



- 收藏
- 加入书签

基于分类SNM算法的数据库审计方案及系统
摘要:随着数据库安全审计需求的日益增长,传统审计方法在处理大量相似或重复的审计结果时效率低下,且缺乏对数据安全生命周期的全面覆盖。本文提出一种基于分类 SNM(Sorted-Neighborhood Method)算法的数据库审计方案及系统,通过引入数据安全审计策略规则,结合改进的 SNM 算法,实现对审计结果的高效去重与分类处理。本方案首先对审计结果按风险类型和数据库类型进行分类分组,随后采用动态可变窗口与跳跃窗口机制优化 SNM 算法,显著提升了去重效率与准确性。实验表明,该系统在降低人工研判负担、提升审计处理效率方面具有显著优势,具备较高的实用价值与推广前景。
关键词:数据库审计;SNM 算法;数据安全;去重机制;动态窗口;跳跃窗口
一、引言
数据库作为企业核心数据的存储与管理平台,其安全性直接关系到企业信息安全与合规性。传统数据库审计系统主要通过旁路部署、Agent 代理或日志解析等方式采集操作日志,并基于预定义规则进行风险检测。然而,现有审计系统普遍存在两个突出问题:一是审计结果中大量重复或高度相似的告警记录导致研判效率低下;二是审计策略多集中于网络与操作层面,缺乏对数据安全生命周期的全面覆盖,尤其是对敏感数据的访问与操作行为审计不足。
为解决上述问题,本文提出一种基于分类 SNM 算法的数据库审计方案。该方案在传统审计基础上,引入数据分级分类机制,构建针对敏感数据访问的审计策略,并结合改进的SNM 算法对审计结果进行高效去重。本文的主要贡献包括:
1. 提出一种基于风险类型与数据库类型的审计结果分类方法,为后续去重处理提供结构基
2. 设计一种改进的 SNM 算法,通过动态可变窗口与跳跃窗口机制提升去重效率;
3. 构建一套完整的数据库审计系统原型,实现从数据采集、预处理、审计分析到结果去重的全流程自动化处理
二、相关工作
2.1 数据库审计技术
目前数据库审计主要采用三种数据采集方式:旁路部署、Agent 代理和日志解析方式[1]。这三种技术路径在实施复杂度、审计粒度、性能开销以及对数据库本身的影响方面各有侧重,共同构成了传统数据库审计的技术基础。然而,它们均存在一个共性的后续处理难题:审计系统输出的结果中通常包含大量在内容上高度相似或完全重复的风险告警记录,这给安全分析人员的人工研判带来了巨大负担,严重影响了审计效率[2]。
2.1.1 旁路部署方式获取 SQL 操作数据
旁路部署(Out-of-band Deployment)是一种非侵入式的审计数据采集方式。在该模式下,审计系统并不直接串接在数据库业务链路中,而是通过交换机等网络设备的端口镜像(Port Mirroring)或网络分光(Tap)技术,将流经数据库服务器的网络流量副本镜像到审计设备的监听端口上[3]。随后,审计系统对捕获到的网络数据包进行重组,深度解析数据库通信协议,从中提取出完整的 SQL 操作语句及其上下文信息(如源IP、时间戳等)。这种方式对数据库服务器的性能几乎无影响,部署灵活,尤其适用于网络流量规模较大的核心生产环境。但其有效性高度依赖于网络拓扑和镜像配置的完整性,且对于加密流量或主机本地连接的操作可能存在盲区。
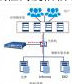
图 1
2.1.2 Agent 方式获取 SQL 操作数据
Agent 代理方式通过在数据库所在的主机操作系统上安装一个轻量级的代理程序来实现数据采集[4]。该 Agent 程序通常利用内核模块或用户态抓包库直接捕获进出数据库进程的网络流量,或通过钩子(Hook)技术拦截数据库引擎的系统调用。采集到的原始数据经过初步格式化后,被发送至中心化的数据库审计系统(DAS)进行集中分析与存储。Agent 方式能够捕获包括本地连接在内的所有数据库访问流量,审计粒度更细,且适用于云环境下的Linux、Windows 等多种虚拟主机。单台审计设备可同时管理并接收来自多个Agent 的数据,实现分布式审计。不过,部署和维护Agent 带来了额外的管理开销,且可能引发对主机稳定性和安全性的顾虑。
2.2.3 日志文件审计获取 SQL 操作数据
日志解析方式通过直接读取和分析数据库系统自身生成的各类日志文件(如事务日志、错误日志、慢查询日志或开启的通用日志)来获取 SQL 操作数据[5]。审计系统通常配置日志采集器(如Filebeat、Flume 等),定时或实时地将日志文件内容传输至审计中心进行解析。这种方式完全依赖于数据库自身的日志记录能力,无需额外的网络流量捕获或系统拦截,因此兼容性最好,对数据库运行无干扰。然而,其审计内容的详实程度受限于数据库的日志级别和格式,可能无法获取全部所需的审计细节(如客户端 IP),并且日志解析的实时性通常低于前两种网络流量分析方式。
图 2
2.2 重复记录检测算法
重复记录检测,又称记录去重或实体解析,是数据清洗与数据质量管理领域的核心问题之一,旨在识别并合并指向同一真实世界实体的不同记录[6]。在数据库审计场景中,海量且内容高度相似的 SQL 操作日志导致告警风暴,使得高效、准确的重复记录检测技术成为提升审计结果可读性与研判效率的关键。
在众多去重算法中,排序邻居方法(Sorted-Neighborhood Method, SNM)因其简洁高效而被广泛应用[7]。传统 SNM 算法在应用于数据库审计日志这类特定数据时,暴露出若干局限性[8]:
1. 排序关键词敏感:算法的效果极度依赖于排序关键词的选取。若关键词不能有效聚集相似记录,大量本应匹配的重复记录可能因分散在不同窗口而漏检。
2. 固定窗口大小僵化:预设的固定窗口大小\$难以适应数据分布的不均匀性。过小会导致跨窗口的重复记录无法匹配;\$w\$过大则会造成大量不必要的比较,降低算法效率。
3. 比较冗余:在固定窗口内,即使记录间明显不相似,仍需进行两两比较,产生计算
为克服这些缺陷,近年来学术界提出了多种改进方案。例如,有研究引入机器学习方法动态学习最优排序键或相似度阈值[9];另有研究采用图匹配模型,将记录视为节点,相似度超过阈值的记录对构成边,通过寻找图中的连通分量来识别重复记录集合[10]。此外,基于深度学习的语义相似度计算方法也被用于处理更复杂的文本型记录[11]。
尽管这些改进方法在通用数据集上表现良好,但在数据库审计这一特定场景下面临挑战。审计日志中的 SQL 语句结构复杂、变量多、时间戳等瞬时信息干扰大,导致语义相似度计算精度下降。同时, 计系统通常要 的处理实时性,复杂的机器学习或图算法可能难以满足性能要求[12]。因此,针对数据库审计日志高相似、高实时的特点,设计一种轻量、高效且精准的专用去重算法具有重要的现实意义,这也是本文对SNM 算法进行针对性改进的动机。
2.3 数据安全审计策略
随着《数据安全法》、《个人信息保护法》等相关法规的实施,数据安全已被提升至国家战略高度,企业合规建设面临全新要求[13]。现有审计系统多关注操作行为合规性,缺乏对数据分级分类、敏感数据访问控制等方面的深度审计。本文结合数据安全生命周期理论,提出针对敏感数据导出、备份缺失、关联访问等场景的审计策略,弥补了传统审计在数据安全层面的不足。
三、系统设计
3.1 系统架构
本系统分为四个核心模块:数据采集模块、预处理模块、审计分析模块和去重处理模块。系统架构如图 1 所示:
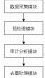
图 3
3.2 数据采集与预处理
系统支持三种数据采集方式:旁路流量镜像、Agent 代理采集和数据库日志解析。采集到的原始日志经过预处理模块进行标准化处理,提取审计主体、审计客体和审计动作三类信息,形成结构化审计记录。
3.3 审计分析模型
系统使用的审计分析模型为4W1H(WHEN-时间、WHERE-地点、WHO-人物、WHAT-对象、HOW-动作)分析模型,该模型把单条待审计信息作为一个整体,对事件的各项属性(WHEN-时间、WHERE-地点、WHO-人物、WHAT-对象、HOW-动作)进行分析,并提炼、归纳出异常和违规行为的特征,为采取相应安全措施提供依据。
基于 4W1H 审计分析模型和数据分级,可以向审计相关人员提供语义分析、统计分析、关联分析三类分析方法,重点关注敏感库表的访问、操作。通过对数据库审计策略的制定,建立数据库操作的风险特征与审计行为的映射规则, 具体流程如下所示:
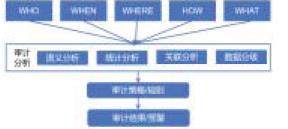
图 4
在数据安全全生命周期中,数据使用加工、存储过程中,需对访问和操作行为审计。新增数据安全审计策略规则如下结合数据分级分类结果,构建三类审计策略:
1. 生产重要核心数据批量导出策略:在数据安全生命周期中,存在大量数据导出的场景及需求,而数据导出过程中数据量一般较大,其数据泄露风险较大;生产数据批量导出策略是通过识别一系列数据库导出命令,发现生产数据批量导出,例如:MySQL 数据库“SELECT … INTO OUTFILE”语句导出数据。
2. 重要核心数据未备份策略:在生产环境中造成重要数据丢失的原因,例如:误操作输入错误命令导致数据丢失;物理磨损,导致磁盘出现坏道,造成数据丢失;数据库被恶意加密,导致系统不可用。数据库备份可以解决重要数据库丢失问题,同时也符合国家法律法规相关要求。数据未备份策略是通过识别一系列数据库备份命令,若未命中所有数据库备份命令,则判定数据库未备份数据。
3. 重要核心关联分析策略:基于数据安全分级分类结果,针对高安全级别数据库进行关联分析。关联分析主要用于在海量审计信息中找出异构异源事件信息之间的关系,对于存在关联关系信息的上下文制定合理的审计策略,通过组合判断多个异构事件判断操作行为性质,发掘隐藏的相关性,发现可能存在的违规行为。关联分析关注审计客体和审计动作,以 WHAT 和 HOW 为主要关联对象。
3.4 基于分类 SNM 的去重算法
首先按命中风险类型和数据库类型对审计结果进行分类,每个类别作为一个独立的数据集Ri,所有类别集合为{R1,R2,...Ri,...Rk},其中 k为分组数量。每个分组的数据库审计结果以数据库操作语句/命令作为待去重记录,针对每一个记录做进行处理。
3.4.2 关键词提取与处理
对每条审计记录中的SQL 语句进行清洗,去除关键字(如 SELECT、FROM、WHERE 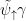 ,去除时间标识字符串,提取剩余字符串作为匹配关键词具体如下所示:
,去除时间标识字符串,提取剩余字符串作为匹配关键词具体如下所示:
1. 去除所有 SQL 语句关键字,例如:delete from data_schema where id>100,去除之后其关键字为:“data_schema20240710”、“id”、“>”、“100”2. 去除所有带有时间标识字符串,例如:delete from data_schema20250112 where id>100,去除之后为“data_schema”、“id”、“>”、“100”。
3.4.3 相似度计算
相似度可以利用编辑距离算法计算得到。编辑距离算法计算公式为: S=1-cd(x,y)/Lmax ,其中Lmax为源字符串 S 的长度与目标字符串R 的长度的最大值,ed x,y 为编辑距离[14],其值为:
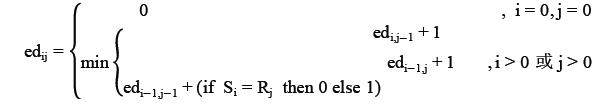
3.4.4 去重流程
传统 SNM 算法采用固定大小的滑动窗口,本系统使用了动态窗口调整和跳跃窗口机制[15]。窗口大小根据相似记录数量动态调整,避免过大或过小导致的匹配问题。跳跃窗口机制:当一个窗口内的记录清洗完成后,窗口直接跳至下一条不相似记录,减少重复比较。算法流程如下:
a. 以不同命中风险类型、数据库类型的审计结果进行分类,每一个分类为一组,所有分组为:{R1,R2,...Ri,...Rk},其中k 为分组数量b. 提取每个分组的关键字;c. 从分组Ri 的第一条记录开始,其他记录逐一与其比较;d. 定义了一个动态窗口集合 W,动态增加记录,用于存放每个窗口内的相似记录;
e. 窗口外的记录与窗口内的记录一一比较,如果该记录至少与窗口内的一条记录相似,那么将该记录加入集合 W 中,并重新设相似标签 flag=1;
f. 如果该记录与窗口内的所有记录都不相似,那么窗口大小已固定,退出本次循环;
g. 窗口跳转到下一条与窗口内的所有记录都不相似的记录上,令其为新窗口的第一条记录,与下面的记录进行匹配;h. 直到本次分组记录匹配完毕,跳转至步骤c;
i. 所有分组匹配完毕,输出窗口 W 中的全部相似重复记录,并去重
四、实验与评估
实验采用真实企业数据库审计日志,包含约 50 万条审计记录,涉及 oracle、hive、gaussdb、postgresql、mysql、carbon、gbase、clickhouse、dblog 等数据库类型。硬件环境为 Intel Xeon 8 核处理器、32GB 内存,软件环境为 CentOS 7.6。
4.2 评估指标
采用以下指标评估系统性能:去重率:重复记录去除比例;
处理时间:从审计到去重的总耗时;
准确率:去重后保留的记录中真实有效记录的比例;
召回率:被正确去除的重复记录占所有重复记录的比例。
4.3 实验结果
实验对比了传统SNM 算法、基于分类的 SNM 算法以及本方案提出的改进 SNM 算法。结果如表 1 所示:

实验表明,本方案在去重率、处理时间和准确率等方面均优于对比算法,尤其在处理大规模相似审计记录时表现突出。
4.4 讨论
本方案通过分类预处理降低了数据复杂度,结合动态窗口与跳跃窗口机制显著提升了算法效率。在实际应用中,该系统可有效降低人工研判负担,提升数据库安全运营效率。
五、结论
本文提出了一种基于分类 SNM 算法的数据库审计方案及系统,通过引入数据安全审计策略与改进的去重机制,实现了对数据库审计结果的高效处理。实验证明,该系统在去重效率、准确率和处理速度方面均优于传统方法,具备良好的实用性与可扩展性。未来工作将进一步探索基于深度学习的相似度计算方法,以提升复杂 SQL 语句的匹配精度。
参考文献
[1]M.S.Hossain and S.A.Rahman,“Database Security and Auditing: A Comparative Study,”International Journal of Computer Applications, vol. 143,no.10,pp.1-6,Jun.2016.
[2] K.J.Julisch,“Clustering intrusion detection alarms to support root cause analysis,” ACM Transactions on Information and System Securit (TISSEC), vol. 6, no. 4, pp. 443–471, Nov. 2003.
[3] G. V. Nehme and H. C. Lim, “Data stream auditing: techniques and applications,” in Proceedings of the 2009 ACM SIGMOD International Conference on Management of data, Providence, Rhode Island, USA, 2009, pp. 1127–1130.
[4] R. B. Basnet, M. H. Sung, and A. H. Sung, “A survey of intrusion detection systems in cloud computing,” Journal of Information Secur vol. 5, no. 3, pp. 41-56, Jul. 2014.
[5] K. P. Murphy, “Log Analysis: The Encyclopedia of Database Technologies and Applications,” Springer, pp. 354-358, 2009.
[6] A. K. Elmagarmid, P. G. Ipeirotis, and V. S. Verykios, “Duplicate record detection: A survey,” IEEE Transactions on knowle engineering, vol. 19, no. 1, pp. 1–16, Jan. 2007.
[7] M. A. Hernández and S. J. Stolfo, “The merge/purge problem for large databases,” in Proceedings of the 1995 ACM SIGMOD internationa conference on Management of data, San Jose, California, USA, 1995, pp. 127–138.
[8] C. Xiao, W. Wang, and X. Lin, “Ed-join: an efficient algorithm for similarity joins with edit distance constraints,” Proceedings of the VLDB Endowment, vol. 1, no. 1, pp. 933–944, Aug. 2008.
[9] S. E. Whang, D. Menestrina, G. Koutrika, M. Theobald, and H. Garcia-Molina, “Entity resolution with iterative blocking,” in Proceedings of the 2009 ACM SIGMOD International Conference on Management of data, Providence, Rhode Island, USA, 2009, pp. 219–232.
[10] O. Lehmberg and C. Bizer, “Stitching web tables for improving matching quality,” Proceedings of the VLDB Endowment, vol. 10, no. 11, pp. 1502–1513, Aug. 2017.
[11] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
[12] A. Monge and C. Elkan, “An efficient domain-independent algorithm for detecting approximately duplicate database records,” in Proceedings of the SIGMOD workshop on data mining and knowledge discovery, Tucson, Arizona, USA, 1997, pp. 23–29.
[13] 全国人民代表大会常务委员会,《中华人民共和国数据安全法》,2021 年9 月 1 日起施行。
[14] 刘群,孙健,吴华.一种基于编辑距离的中文文本相似度计算改进方法[J]. 中文信息学报, 2015, 29(4): 88
[15] 王伟,赵静.基于 SNM 改进算法的重复数据检测方法[J].计算机工程与应用, 2019, 55(15): 54-59.

 京公网安备 11011302003690号
京公网安备 11011302003690号


