



- 收藏
- 加入书签

国家数字经济创新发展试验区如何重塑企业创新生态?
——基于双重机器学习视角下的准自然实验
摘要:“惟创新者进,惟创新 动力, 是贯穿企业和经济高质量发展始终的核 要 市场的形成及日渐成熟推动了创新 使用双重机器学习(DDML)方法 业创新。经过平行趋势检验、 中部地区显著为正, 著。最后,机制检验发现 推动数字经济创新发展和企业高质量发展提出可行性
关键词:国家数字经济创新发展试验区、企业创新、双重机器学习、异质性分析
一、引言
近年来,世界范围内数字技术快速发展,数字资源广泛渗透至人们的生产和生活中,随之产生了新的经济形态——数字经济。企业持续创新是适应时代的关键。它通过重组生产要素,既是引领高质量发展的核心动力,也是突破技术瓶颈的根本出路 。数字经济通过宽带、数字金融等技术赋能企业转型。依据资源基础观,这些数字资源是企业获取持续竞争优势的关键。企业利用数字工具能优化运营、提升资源效率并实现可持续发展,例如通过数据分析优化供应链、以自动化减少能耗。在此背景下,国家将“数字中国”作为核心战略,旨在培育新动能、推动新发展。因此,深入探究国家数字经济试验区政策对企业创新的影响机制,对于促进数字经济发展、加速企业转型升级及实现区域高质量发展具有至关重要的理论与现实意义。
现有文献已从多个维度对数字经济政策的企业效应展开了深入探讨,为本研究奠定了坚实的理论基础。具体而言,针对“宽带中国”战略,研究普遍证实其作为信息基础设施的普及,能够显著提升企业的技术创新水平并为其创新活动有效赋能。在智慧城市建设方面,学术界的共识是其通过优化城市治理与资源配置,显著增强了企业的绿色创新,并实现了创新数量与质量的“增量提质”。而对于国家级大数据综合试验区,研究则表明其通过数据要素的集聚与开放,有力推动了企业的数字化转型与数字技术创新。随着数字经济战略的深化,部分学者已将目光投向国家数字经济创新发展试验区,初步研究证实了该政策在促进企业数字化转型及激发区域与企业层面创新活力方面的积极作用。
尽管上述研究为我们理解国家数字经济创新发展试验区政策效应提供了宝贵参考,但仍存拓展空间。首先,针对国家数字经济创新发展试验区的实证研究尚处起步,其机制与边界有待深挖。更重要的是,传统双重差分模型(DID)易因遗漏变量产生内生性问题,导致估计偏误。为克服此局限,本研究引入双重机器学习(DDML)方法。该方法能有效处理高维控制变量,在消除混淆因素影响的同时避免函数形式误设,从而为评估试验区政策对企业创新的净效应提供更稳健、精准的证据。
本研究旨在系统考察国家数字经济试验区设立对企业创新的影响机制及作用效果。为实现这一目标,我们以 2019-2022 年 A 股上市公司数据为基础,采用双重机器学习(DDML)方法构建因果推断模型,重点分析了试验区政策对企业创新投入与产出的影响效应。研究发现,数字经济试验区政策显著提升了企业创新水平,该促进效应在非国有企业、中小企业及高技术行业中表现更为突出。本文的创新价值主要体现在三个方面:理论层面,通过准自然实验设计验证了数字经济政策对企业创新的正向作用,为政策推动经济高质量发展提供了微观层面的经验证据;方法层面,创新性地将DML 模型应用于政策评估研究,有效克服了传统计量方法中遗漏变量导致的内生性问题,提高了结论的可靠性;机制层面,揭示了政策通过打破组织惯性和提高知识多样性两条路径促进企业创新的传导机制,为理解数字经济政策的微观作用机理提供了新的理论视角。
二、政策背景与理论假说
1. 政策背景
以数字技术为核心的数字经济正成为推动全球产业变革与高质量发展的新动能。党的二十大强调要促进数字经济与实体经济深度融合。然而,数字经济在降低成本、促进创新的同时,也颠覆了传统商业模式,使企业面临高昂的转型成本。此外,数字平台垄断易导致数据低效使用、扩大数字鸿沟,引发市场失灵。企业转型困境与市场失灵构成数字经济发展的重大阻碍。因此,政府如何有效发挥“有形之手”的帮扶作用,引导数字经济健康发展,成为亟待解决的问题(王彦勇,沙飞,2025)。
2019 年 10 月,国家发展改革委、中央网信办印发《国家数字经济创新发展试验区实施方案》,标志着试验区建设工作正式启动。首批试验区包括河北省(雄安新区)、浙江省、福建省、广东省、重庆市、四川省等 6 个省(市、区)。试验区在推动数字经济进程中采取了多维度、系统性策略:第一,创新驱动与模式创新,支持平台经济、共享经济等新业态发展,鼓励金融机构探索适合数字化转型项目的融资模式。第二,系统优化与高效配置,优化数字经济各要素的流通机制。第三,政策协同与区域协同,强化跨部门政策协同,确保政策措施有效衔接。第四,生态构建与治理提升,构建完善的数字经济生态体系,促进数字经济与实体经济深度融合(朱嘉禾,2024)[2]。根据《方案》要求,试验区将围绕数字经济发展关键问题展开针对性改革试验探索,预计通过3年左右时间,显著推进区域内产业数字化和数字产业化进程,实现经济发展增质提效。
2. 理论机制与研究假说
(1)实施国家数字经济创新发展试验区建设可以推动企业创新。
数字经济是以 IT 技术、云计算、人工智能为基础,数据要素已成为最具效率与活力的生产要素。学者王丹等认为,数字经济能驱动传统产业创新发展,通过其与实体经济的融合,有利于打造具备国际竞争力的数字产业集群。学者杨鹏等的研究发现,数字技术应用能显著提升企业创新效率。数字经济可突破信息传递壁垒,使信息获取高效简便,加速企业知识资源与创新要素的增长,为创新提供充足动力[1]。学者们普遍认为数字经济对企业的影响主要集中在技术创新上。研究表明,数字经济能提高创新速度与能力(Teece,2018),推动产品服务升级以增强市场活力(Dennett&Roy,2015),并通过技术多元化等渠道显著促进企业创新表现,这一过程也可能受到行业从众效应的影响(Rindetal.,2023)。基于此,提出假设 1。
1:实施国家数字经济创新发展试验区建设可以推动企业创新。
(2)国家数字经济创新发展试验区影响企业创新的机理。
H2:国家数字经济创新发展试验区能够通过打破企业的组织惯例、提高知识多样性,促进企业创新。
H2.1:国家数字经济创新发展试验区能够通过打破企业的组织惯例,进而促进企业创新。
组织惯例是基于“干中学”而形成的固化反应模式,虽有助于降低成本,但也可能阻碍创新。例如,专注于效率的全面质量管理会排挤探索性活动,从而限制企业把握新机会的能力(BennerandTushman,2003)[7]。打破组织惯例对企业创新至关重要,而国家数字经济创新发展试验区正是推动这一变革的关键力量。试验区通过政策引导与资源整合,帮助企业突破传统模式,并利用数据驱动的机制重塑知识管理流程。通过数据共享与智能分析,企业能自动识别市场机会,以多维分析框架取代单一经验,从而鼓励探索新策略,有效推动新产品开发,营造了更具竞争力的创新环境 [3]。
H2.2:国家数字经济创新发展试验区能够通过提高知识多样性,促进企业创新。
知识多样性被认为是企业知识库类别的多样性水平,反映从事不同技术领域专业知识的广度(BonnerandWalker,2004)。基于知识基础视角,知识是企业获得可持续竞争优势和促进创新的关键战略资源(NemetandJohnson,2012;刘岩等,2015)。企业的创新需要建立在共享的科学原理或相似的搜索启发式的知识体系之上。这样的共享基础使企业能够有效利用来自不同领域和行业的多样化知识,识别知识组合的可能性并整合跨领域知识(Gruberetal.2013)[8]。此外,知识多样性中蕴含的互补优势显著促进跨领域间的合作,进而增强知识整合的有效性。
综上,本文的理论模型结构如图1 所示。
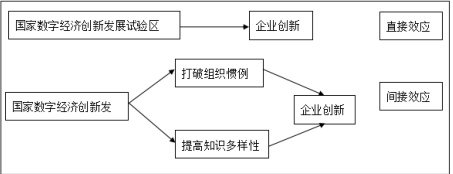
图 1 理论模型结构
三、研究设计
1. 数据来源
本文以中国沪深 A 股上市企业为研究对象,样本时间为 2012—2022 年。上市企业年报来自巨潮资讯网;专利数据来源于经济金融数据库(CCER);企业基本信息和财务数据取自国泰安数据库(CSMAR)。为确保数据的质量,进行以下处理: ① 剔除金融行业的企业; ② 排除当年企业处于 ST 和 *ST 状态的样本; ③ 剔除数据缺失严重的样本; ④ 为消除极端值的影响,本文对连续变量在 1% 和 99% 的水平上进行缩尾处理。
2. 模型设立
为探究国家数字经济创新发展试验区政策对城市绿色技术创新的影响,本文采用双重机器学习模型。相较于传统方法,该模型能有效处理变量间的非线性关系,并通过正交化思想剔除高维混淆变量的干扰,从而在有限样本下获得更无偏的政策效应估计。因此,本文构建如下的双重机器学习部分线性模型:
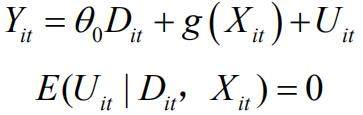
其中, Yit 为 i 城市第 t 时期的企业创新, Dit 代表地区及时间对应的国家数字经济创新发展试验区虚拟变量, θ0 为政策对应的处置系数。Xit 为控制变量集合,可能包含同时影响 Yit 和 Dit 的混淆变量,具体的函数形式 g(Xit) )未知,本文将采用机器学习算法得到其估计 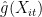 。 Uit 为误差项,条件均值为 0
。 Uit 为误差项,条件均值为 0
若采用机器学习算法对上述模型中的 g(Xit) 直接求解,则此时得到的估计系数 θ0 为正则化估计量,有限样本下有偏,因此,进一步构建的辅助回归如下:
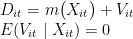
公式3公式4
其中,函数形式 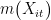 未知,
未知, 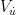 为误差项,条件均值为 0 因此,本文采用机器学习算法估计
为误差项,条件均值为 0 因此,本文采用机器学习算法估计 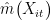 ,并以此构建残差估计
,并以此构建残差估计 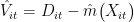 ,然后采用同样算法估计主回归中的
,然后采用同样算法估计主回归中的 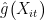 ,获得
,获得 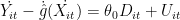 ,并将 Vit 看作 Dit 的“工具变量”进行回归,获得的系数估计量如下:
,并将 Vit 看作 Dit 的“工具变量”进行回归,获得的系数估计量如下:
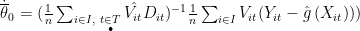
此时, θ0 的收敛速度将取决于 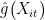 、 mˆ Xit ) 向 g X t)、
、 mˆ Xit ) 向 g X t)、 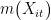 的收敛速度。两次机器学习估计一方面有利于排除处置变量
的收敛速度。两次机器学习估计一方面有利于排除处置变量 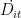 中由混淆变量集合 Xit 导致的影响,另一方面,则能够加快 θ0 的收敛速度,进而获得有限样本下的准确估计。另外,为提高模型估计的稳定性和可靠性,本文在回归中采用 5 折分割拟合的方法处理回归样本,并通过重复采样 101 次取中位数调整的结果来作为最终估计结果,具体操作请参见Chernozhukov 等(2018)[9]。
中由混淆变量集合 Xit 导致的影响,另一方面,则能够加快 θ0 的收敛速度,进而获得有限样本下的准确估计。另外,为提高模型估计的稳定性和可靠性,本文在回归中采用 5 折分割拟合的方法处理回归样本,并通过重复采样 101 次取中位数调整的结果来作为最终估计结果,具体操作请参见Chernozhukov 等(2018)[9]。
3. 变量构建
(1)被解释变量:企业创新(Innov)
本文从经济金融数据库(CCER)中获取中国上市企业的发明专利信息,包括申请日期、国际专利分类号、主分类号、专利类型以及页数等数据。本文使用上市企业当年发明专利申请量加 1 取对数来衡量企业创新。
(2)核心解释变量:国家数字经济创新发展试验区(did)
didit 是treated 与 post 的交互项,若某城市入选为国家数字经济创新发展试验区试点地区,则treated 等于 1,否则treated 等于 0;若实施政策年份在 2019 年及其以后则 post 等于1,否则等于 0
(3)机制变量
B_routines
为验证假说 H2.1,本文使用文本分析法来获取表征打破组织惯例程度的指标。参考张倩肖和段义学(2023)[5] 的做法,主要分为以下三个步骤[3]: ① 利用Python 从上市企业年报中提取经营情况分析文本,并通过人工判读筛选出在打破组织惯例方面表现突出的企业样本。 ② 对样本企业进行分词处理和词频统计,筛选出与打破组织惯例相关的高频词汇,并参考吕一博等(2016) 的研究,补充相关关键词,形成涵盖企业架构、制度、流程等方面的打破组织惯例分词词典。具体关键词包括优化组织架构、组织架构变革、组织变革、变革组织、变革规章制度、变革流程管理、变革管理、变革文化意识、转变业务模式、转变运营模式、流程重构、业务流程再造等。 ③ 针对上市企业所有年报文本,统计上述关键词出现的频次,并采用加 1 取对数的方式来度量企业打破组织惯例的情况,变量名为 B_routines 。
K_diversity1、K_diversity2
本文借鉴沈坤荣等(2023)的方法,利用国际专利分类号(IPC)大组信息来测算知识多样性。具体而言,参考赫芬达尔指数的思路,通过计算单个专利内 IPC 号信息的差异度来衡量其多样性水平。IPC 号差异越大,表明该专利涵盖的知识领域越广,企业的知识储备也越多元。计算公式为:
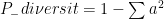
公式 5
其中, a 表示 IPC 号中各大组分类所占比重。然后,根据“企业一年份”将企业单个专利的知识多样性信息加总到企业层面。由于企业专利分布不均且存在极端值问题,本文使用中位数方法最终得到企业知识多样性指标( K _ diversity )。 K _ diversity 数值越大,代表企业在各大组层面 IPC 号之间存在的差异越明显,也就是说企业为获得该发明专利所使用的知识越丰富。另一方面,本文参考ChatterjeeandBlocher(1992)的做法,将 IPC 号主要依据小类进行分类,并应用熵值法衡量知识多样性,变量名设置为 K _ diversity2 。具体计算方法如下:
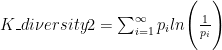
公式6
其中,对于一个拥有 m 个不同小类等级发明专利的企业而言, Pi 是小类等级发明专利i 中技术领域的专利比例。
(4)控制变量
本文在分析中控制可能对企业创新产生显著影响的企业层面因素,具体包括:企业规模(Size),以企业总资产的自然对数表示;企业年龄(Age),通过从企业成立至研究年份的时间跨度的自然对数来衡量;盈利能力(ROA),采用净利润与总资产之比来衡量;资产负债率(Leverage),以总负债与总资产之比表示;营业收入增长率(Growth),以每年年末企业收入变化与上一期营业收入的比率来衡量:研发强度(Rdintensity),以研发投入占营业收入的比例表示。
四、实证分析
1. 基准回归
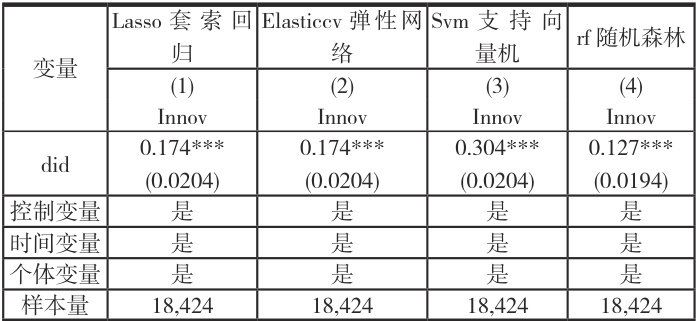
国家数字经济创新发展试验区政策对城市绿色技术创新的影响效应回归结果如表 1 所示。为了保证回归结果的稳健性,本文分别选择套索回归、弹性网络、支持向量机和随机森林等算法进行回归。具体回归结果如表 1 的第(1)、(2)(3)(4)列所示。结果表明,无论是选用哪种算法,政策的回归系数至少在 1% 的水平上正向显著,即国家数字经济创新发展试验区政策确实能够显著促进城市绿色技术创新水平的提升,假说 1 得到验证。为了方便起见,后文分析中均选择可解释性较强的套索回归算法进行计算。
表1 基于部分线性模型的基准回归结果
2. 稳健性检验
(1) 平行趋势和动态效应检验
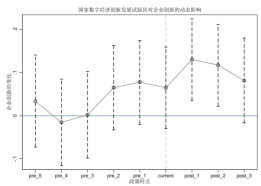
本文利用事件分析法,检验政策前的平行趋势和政策后的动态效应。本文采用基于异质性处置效应的平行趋势检验方法。检验结果如图 2 平行趋势与动态效应检验结果所示。可以看出,在获批为国家数字经济创新发展试验区之前,回归系数均未通过显著性检验;在政策实施当年及以后,回归系数开始显著为正,表明双重差分模型的估计结果具有一定的合理性。
图2 平行趋势与动态效应检验结果
(2) 安慰剂检验
在本文的实证分析中,本研究采用了安慰剂检验(PlaceboTest)来验证国家数字经济创新发展试验区对企业创新量的影响是否真实可靠。为了排除遗漏变量和模型设定的干扰,通过随机化干预变量,重复进行 500 次回归,生成了 500 个回归系数。通过比较随机回归的结果和真实回归系数,本研究可以判断观察到的政策效应是否存在偶然性。
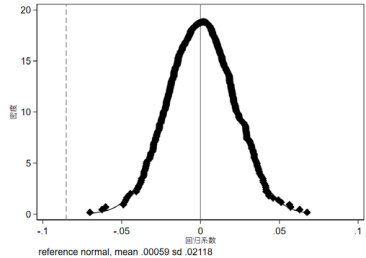
图 3 安慰剂检验 - 回归系数概率密度图具体呈现为随机样本选取后进行的 500 次回归系数概率密度分布图。图中,虚线标记了本文实际回归系数的数值。从理论层面分析,这 500 次回归的系数预期不具备显著性,意味着随机抽取的样本不应显现出减少企业创新的效果。观察发现,大多数系数在零点两侧分布均匀,且 500 次回归所得系数的平均值接近零,与实际回归系数形成显著对比。这有力地证明了国家数字经济创新发展试验区的企业创新成效并非偶然现象,也未受到未观测因素的干扰。
图 3 安慰剂检验 - 回归系数概率密度图
五、异质性分析
1. 地区异质性
企业数字创新的推进,是一项系统性工程,其成效不仅取决于宏观政策的引导,也依赖于微观基础的支撑。一方面,以国家数字经济创新发展试验区政策为代表的顶层设计,为创新活动提供了方向指引与制度保障。另一方面,数字基础设施的完善程度,以及企业整合运用现有资源的内在意愿与实际能力,共同构成了创新实践的基础性条件。当数字基础坚实、企业能动性充足时,数字创新的壁垒将随之降低,进而强化城市数智化转型对企业创新的驱动效应。此外,技能、人才、知识与经验等要素的积累,是企业数字能力得以培育和提升的核心所在。鉴于我国东、中、西部三大区域在数字基建水平、科技创新能力、经济基础实力及资源配置效率等方面存在显著的不均衡性,本研究依据地域标准,将总样本划分为东部、中部与西部三个子样本,以进行后续的差异化分析。
表 2 地区异质性
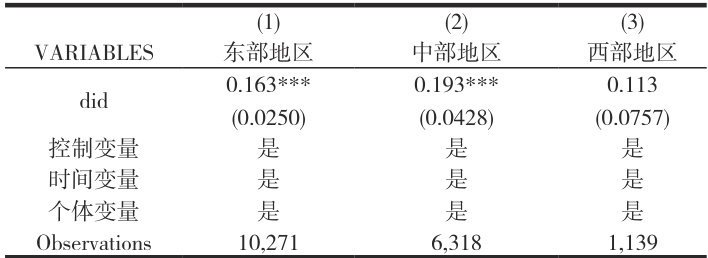
表 2 的回归结果显示,国家数字经济创新发展试验区政策对企业数字创新的推动作用在东部和中部地区显著,而在西部地区不显著。这主要源于区域间的系统性差异:东部地区经济基础雄厚、创新要素集聚,政策作为“催化剂”能迅速转化为创新产出;中部地区正处于产业升级关键期,政策起到了关键的“助推器”作用;而西部地区则因产业结构传统、人才资本匮乏及基础设施落后,面临较高的“数字门槛”,导致政策传导受阻,效应不彰。
2. 行业异质性
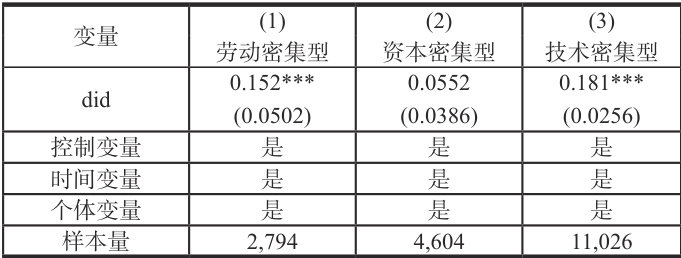
国家数字经济创新发展试验区政策在不同应用场景中有其特定的适用性,在不同行业中,国家数字经济创新发展试验区政策对企业创新的影响也可能有所不同 [3]。本文根据中国证券监督管理委员会 2012年发布的《上市公司行业分类指引(2012 年修订)》进行行业分类,并参考黄亮雄等(2023)的分类方法,将上市企业所属行业分为劳动密集型、资本密集型和技术密集型三类。研究证实,国家数字经济创新发展试验区政策对企业创新的促进作用主要集中在劳动密集型和技术密集型行业。对于劳动密集型行业,数字化工具能优化其庞大的操作流程,通过流程再造实现管理创新;而对于技术密集型行业,政策提供的新型基础设施和创新生态则直接强化了其研发能力,加速了技术迭代。简言之,劳动密集型行业通过数字化“优化存量”提升效率,而技术密集型行业则通过数字化“创造增量”加速创新。
表 3 行业异质性
六、机制分析
根据前文理论分析发现,国家数字经济创新发展试验区政策可能通过打破组织惯例、提高知识多样性等路径影响企业创新水平。在此基础上,本研究采纳中介效应模型,深入探讨国家数字经济创新发展试验区政策对推动企业创新的作用机制。
1. 机制I:组织惯例
表 4 第(1)列结果显示,国家数字经济创新发展试验区政策可以显著打破企业组织惯例。现有研究指出,打破组织惯例能够有效降低创新阻力,增强企业对外部环境变化的响应能力,从而为企业创新提供更有利的条件。因此,本文的实证结果支持假说 H2.1,说明国家数字经济创新发展试验区政策有助于企业打破组织惯例,进而提升创新水平。
2. 机制Ⅱ:知识多样性
表 4 第(2)、(3)列回归结果表明,国家数字经济创新发展试验区政策显著提高知识多样性。知识多样性的提升意味着企业在技术布局上更加多元化,这为其跨越技术壁垒、实现多领域创新奠定基础。已有研究证实,知识多样性通过增加知识广度,提高了知识组合的可能性,从而对企业创新产生积极影响(BonnerandWalker,2004;刘岩等,2015)。因此,该实证结果验证了假说 H2.2,表明国家数字经济创新发展试验区政策通过提高知识多样性促进企业创新。
表4 机制分析
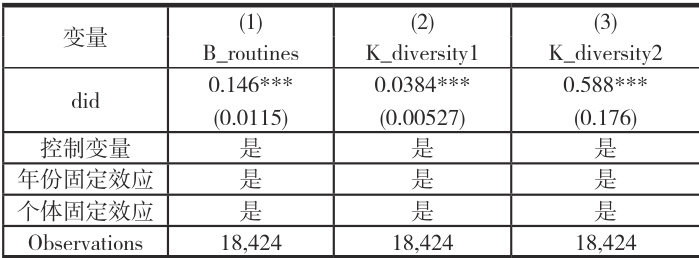
综上表 4 回归结果显示,列(1)中双重差分变量(did)的系数为 0.146,且在 1% 的统计水平上显著,这表明国家数字经济创新发展试验区政策的实施,能够有效推动企业打破固有的组织惯例。其内在原因在于,试验区政策通过提供数字基础设施、技术补贴和创新激励,迫使企业摆脱传统的经营模式与路径依赖,为适应数字经济时代的要求而进行组织重构。同时,试验区营造的创新环境降低了企业变革的制度成本与风险,鼓励管理层突破思维定式,从而为创新活动扫清了组织层面的障碍,这构成了政策促进企业创新的第一条重要传导路径。
从知识多样性维度来看,列(2)与列(3)中did 的系数分别为0.0384和 0.588,且均在 1% 水平上显著,证实了试验区政策对企业知识多样性的提升作用。这一效应主要源于政策驱动下的人才集聚与知识溢出:试验区通过优厚的人才政策吸引高端数字人才流入,带来了多元化的专业背景与知识结构;同时,政策鼓励的产学研合作与产业集群建设,促进了企业间、企业与科研机构间的知识交流与技术扩散。这种知识多样性的增加,为企业创新提供了更丰富的思想源泉和技术储备,激发了创意碰撞,降低了创新风险,从而形成了政策推动企业创新的第二条关键机制。
即本文H2:国家数字经济创新发展试验区政策通过打破组织惯例、提高知识多样性对企业创新产生间接影响得到有效验证。
七、结论与政策建议
国家数字经济创新发展试验区如何推动企业创新,是新质生产力形成和发展的关键问题。深入探讨这一问题能够为当前的创新管理实践提供解决方案,从而推动中国经济高质量发展。本文采用 2012—2022 年中国 A 股上市企业数据,使用双重机器学习(DDML)方法,检验国家数字经济创新发展试验区对企业创新的影响。研究发现: ① 国家数字经济创新发展试验区能显著促进企业创新,且这一结论在经过平行趋势检验、安慰剂检验稳健性检验后依然成立。②国家数字经济创新发展试验区对企业创新的促进作用通过打破组织惯例、增加知识多样性两个渠道得以实现。 ③ 异质性分析表明,国家数字经济创新发展试验区在东部地区和中部地区显著为正,在西部地区不显著;同时,在劳动密集型和技术密集型企业中的解释力度更强,在资本密集型企业稍弱。因此,本文提出如下政策建议:
基于研究发现,提出以下政策建议:
(1) 实施区域差异化战略,推动协调发展。鉴于政策在东、中部效应显著而在西部受阻,应采取分类施策。对东、中部地区,应继续深化政策支持,鼓励其发挥引领作用并向西部输出成熟技术与模式。对西部地区,政策重心应转向“筑基”,即大力投资数字基础设施建设,出台人才引进与培育政策,优化营商环境,为其未来承接创新红利扫清障碍。
(2) 推行产业精准化扶持,提升政策效能。针对不同类型企业的响应差异,应摒弃“一刀切”模式。对劳动密集型企业,应聚焦其数字
化转型痛点,提供普惠性的“上云用数赋智”服务与技能培训,助其降本增效。对技术密集型企业,应强化其创新“引擎”作用,通过专项基金、知识产权保护等手段,支持其进行前沿技术攻关与颠覆性创新。同时,需探索有效机制,引导资本密集型企业将资源优势转化为数字化研发与应用的创新优势。
(3) 聚焦关键作用机制,构建创新驱动生态。围绕“打破组织惯例”和“增加知识多样性”两大核心渠道精准发力。一方面,鼓励企业设立首席数据官(CDO)等职位,建立数据驱动的决策文化,破除内部创新壁垒。另一方面,强化试验区的平台功能,构建“政产学研用”协同创新网络,通过跨行业交流、人才柔性流动等方式,促进知识碰撞与跨界融合,为企业注入源源不断的创新活力。
(4) 优化评估与推广机制,放大示范效应。建立动态评估与反馈体系,定期量化政策效果,深入分析其对不同企业的作用机制,并及时调整优化。同时,系统总结各试验区的成功经验与典型模式,形成可复制、可推广的“中国方案”,最大化政策的示范引领效应,为实现经济高质量发展提供坚实动力。
参考文献
[1] 姜俊聪 . 数字经济对企业创新投入的影响与机制检验以 广 州 市 为 例 [J]. 中 国 集 体 经 济,2024,(32):29-32.DOI:10.20187/j.cnki.cn/11-3946/f.2024.32.043.
[2] 朱嘉禾 . 数字经济创新发展、研发投入与企业投资效率——来自国家数字经济创新发展试验区的数据 [J]. 国际商务财会,2024,(22): 3-10+15
[3] 李玉花 , 林雨昕 , 李丹丹 . 人工智能技术应用如何影响企业创新 [J]. 中国工业经济 ,2024,(10):155-173.DOI:10.19581/j.cnki.ciejournal.2024.10.009.
[4] 张倩肖 , 段义学 . 数字赋能、产业链整合与全要素生产 率 [J]. 经 济 管 理 ,2023,45(04):5-21.DOI:10.19616/j.cnki.bmj.2023.04.001.
[5] 吕一博 , 韩少杰 , 苏敬勤 . 企业组织惯性的表现架构 :来 源、 维 度 与 显 现 路 径 [J]. 中 国 工 业 经 济 ,2016,(10):144-160.DOI:10.19581/j.cnki.ciejournal.2016.10.010.
[6]Benner,M.J.,andM.L.Tushman.Exploitation,Exploration,an dProcessManagement:TheProductivityDilemmaRevisited[J].Academy ofManagementReview,2003,28(2):238-256.
[7]Gruber,M.,D.Harhoff,andK.Hoisl.KnowledgeRecombinationA crossTechnologicalBoundaries:Scientistsvs.Engineers_JJ.Manage mentScience,2013,59(4):837-851
[8]ChernozhukovV.,ChetverikovD.,DemirerM.,DufloE.,HansenC.,NeweyW.,RobinsJ.,2018,Double/DebiasedmachineLearningforTreatmentandStructuralParameters[J],EconometricsJournal,21(1),C1~C68.
基金课题:本文受到天津理工大学校级大学生创新创业训练计划项目资助,项目编号:202510060069。

 京公网安备 11011302003690号
京公网安备 11011302003690号


