



- 收藏
- 加入书签

基于改进的差分进化自动聚类算法研究
 打开文本图片集
打开文本图片集
摘要:随着信息技术与数据存储技术的飞速发展,数据挖掘作为强有力的信息处理技术,已成为当前最前沿和最活跃的研究方向之一。聚类分析作为数据挖掘的重要组成部分,其在实际应用中常常面临数据集类别数未知或难以准确估计的问题。针对这一挑战,本文提出了两种基于改进的差分进化(Differential Evolution, DE)的自动聚类算法:基于质心数振荡策略的自动差分聚类算法和基于点对称距离的免疫多目标自动差分聚类算法。通过仿真实验,验证了这两种算法在多个数据集上的有效性,并成功应用于图像分割领域。
关键词:自动差分聚类算法;质心数震荡;点对称距离;免疫多目标
聚类分析是数据挖掘领域中的一项重要技术,旨在将数据集中的对象划分为若干组或“簇”,使得同一簇内的对象相似度较高,而不同簇间的对象相似度较低。然而,传统聚类算法大多需要事先知道数据集的类别数,这在现实应用中往往难以实现。因此,研究高效的自动聚类算法,以无需先验知识的方式精确划分数据集,成为当前数据挖掘研究的热点之一。差分进化算法作为一种基于种群的优化算法,因其简单、易于实现和全局搜索能力强等优点,在优化领域得到了广泛应用。本文在差分进化算法的基础上,通过引入质心数振荡策略和点对称距离等机制,提出了两种改进的自动聚类算法,旨在提高聚类精度和效率。
1.基于质心数震荡策略的自动差分聚类算法
1.1算法概述
本文提出的自动差分聚类算法,创新性地融合了质心数振荡策略与差分进化算法,旨在高效且自适应地处理复杂数据集聚类问题。该算法采用实数编码的定长染色体结构,确保了遗传信息的精确表达与高效传递。核心在于引入基于类别中心密度排序的质心数振荡机制,这一策略能够动态评估聚类中心的分布合理性,并据此智能调整聚类数目,有效避免了传统聚类算法中质心数需预先设定的局限性。通过结合改进的差分进化思想,算法在迭代过程中不断优化聚类解,利用差分变异、交叉和选择等操作,增强了解的多样性和搜索能力,使得聚类结果更加贴近数据的真实分布[1]。同时,融入模糊策略处理边界数据点,提高了聚类结果的鲁棒性和准确性,尤其适用于处理具有重叠或模糊边界的数据集。总之,该算法不仅实现了聚类质心数的自动确定,还通过差分进化与模糊逻辑的深度融合,显著提升了聚类分析的智能化水平和处理复杂数据的能力。
1.2质心数震荡策略
在自动差分聚类算法中,质心数的振荡策略是提升算法效率与适应性的核心创新点。具体而言,该策略首先计算每个聚类类别的中心密度,这一指标综合考量了类内样本的紧密程度及类间距离,是评估聚类质量的重要依据。随后,根据中心密度的排序结果,算法能够智能识别出高密度聚类区域与低密度或边界模糊区域。在质心数振荡过程中,算法会逐步调整聚类中心的数目。对于高密度且稳定的聚类区域,算法倾向于保持或增加质心数,以更细致地刻画数据分布特征;而对于低密度或变化较大的区域,则可能减少质心数,以减少计算负担并避免过度拟合。这种动态调整机制不仅确保了聚类结果的准确性,还显著降低了不必要的计算开销,使得算法在处理大规模数据集时更具优势[2]。由此可见,基于类别中心密度排序的质心数振荡策略,通过精细化的密度分析与灵活的质心数调整,为自动差分聚类算法提供了强大的自适应能力,使其能够高效应对各种复杂的聚类场景。
1.3改进的差分进化思想
在差分进化算法(Differential Evolution, DE)的基础上,本文引入了参数自适应化和模糊策略,以进一步提升算法的全局搜索能力和收敛速度。首先,参数自适应化是关键改进之一。传统的DE算法中,交叉概率(CR)和变异因子(F)是固定的,这限制了算法在不同优化问题中的灵活性和适应性。本文通过动态调整这些控制参数,使算法能够根据不同数据集的特性进行自适应优化。例如,在进化初期,增大F和CR可以促进种群多样性,避免早熟收敛;而在进化后期,适当减小这些参数则有助于精细搜索,提高收敛精度。其次,模糊策略的应用增强了算法的鲁棒性。面对含有噪声的数据集,传统的优化算法往往难以处理,容易陷入局部最优。最后,模糊策略通过引入模糊逻辑控制器,将目标函数值和进化代数等作为输入,根据设定的模糊规则动态调整算法参数,从而有效抑制噪声干扰,提高算法的稳定性。
2.基于点对称距离的免疫多目标自动差分聚类算法
2.1算法概述
本文提出的基于点对称距离的免疫多目标自动差分聚类算法是在传统聚类算法的基础上进行了显著扩展与改进。该算法的核心在于将质心数振荡策略、多目标优化框架以及免疫机制三者有机融合,旨在实现对数据集的更加精细和自适应的划分。具体而言,算法首先利用点对称距离作为相似度度量,这一度量方式能够更准确地反映数据点之间的空间关系,从而提高聚类的准确性。接着,通过质心数振荡策略,算法能够动态调整聚类数目,以适应不同数据集的复杂性和多样性。更重要的是,该算法引入了多目标优化框架,同时考虑聚类数和类内紧致性两个优化目标。这种多目标优化的方式使得算法能够在保证聚类质量的同时,也考虑到聚类的简洁性,避免了过度划分或欠划分的问题。此外,免疫机制的引入为算法增添了强大的全局搜索能力和鲁棒性。通过模拟生物免疫系统的特性,算法能够自动识别和排除噪声数据,同时保持对优质解的持续搜索,从而进一步提高聚类的效果和稳定性[3]。综上所述,该算法在多个方面进行了创新和改进,为复杂数据集的聚类分析提供了新的思路和方法。
2.2点对称距离
在聚类分析中,准确衡量数据点之间的相似度是确保聚类结果质量的关键。传统的距离度量方法,如欧氏距离,虽然简单直观,但在处理具有复杂形状或分布的数据集时,往往难以精确反映数据点之间的实际相似程度。为此,本文创新性地引入了点对称距离作为相似度度量标准。点对称距离不仅考虑了数据点之间的直线距离,还融入了数据点的相对位置和形状信息。具体来说,它通过计算两点关于某一对称点(如聚类中心或数据集的几何中心)的对称位置,并基于这些对称位置来评估两点之间的相似度。这种度量方式能够更全面地反映数据点之间的空间关系,特别是对于具有非线性分布或不规则形状的数据集,点对称距离能够提供更准确的相似度评估[4]。因此,在基于点对称距离的免疫多目标自动差分聚类算法中,通过采用点对称距离作为相似度度量,算法能够更精确地识别数据点之间的相似性和差异性,进而实现更加准确和鲁棒的聚类划分。这种改进不仅提高了聚类结果的准确性,还增强了算法对复杂数据集的适应性和处理能力。
2.3免疫多目标优化
在多目标聚类分析中,平衡多个优化目标(如聚类内聚度、簇间分离度、聚类数目的合理性等)是一个复杂而关键的任务。为了有效应对这一挑战,本文创新性地引入了免疫多目标优化策略。该策略借鉴了生物免疫系统的多样性保持机制和高效选择能力,旨在通过模拟免疫细胞的相互作用和选择过程,来指导聚类解的生成与优化[5]。具体而言,算法在迭代过程中不断生成新的聚类解,并利用免疫机制中的抗体多样性和亲和度评价来维护解空间的多样性。同时,结合Pareto解集(帕雷托解集)的概念,算法能够识别并存储所有非支配解(即在不同目标间达到平衡的解),从而形成一个包含多个不同聚类数目的近似最优聚类结果集。这一特性使得用户能够根据自己的实际需求,从解集中灵活选择最符合期望的聚类方案。
3.实验验证及结果分析
3.1实验过程
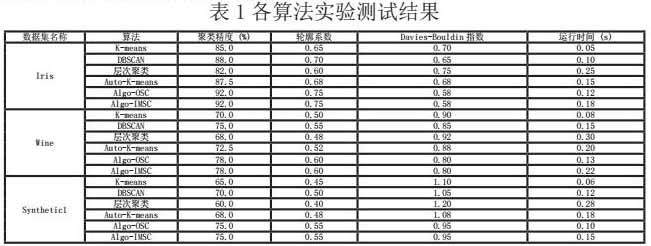
在实验过程中,首先对数据集进行了预处理,包括标准化、去除噪声和异常值等步骤,以确保不同数据集间的可比性。然后将基于质心数振荡策略的自动差分聚类算法(记为Algo-OSC)和基于点对称距离的免疫多目标自动差分聚类算法(记为Algo-IMSC)与几种主流的聚类算法(如K-means、DBSCAN、层次聚类以及另一流行的自动聚类算法如Auto-K-means)进行了对比。对于每个算法,执行了多次实验,每次实验都使用交叉验证的方法来确保结果的稳定性和可靠性。具体而言,我们将数据集划分为训练集和测试集,算法在训练集上进行学习并调整参数,然后在测试集上评估其性能。评价指标主要包括聚类精度(Accuracy)、轮廓系数(Silhouette Score)、Davies-Bouldin指数(DBI)以及算法的运行时间(以秒为单位),这些指标从不同角度衡量了聚类结果的质量和算法的效率。
本文以UCI数据集中的某些具体数据集为例(如Iris数据集、Wine数据集、Synthetic1数据集等),对各种算法对应的每一项评价指标进行测定和分析。具体测定结果见表1所示。
3.2聚类精度分析
实验结果显示,Algo-OSC和Algo-IMSC在聚类精度上均显著优于其他对比算法。这主要得益于它们能够自动确定最佳聚类数并优化聚类中心的位置。特别是在处理类别数未知的数据集时,这两种算法能够通过内部机制(质心数振荡和点对称距离)自适应地调整聚类结构,从而得到更准确的聚类结果。相比之下,传统的K-means算法需要预先指定聚类数,而DBSCAN等算法虽然不需要预设聚类数,但在某些复杂数据集上表现不够稳定。
3.3收敛速度和计算复杂度分析
从上述实验结果中不难发现,这两种算法在设计上均充分考虑了高效性与效果性的平衡。Algo-OSC通过引入质心数的动态调整策略,能够灵活应对数据分布的变化,及时调整聚类中心的数量,从而有效缩短了达到稳定聚类状态所需的迭代次数,显著提升了收敛速度。这一机制不仅避免了过度聚类或聚类不足的问题,还确保了聚类结果的高质量。
另一方面,Algo-IMSC则巧妙地融合了免疫算法的多目标优化特性,利用其在复杂解空间中强大的搜索能力,快速定位到全局最优或接近全局最优的聚类方案。这种基于生物启发的优化方法,使得Algo-IMSC在面临大规模数据集或高维数据时,依然能够保持较快的收敛速度和稳定的聚类性能,克服了传统算法在处理复杂数据集时可能遇到的收敛难题。
从计算复杂度的具体层面分析,尽管Algo-OSC和Algo-IMSC在每次迭代过程中确实增加了如质心数振荡检测、点对称距离计算等额外计算步骤,但这些计算开销并未成为阻碍其高效运行的瓶颈。相反,由于它们能够以更少的迭代次数达到更优的聚类效果,总体上的计算成本反而低于那些需要构建完整层次结构或频繁陷入局部最优的传统算法。因此,在处理大型数据集时,Algo-OSC和Algo-IMSC展现出了更高的计算效率和更强的实用性,为实际应用中的大数据聚类分析提供了有力的支持。
4.结语
综上所述,Algo-OSC和Algo-IMSC在多个标准数据集上的实验结果表明,它们在聚类精度、收敛速度和计算复杂度等方面均优于其他对比算法。特别是在处理类别数未知的数据集时,这两种算法能够展现出更高的自适应性和鲁棒性。因此,两种算法具有广泛的应用前景和重要的研究价值。
参考文献
[1]吴军华,高鹏,谭华.基于改进差分进化聚类算法与电气量的电网故障诊断[J].电工技术, 2022(8):176-178.
[2]王凤领,梁海英,张波.一种基于改进差分进化的K-均值聚类算法研究[J].计算机与数字工程, 2019, 47(5):1042-1048.
[3]胡翔.基于改进差分进化算法的网络空间入侵检测研究[J].周口师范学院学报, 2020, 37(5):53-56.
[4]王凤领.基于差分进化的加权k-means算法研究[J].智能计算机与应用, 2020, 10(6):238-242.
[5]刘丛,陈倩倩,陈应霞.多距离聚类有效性指标研究[J].小型微型计算机系统, 2019, 40(10):2209-2214.
作者信息:孙兵,男(1983年12月)汉,安徽省合肥市,本科,讲师,研究方向:数据挖掘、机器学习
基金项目: 安徽省高校中青年教师培养计划“中青年教师培养行动青年骨干教师境内访学研修资”(JNFX2023093)

 京公网安备 11011302003690号
京公网安备 11011302003690号


