



- 收藏
- 加入书签

基于预训练大模型的知识增强与建筑施工方案优化研究
 打开文本图片集
打开文本图片集
摘要:本文提出一个新框架,旨在提升大型语言模型在建筑领域的专业能力和应用水平。虽然LLM在通用任务上有优秀表现,但在建筑等特定领域存在不足,主要因缺乏相关领域知识及应用能力。为改进这一状况,本研究首先搜集大量建筑领域文本数据,并通过持续预训练让模型掌握专业知识。其次,利用专家提供的问题解决方案和指令调优数据集来训练模型在实践中运用所学知识。此外,还加入检索模块,在回答问题时整合相关行业标准,提高答案的准确性和可靠性。针对长文本生成任务,采用MINI-SEQUENCE TRANSFORMER (MST)方法优化内存管理,使模型能处理更长序列数据。最后,通过自动与人工评估确保模型的有效性。
关键词:大语言模型,建筑领域,长文本生成,指令调优
1引言
1.1 建筑领域的知识增强
在使用指令调优增强开源大语言模型时,ChatGLM等模型在各种通用任务上取得了显著的性能提升。然而,由于缺乏数据和不适当的训练范式,将大型语言模型( Large Language Models,LLMs )适配到建筑等特定领域仍然是一项具有挑战性的任务。
为了缓解模型缺乏领域知识和无法利用特定领域知识解决问题,我们提出了一个新的框架来适应特定领域的LLM。它需要三个步骤来训练一个可靠的特定领域的LLM:
(1)来源广泛的领域知识
我们收集了大量的建筑领域的原始文本,如施工方案、施工工艺等。然后,我们采用持续的预训练来帮助模型获得法律知识。
(2)向专家学习专业技能
为解决实际问题,领域专家会对不同的概念进行分析,将抽象的概念和理论映射到具体的场景中。我们通过专家收集实际问题的解决方案,并使用它们来教导模型如何使用适当的知识来解决特定领域的任务。
(3)用外部知识增强并过滤掉不相关的
为了缓解模型的幻觉问题并生成更可靠的回复,我们额外引入了信息检索模块。在建筑领域,行业规范被检索出来,并作为外部知识来回答客户的询问。
1.2 施工方案的长文本生成
随着模型尺寸的增长,训练过程中面临的内存需求也随之急剧增加,这成为了一个关键挑战。
为了解决这一挑战,我们运用了MINI-SEQUENCE TRANSFORMER (MST)[3],这是一种简单而有效的方法,用于在训练具有极长序列的大型语言模型(LLM)时高度有效地管理内存。MST通过将输入序列分割成多个较小的子序列(mini-sequences)并在这些子序列上迭代地执行处理,显著减少了中间内存的使用量。
2数据收集
2.1 建筑知识型数据
先前的工作揭示了语言模型可以利用从特定领域语料库中学习到的知识,并且这些模型可以比只在通用语料库上预训练的模型更好地处理相应领域的任务。为了使我们的模型具有更多的中文建筑知识,我们从中国建筑的网站上收集文本,包括建筑设计文档、施工方案、建筑规范以及各种建筑学文章。
2.2 建筑问答型数据
为了构建一个高质量的问答数据集来训练和评估模型,我们采用了注册建筑师考试的题目、房屋建筑学复习题以及一些建筑学在线问答资源。我们首先将这些选择题转换为问答形式,即从每道题目中提取出问题,并将正确答案作为问题的答案。
3训练方法
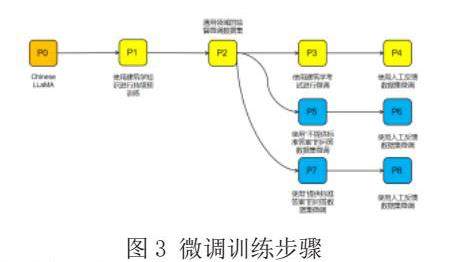
图3展示了如何一步一步地对开源模型LLaMA进行微调,使其适用于中国建筑领域。由于用于Chinese-LLaMA的建筑领域语料库较少,我们的首要任务是为其注入建筑学知识(图3中P1)。然后,为了教导模型遵循人类的指令,使用通用领域的监督微调数据集(图3中的P2)对其进行训练。之后,在不同版本的CoT[5](图3中的P3,P5和P7)建筑考试试题上对该模型进行训练,教会其运用法律知识进行推理,以解决实际问题。最后使用人工反馈学习(图3中的P4,P6和P8)对模型进行进一步的调优。
3.1 建筑学专业知识注入
为了弥补Chinese-LLaMA模型中法律知识的不足,我们在2.1节进一步使用中文建筑语料库对其进行预训练。该语料库包含了建筑领域的各种中文文本,包括建筑设计文档、施工方案、建筑规范以及各种建筑学文章,可用于进一步的继续训练。我们希望通过不断的预训练,将语料库中丰富的法律知识注入到Chinese-LLaMA中。我们还添加了通用领域文本,以防止我们的模型对法律语料库的过拟合。其中,数据集的结构如图4,我们使用了lang-chain的TextSpliter对文本进行了初步的分割,使得模型能够更好的接收和学习数据。
3.2 学习推理技能
解决实际问题需要模型在法律领域的推理技巧。为此,我们从下游任务中选择有监督的数据,并使用指令来调整我们的模型。
首先用来自Alpaca - GPT - 4的约50000个实例来训练模型,使其具有一般的指令跟随能力。随后,使用2.2节中不同版本的CoT进行指导语调优。分别使用带有正确答案和没有正确答案的数据集对模型进行训练,以便提高模型的鲁棒性。
3.3 检索相关行业规范
我们将相关的建筑行业规范文档进行分块处理,并使用先进的文本嵌入模型对这些文本块进行向量化处理,以捕捉每个条款的核心内容和上下文语境;接着,将这些向量化后的文本块存储在一个高效的向量数据库中,以便快速找到与特定问题最相关的规范条款;当用户提出问题时,模型首先尝试理解问题的内容,并将其转换为相应的向量表示,然后调用检索器来查询向量数据库,找到与问题最相关的行业规范片段,并将这些信息整合到模型生成的回复中,确保回复的准确性和权威性。
4总结
本研究开发了一个新的框架,旨在增强大型语言模型在建筑领域的专业知识和应用能力。我们通过收集大量专业领域文本并采用持续预训练的方式解决了模型缺乏领域知识的问题。此外,通过使用专家编写的问题解决方案和指令调优数据集,我们教导模型如何有效地应用所学知识来解决实际问题。为了提高模型回答问题的准确性和可靠性,我们引入了一个检索模块,用于在回答问题时检索相关的行业规范。针对长文本生成任务,我们借鉴了一种名为MINI-SEQUENCE TRANSFORMER (MST)的方法,该方法能够有效管理内存资源,使模型能够处理更长的序列数据。我们还设计了一系列自动和人工评估方法来验证模型的有效性。未来的研究方向将集中在进一步优化模型的逻辑推理能力和增强其在更多实际应用场景中的表现。
参考文献
[1]崔一鸣*, 杨子清*, 姚鑫,“适用于中文LLaMA和Alpaca的高效文本编码”,发表于《计算语言学》,2024.02.23。
[2]罗程,赵家伟,陈卓明等人,“MINI-SEQUENCE TRANSFORMER: 优化长序列训练的中间内存”,发表于cs.LG,2024年7月22日。
[3]林进耀,“ROUGE: 一种自动评估摘要的工具包”,发表于《文本摘要分支》,2004年7月。

 京公网安备 11011302003690号
京公网安备 11011302003690号


