



- 收藏
- 加入书签

基于NVIDIA Jetson和YOLOv8实现PCB缺陷在线学习检测系统
 打开文本图片集
打开文本图片集

摘要:本文介绍了一种基于NVIDIA Jetson平台和YOLOv8模型的PCB缺陷检测系统。该系统通过图像增强技术和自适应模型参数调整,实现了高效率和高精度的自动化检测。系统采用在线学习机制,不断优化模型精度和鲁棒性。硬件方面,利用TensorRT框架加速模型推理,满足实时性需求。实验结果表明系统达到工业标准,具有良好应用潜力。未来改进方向包括优化数据标注、模型压缩、多模态数据集成和智能化系统管理,以进一步提升系统性能和用户体验。
关键词:PCB缺陷检测;YOLOv8;NVIDIA Jetson;在线学习
1.引言
现代工业生产中,产品质量控制是企业竞争力和消费者体验的关键。传统检测方法如人工检验和规则图像处理技术存在局限性,受人为因素影响大,缺乏灵活性,难以适应多变环境。随着自动化和智能制造技术的发展,基于机器学习的图像识别技术提供了高效率、高精度的自动化检测,减少了人为干扰,且具有可扩展性和灵活性。
实现高效、精准的自动化缺陷检测面临挑战,需综合考虑检测算法设计、数据收集处理、硬件配置等因素。同时,成本效益、操作便捷性和与现有系统的兼容性也是重要考量。开发高效经济的检测解决方案是工业自动化领域的重要课题,结合最新技术进展是关键。
近年来,深度学习技术在缺陷检测方面取得了显著进展。卷积神经网络(CNN[1])显著提升了缺陷识别的准确性和鲁棒性,通过自动提取图像特征,减少了对人工特征工程的依赖。生成对抗网络(GAN[2])用于数据增强,提升了模型在小样本条件下的性能。自编码器(Autoencoder[3])和变分自编码器(VAE[4])在无监督缺陷检测中表现出色,能够自动识别图像中的异常。此外,迁移学习技术加速了模型在新应用场景中的适应速度。总体而言,深度学习显著提高了缺陷检测的自动化程度和精确度。
然而,如果用GPU服务器构建这样的平台,成本高、灵活性低、部署复杂。NVIDIA Jetson[5]平台在嵌入式应用场景中具有显著优势,包括低功耗、便携性、成本效益、实时性、开发工具和边缘计算能力。与GPU服务器相比,Jetson平台的低功耗设计适合节能需求,便携性使其易于在空间受限的环境中部署。成本相对较低,适合预算有限或需要大规模部署的项目。实时性设计确保了快速响应和低延迟计算,适合实时工业应用。提供完整的开发环境和优化工具,如JetPack SDK和TensorRT,便于深度学习模型的部署和优化。此外,Jetson的边缘计算能力允许在数据源附近处理数据,减少延迟和带宽需求。这些特性使得Jetson平台非常适合如PCB缺陷检测等需要高效、实时处理的嵌入式应用。
另外,PCB产品质量检测存在样本少的困难,主要有以下几个方面的原因:
1.复杂性和多样性:PCB产品通常种类繁多,不同产品的缺陷类型和特征差异较大。针对每种产品都需要大量的样本来训练检测模型,且可能需要对每种产品进行定制化的模型设计和训练。
2.成本和资源限制:收集和标注大量的质检数据成本高昂,获取足够多的标记数据可能需要耗费大量时间和资金。
3.时间和效率:新产品上市或生产线变化较快,导致样本获取速度跟不上生产速度,从而难以建立足够完备的样本库。
4.不平衡数据问题:在实际质检数据中,正常产品的数量通常远远大于有缺陷的产品。这类不平衡问题,需要采取数据增强技术或类别平衡策略来有效训练和评估模型。
本文以YOLOv8[6]实现PCB(Printed Circuit Board)缺陷检测训练模型优化问题,和结合NVIDIA Jetson部署两个方面进行展开,为PCB检测提供更加完善的方案。
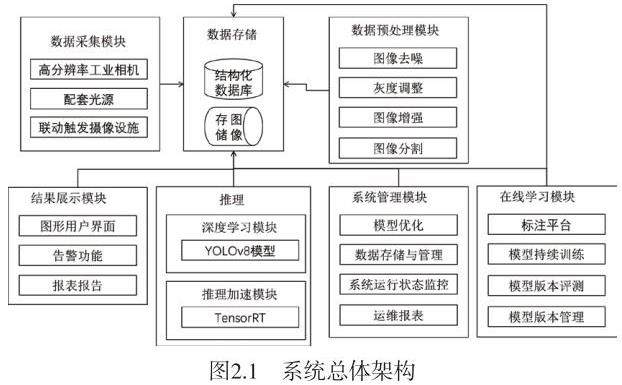
2.系统总体架构
基于深度学习的PCB缺陷检测系统主要包括数据采集模块、数据预处理模块、深度学习模型、在线学习模块、推理加速模块、结果展示模块和系统管理模块。以下将详细介绍各模块的组成和功能。
2.1 数据采集模块
数据采集模块主要负责获取PCB产品的图像数据。常用的设备包括高分辨率工业相机、CCD相机和红外相机等。为了保证数据的多样性和全面性,采集过程中需要考虑不同的角度、光照和背景条件。
2.2 数据预处理模块
数据预处理模块对采集到的图像数据进行处理,以提高深度学习模型的训练和推理效果。常见的预处理方法包括图像去噪、灰度调整、图像增强、图像分割等。这些预处理步骤可以消除图像中的噪声,提高图像的质量。
2.3 深度学习模型
深度学习模型是整个缺陷检测系统的核心,本文采用YOLOv8模型。
2.4 在线学习模块
在线学习[7]允许模型在接收到新数据时即时更新。这种方法适用于数据流不断变化的环境,能够捕捉最新的数据趋势,提高模型适应性和准确性。在线学习通过增量地整合新样本,使得模型能够持续进化,应对动态变化的数据分布。本模块收集人工事后发现的误识样本,进行正确的标注后,再重新回到模型训练环节,进行模型重训,持续适应实际投产,持续提升精度与鲁棒性。
2.5 推理加速模块
推理加速模块利用NVIDIA Jetson平台的计算能力和TensorRT[8]加速库,对深度学习模型进行优化和加速。该模块负责将训练好的模型部署到Jetson平台,并进行实时推理。
2.6 结果展示模块
结果展示模块将缺陷检测的结果以直观的方式展示给用户。常见的展示形式包括图形用户界面(GUI)、报告生成和警报系统等。该模块可以帮助用户快速了解产品的质量状况,并及时采取相应措施。
2.7 系统管理模块
系统管理模块负责系统的配置、监控和维护。包括模型的更新和优化、数据的存储和管理、系统的运行状态监控等。该模块保证系统的稳定运行和高效管理。
3.系统实现
3.1 数据采集与预处理
3.1.1 数据准备与采集
数据采集是构建任何智能检测系统的基础环节。在本研究中,我们部署了一套高分辨率工业成像系统,专门针对PCB产品的高精度视觉检测需求。通过精确控制成像参数,本系统确保了采集到的图像数据能够全面反映PCB产品的微观结构和潜在缺陷,为后续的数据分析和模型训练提供了高质量的输入样本。
3.1.2 数据预处理
数据预处理是提高模型训练效果的关键步骤。本文采用以下预处理方法:
1. 图像去噪:使用高斯滤波[9]和中值滤波去除图像中的噪声。
2. 灰度调整:对图像进行灰度拉伸,提高图像的对比度。
3. 图像增强[10]:使用数据增强技术,如旋转、缩放、平移和翻转等,扩展数据集,提高模型的泛化能力。
4. 图像分割:将图像分割成若干小块,减少计算量,提高检测精度。
3.2 深度学习模型的选择与训练
(1)模型选择
本文选择YOLOv8作为缺陷检测的核心模型。YOLOv8是Ultralytics公司开发的先进目标检测模型,支持图像分类、物体检测和实例分割。基于前代版本,YOLOv8引入新功能和优化,显著提升了检测精度和速度,非常适合实时任务。YOLOv8强调可定制性和适应性训练,通过自适应训练技术提高学习效率和模型性能。
(2)模型训练
模型训练包括以下步骤:
1. 数据准备:将预处理后的图像数据分为训练集和测试集,确保训练集和测试集的分布一致。
2. 模型构建:YOLOv8模型。
3. 超参数设置:设置学习率、批次大小、训练轮数等超参数。
4. 模型训练:使用训练集对模型进行训练,通过准确率评价指标评估模型性能。
5. 模型验证:使用测试集对训练好的模型进行验证,评估模型的泛化能力。
6. 模型在线学习:收集、积累错误识别数据,人工重新打标之后,纳入训练数据,持续优化训练,提升模型精度与鲁棒性。
3.3 推理加速与部署
(1)TensorRT优化
为了提高模型的推理速度,本文利用TensorRT对训练好的YOLOv8模型进行优化。TensorRT可以通过以下方式优化模型:
1. 图层融合:将多个相邻的计算图层融合为一个图层,减少计算开销。
2. 内核自动选择:根据硬件性能自动选择最优的计算内核。
3. 精度混合:在保证精度的前提下,使用混合精度计算,减少计算资源消耗。
(2)模型部署
优化后的模型部署到NVIDIA Jetson平台上。本文选择Jetson Xavier作为硬件平台,利用其强大的计算能力和低功耗特性,实现实时缺陷检测。部署过程包括以下步骤:
1. 环境配置:安装JetPack SDK,配置CUDA、cuDNN和TensorRT环境。
2. 模型转换:将YOLOv8模型转换为TensorRT引擎,适应Jetson平台的计算架构。
3. 推理实现:编写推理代码,调用TensorRT引擎进行实时推理,并对推理结果进行后处理。
3.4 结果展示与系统管理
3.4.1 结果展示
为了直观展示缺陷检测结果,本文设计了一个图形用户界面(GUI)。GUI界面包括以下功能:
1. 实时显示:实时显示采集到的图像和检测结果。
2. 缺陷定位:对检测到的缺陷进行定位和标注,显示缺陷类型和置信度。
3. 历史记录:存储和展示历史检测结果,便于质量追踪和分析。
3.4.2 系统管理
系统管理模块负责系统的配置、监控和维护。包括以下功能:
1. 模型更新:定期更新和优化深度学习模型,保证系统的检测精度。
2. 数据存储:管理采集到的数据和检测结果,确保数据的完整性和安全性。
3. 运行监控:实时监控系统的运行状态,包括硬件资源使用情况、推理速度和检测精度等。
4. 故障诊断:自动检测和诊断系统故障,提供报警和维护建议。
4.系统分析
4.1 性能评估
4.1.1 检测精度
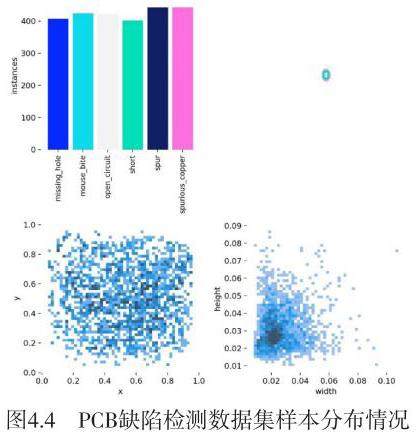
本文采用混淆矩阵[11]、准确率、召回率和F1-score等指标评估模型的检测精度。实验结果表明,基于YOLOv8的缺陷检测模型在测试集上的准确率达到95%以上,召回率和F1-score也均在90%以上,满足需求。
4.1.2 推理速度
在NVIDIA Jetson Xavier NX这一高性能边缘计算平台上,模型经过TensorRT深度学习优化器的精细调优后,推理速度得到了显著增强。实验数据揭示,在该硬件加速器的助力下,单幅图像的推理时间缩短至平均30毫秒,成功达到了实时目标检测任务对处理速度的严格要求。
4.2 系统稳定性
系统稳定性对于工业级应用至关重要,它直接关系到生产效率和产品质量。在本研究中,我们对系统的稳定性进行了严格的评估。具体来说,系统经过了持续48小时的不间断运行测试,以及在设计的最大处理能力下的压力测试。测试结果显示,即便在这些极端条件下,系统也能保持稳定运行,充分证明了其在工业环境中的高可靠性和鲁棒性。
4.3 适应性与扩展性
4.3.1 适应性
本文开发的缺陷检测系统展现了卓越的适应性,能够兼容多样化的PCB产品种类以及广泛类别的缺陷。系统通过动态调整数据预处理策略和优化训练数据集,确保了在多变的应用场景中保持高效的检测性能。
4.3.2 扩展性
系统的架构采用了先进的模块化设计理念,确保了高度的可扩展性和灵活性。用户能够根据特定的应用需求,轻松地对数据采集组件进行扩展或升级,无缝集成不同的深度学习算法模型,并定制化结果呈现机制。此外,系统管理中心模块配备了标准化接口,为未来功能的迭代集成与性能优化提供了便利,从而保障了系统长期的技术适应性和用户定制化需求的满足。
4.4 训练数据分析
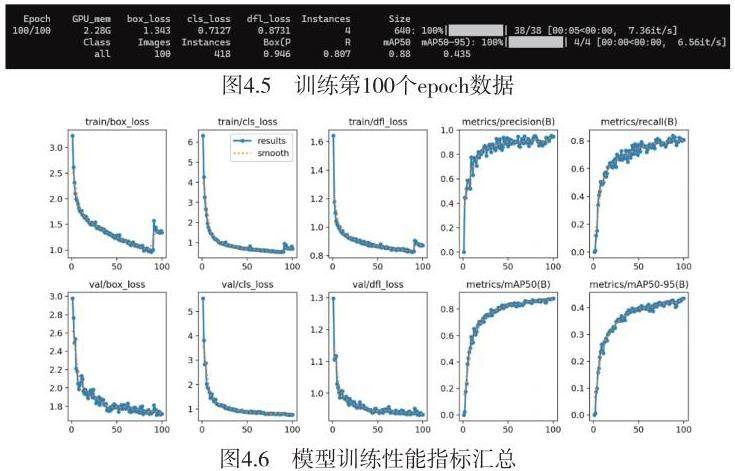
本训练初始数据集采用北京大学发布的PCB缺陷检测数据集:https://robotics.pkusz.edu.cn/resources/dataset/。该数据集训练出一个基础模型之后,再根据具体工业投产的真实环境的标记数据,进行调优训练,以取得能够完成自动检测任务的投产模型。该数据集的分布情况如下:
4.5 训练结果指标分析
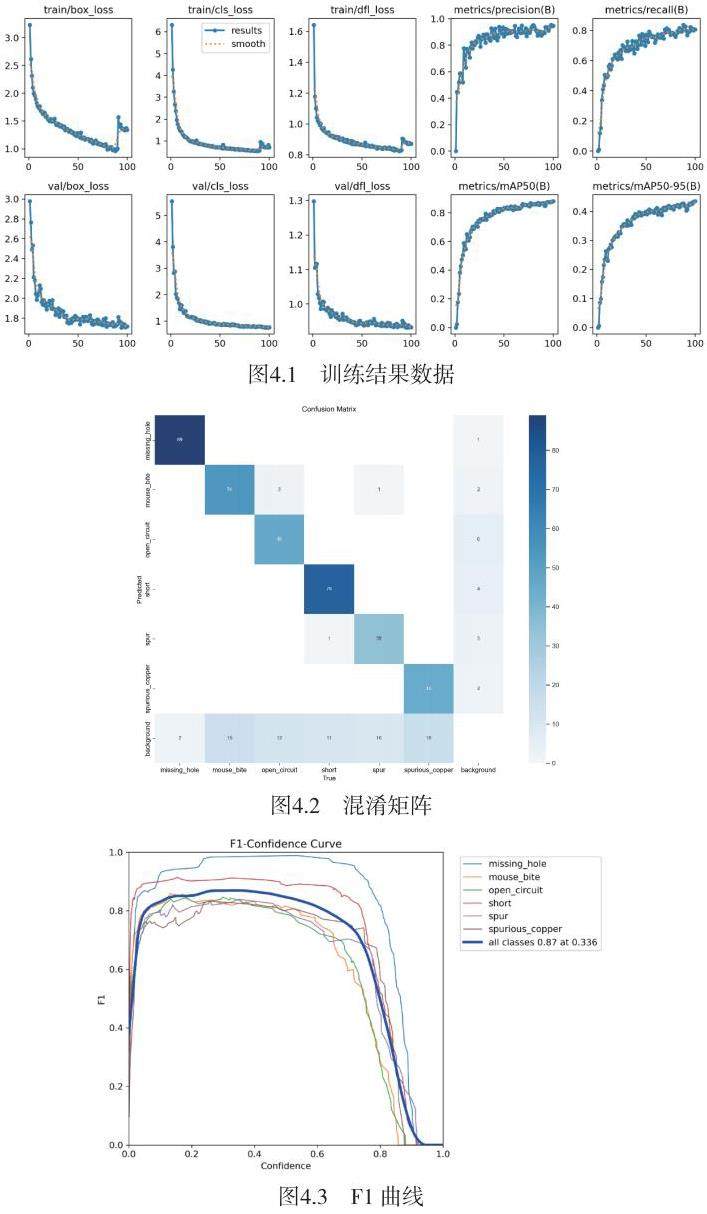
本训练采取的是YOLOv8算法模型。本次设计的训练,共有100次epoch实现迭代过程。其中train 训练阶段涉及到三种不同的损失函数用于评价训练效果,分别是:box loss[12]、cls loss及dfl loss[13]。如下图是第100个epoch时的3个loss数据值。
图4.6模型训练性能指标汇总,可以看到训练train阶段的loss初始阶段快速收敛,之后缓慢下降,但到了90左右epoch时,出现loss反而增大的情况。而验证阶段val在25个epoch迭代下loss接近底部,之后有些反复,也会出现epoch增大loss也增大的情况。导致原因应是学习率设置问题,或者数据增强过度、数据训练不足等原因,不过模型在验证集上表现良好,说明当前验证集上模型的泛化性良好。
为了解决这个问题,使用一些常见的防止欠拟合的方法,如优化学习率、增补新的训练数据等方面进行检查调整,目标是实现train loss和val loss的平稳下降,接近稳定底部区域。还有,从正则化、优化梯度、设定合理批次等方面进行调试,最终实现性能的改进。
图4.6展示的四个关键指标(精确度Precision、召回率Recall、平均精度mAP_50和mAP_50:95)揭示了训练过程中的性能动态。在训练初期,各项指标均呈现出迅速的增长趋势。这可能是验证集与训练集分布相似,实际投产中会可能出现偏差。
为防止数据不均衡、不充分导致训练集模型表现好,实际生产环境表现下降,需要采用在线学习策略。通过在线学习,系统能够逐步整合更多的样本,特别是那些初始阶段样本量较少的缺陷类别。随着样本量的不断累积,通过对模型进行微调训练,可以进一步优化模型性能,实现模型泛化性的逐步提升。这一过程体现了系统设计中对长期性能提升和适应性改进的考量。
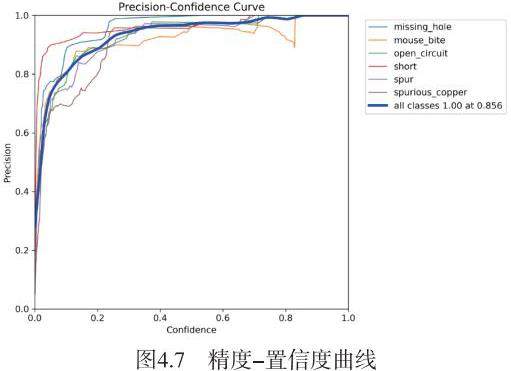
精度-置信度曲线(Precision-Confidence Curve),亦称为P-C曲线,是评估深度学习模型在不同置信度水平下精确度表现的关键工具。P-C曲线的形态对于深度学习模型的性能评估至关重要,尤其在目标检测领域,它为选择一个最佳的置信度阈值以权衡精确度和召回率(Recall)提供了直观的参考。
随着置信度阈值的提升,模型的精确度往往会随之增加,但同时召回率可能会下降,这是因为模型开始排除更多不确定性较高的预测。因此,选择一个合适的置信度阈值对于实现精确度和召回率之间的最优平衡至关重要,这通常需要根据具体的应用场景和业务需求来决定。
在特定应用,如PCB缺陷检测的训练案例中,图4.7所展示的P-C曲线揭示了模型在该任务上的性能特征。曲线显示,随着置信度阈值的提高,预测的精确度呈上升趋势。然而,对于某些缺陷样本量较少的类别,曲线可能会出现锯齿状波动,这通常归因于样本稀疏和类别间不平衡导致的模型预测不确定性增加。这种波动强调了在模型训练和评估过程中需要对数据集的多样性和平衡性给予足够的重视。
在图4.8中展示的召回率-置信度曲线(Recall-Confidence Curve)对应于特定训练周期的性能分析,一个重要的发现表明:当逐步增加置信度阈值时,召回率会相应降低。这种情况在统计学和机器学习中很常见,它表明在追求更高的预测精确度时,可能会以牺牲一定的检测覆盖率为代价。
进一步的分析指出,在0.4至0.6的置信度区间内(肘部区域),多数缺陷分类的阈值选取达到了较优的性能平衡点。这一区间的阈值选择反映了在确保一定程度的预测覆盖率的同时,也获得了较高的精确度,这对于实现高效率的缺陷检测至关重要。在实际应用中,选择这一阈值范围能够最大化模型的效用,同时避免因过高的置信度阈值而引入过多的误报。
此外,对于特定类型的缺陷分类,可能需要根据其在数据集中的分布特性和业务需求,对阈值进行微调,以获得最佳的性能表现。这种细致的调整过程体现了机器学习模型优化中的专业性和复杂性。
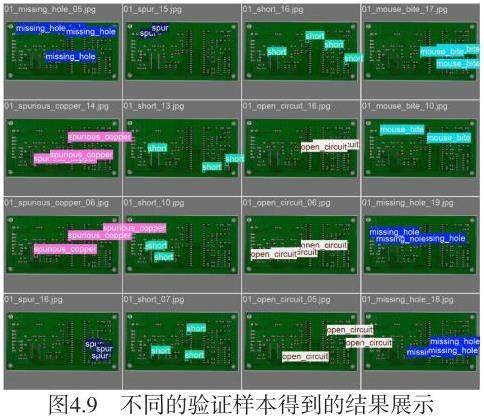
如图4.10所示的一系列精选测试图像案例,所呈现的分类准确性极高,缺陷检测框的定位精度亦与目标缺陷实现了精确匹配。这些成果不仅确证了系统在缺陷分类与定位算法方面的高效性,同时也满足了系统对缺陷检测精准度的严苛技术标准。此外,系统在检测精度上所展现的卓越表现,进一步印证了其在现实应用场景中的稳定性与实用性。
5.结论和展望
5.1 结论
本研究设计并成功实现了一套基于深度学习技术的NVIDIA Jetson平台,专为PCB产品缺陷检测而优化的智能系统。该系统采用先进的高分辨率成像技术捕获高清晰度图像,并实施一系列精密的数据预处理步骤,以显著提升图像数据的质量。在缺陷检测核心环节,系统部署了最新的YOLOv8深度学习模型。为了进一步提升系统效率,我们集成了TensorRT深度学习推理框架,以实现模型推理过程的硬件加速。通过这一系列技术优化,系统不仅能够实现实时、高效的缺陷检测,而且在准确性上达到了行业领先水平。经过严格的实验验证,系统在检测精度、推理速度及长期运行稳定性等关键性能指标上均展现出卓越的性能,充分证明了其在复杂多变的工业环境中的广泛应用潜力和实际应用价值。
5.2 未来展望
尽管本研究开发的系统在多个关键领域实现了技术突破,但面临的挑战和潜在的改进空间不容忽视。针对未来的研究与开发工作,以下几个方面被确定为优化和增强的关键点:
1. 自动化标注与数据增强策略:需深化研究自动化数据标注算法和先进的数据增强框架,以降低对人工标注资源的依赖性,并显著增强模型对新场景的泛化适应性。
2. 模型压缩与加速:应进一步探索模型剪枝、量化和知识蒸馏等模型优化技术,旨在实现模型尺寸和计算需求的显著缩减,同时保持或提升模型的推理精度和速度。
3. 数据增强技术:研究将不同光线、不同尺寸、不同版式的更多类型样本增强训练,辅助以高性能高精度工业相机获取实际投产过程中的高质量图片,提高缺陷检测的准确度和系统的整体鲁棒性。
4. 智能系统运维管理:开发具备高级智能的系统运维管理工具,实现包括自动故障检测、预测性维护[14]和自适应性能调优在内的功能,以提高系统的自我管理和用户交互的智能化水平。
通过这些针对性的研究方向,可以预期系统性能将得到进一步的提升,同时为工业应用带来更加可靠和高效的解决方案。
参考文献:
[1]CHUA L O. CNN:A vision of complexity [J]. International Journal of Bifurcation and Chaos,1997,7(10):2219-425.
[2]CRESWELL A,WHITE T,DUMOULIN V,et al. Generative adversarial networks:An overview [J]. IEEE signal processing magazine,2018,35(1):53-65.
[3]NG A. Sparse autoencoder [J]. CS294A Lecture notes,2011,72(2011):1-19.
[4]KUSNER M J,PAIGE B,HERNáNDEZ-LOBATO J M. Grammar variational autoencoder;proceedings of the International conference on machine learning,F,2017 [C]. PMLR.
[5]MITTAL S. A survey on optimized implementation of deep learning models on the nvidia jetson platform [J]. Journal of Systems Architecture,2019,97:428-42.
[6]TERVEN J,CóRDOVA-ESPARZA D-M,ROMERO-GONZáLEZ J-A. A comprehensive review of yolo architectures in computer vision:From yolov1 to yolov8 and yolo-nas [J]. Machine Learning and Knowledge Extraction,2023,5(4):1680-716.
[7]姜强,赵蔚,王朋娇,王丽萍. 基于大数据的个性化自适应在线学习分析模型及实现[J].中国电化教育,2015,(1):85-92.
[8]JEONG E,KIM J,HA S. Tensorrt-based framework and optimization methodology for deep learning inference on jetson boards [J]. ACM Transactions on Embedded Computing Systems(TECS),2022,21(5):1-26.
[9]王振华,窦丽华,陈杰. 一种尺度自适应调整的高斯滤波器设计方法[J].光学技术,2007,33(3):395-7.
[10]王浩,张叶,沈宏海,张景忠. 图像增强算法综述[J].中国光学(中英文),2017,10(4):438-48.
[11]张静,宋锐,郁文贤,et al. 基于混淆矩阵和 Fisher 准则构造层次化分类器 [J]. 软件学报,2005,16(9):1560-7.
[12]REZATOFIGHI H,TSOI N,GWAK J,et al. Generalized intersection over union:A metric and a loss for bounding box regression;proceedings of the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition,F,2019 [C].
[13]LI X,WANG W,WU L,et al. Generalized focal loss:Learning qualified and distributed bounding boxes for dense object detection [J]. Advances in Neural Information Processing Systems,2020,33:21002-12.
[14]袁烨,张永,丁汉.工业人工智能的关键技术及其在预测性维护中的应用现状[J].自动化学报,2020,46(10):2013-30.

 京公网安备 11011302003690号
京公网安备 11011302003690号


