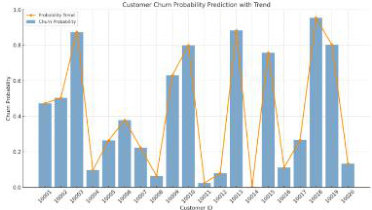
以前20 位客户为例,画出客户流失概率预测的趋势图
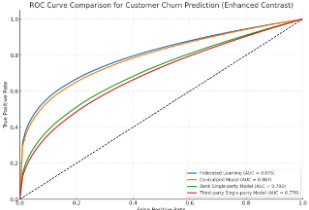
图3 客户流失率趋势预测分析图
图2 联邦学习模型与其他模型之间的性能差异
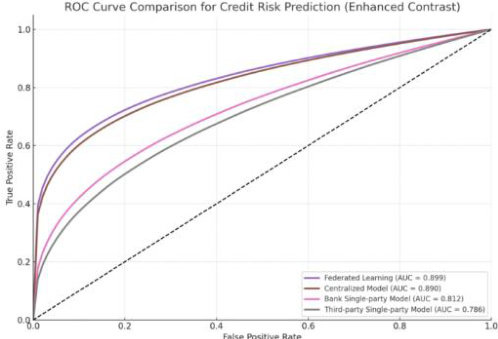
关于信用风险预测模型(采用 SecureBoost)的实验结果,银行单方模型表现为 78.3%准确率、74.2%精确率、70.9%召回率和 0.812 UC;第三方单方模型则为 74.6%、70.1%、68.3%和 0.786;集中式模型分别为 86.9%、83.8%、81.4%及 0.899;联邦学习模型取得 86.0%、82.9%、80.7%和 0.890。由此可见,联邦 SecureBoost 模型相比银行单方模型在信用风险分类准确性上提升了 7.7%以上,且在加入差分隐私机制后模型仍保持高性能,证明了隐私保护与模型性能之间实现了有效平衡。
表2 信用风险预测模型实验结果
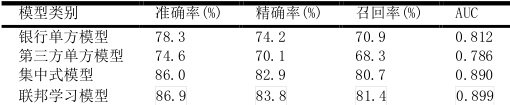
图4 信用风险预测的ROC 曲线图
二、五、结果讨论
(一)联邦学习模型性能提升的原因分析
本研究应用的纵向联邦学习模型在客户流失和信用风险预测方面,表现优于独立建模的单一数据源模型。性能提升主要得益于数据互补性增强特征信息量、特征交叉挖掘潜在价值,以及更接近客户真实行为的数据融合,提高了泛化能力和降低了预测误差。
(二)与传统集中式建模方式的对比分析
本研究比较了联邦学习模型与传统集中式模型。结果显示,在隐私保护限制下,联邦学习模型性能与理想数据集建模相近。例如,在客户流失预测中,集中式模型AUC 为0.875,联邦学习模型为0.867,差异很小,对实际业务影响可忽略。性能差异可能由差分隐私噪声和加密浮点误差引起,但这不影响联邦学习在数据隐私安全下的跨机构数据融合应用价值。
(三)隐私保护与安全性分析
研究结合了同态加密和差分隐私技术,并通过实验确认了它们的有效性。实验采用Paillier 算法进行同态加密,确保训练过程中数据安全,无明文信息泄露。差分隐私实验中,隐私预算参数设置在0.5 到2.0,发现模型精度受影响小,同时提升了对恶意攻击和数据反推的防御能力。这说明差分隐私在保护隐私和保持模型精度间取得了平衡。整体上,联邦学习平台在实验中未发生隐私泄露或安全问题,显示了其高安全性和稳定性,满足法律和监管标准。
六、结论
本文介绍了一种纵向联邦学习方案,旨在满足日照银行客户画像服务需求,通过数据不出域的方式融合多方信息,提高画像的准确度。实验结果表明,该方案在保护隐私的同时,模型效果与传统集中式建模相当,实现了研究目标。文章将联邦学习创新地应用于银行业务,设计出既保护隐私又实用的模型训练框架,为金融数据共享问题提供了解决方案。期望监管机构能够为联邦学习应用制定规范和支持政策,推动金融行业建立数据合作标准协议和法律框架,为技术应用创造良好环境。
参考文献
[1]Bonawitz , ichner , rieskamp , t l. owards ederated earning t cale: System esign[J]. oceedings of machine learning and systems, 2019, 1: 374-388.
[2]罗玮,刘金全,张铮. 融合秘密分享技术的双重纵向联邦学习框架 [J]. 计算机应用, 2024, 44 (06):1872-1879.
[3]李亚红,李一婧,杨小东,等. 基于同态加密和群签名的可验证联邦学习方案 [J]. 电子与信息学报,2025, 47 (03): 758-768.
关联项目名称:2025 年度学生校级科研项目《基于联邦学习的金融管理客户画像构建与精准服务机制研究》(山外校字〔2025〕20 号)
项目编号:XS202522
题目:纵向联邦学习日照银行客户画像精准服务研究
作者简介:
高琦(2004. 5-) ,女,汉族,籍贯:学校名称:;本科在读,专业:金融管理,研究方向:金融管理。

 京公网安备 11011302003690号
京公网安备 11011302003690号


