



- 收藏
- 加入书签

关于随机数据的分布拟合探究
 打开文本图片集
打开文本图片集

概述
研究背景
在日常生活中,数据扮演着重要的角色。如手机淘宝的“猜你喜欢”功能、支付宝的芝麻信用分、车险和寿险的价格核定与投保费等,都是经过数据加工分析的结果。在进行科学实验时,需要从大量杂乱无序的随机数据中提取信息,以理解客观存在的内在规律,认清客观存在之间的联系,并做出预期判断。在国家和政府层面,数字化进程也越发受到重视。例如健康码的使用很好地利用了数据,有效区分了不同风险级别的持有者,对疫情的管控和经济的复苏起到了重要作用。
研究意义
在科学实验和研究中,数据的重要性不言而喻。分析实验所得的随机数据的数学方法多种多样,比如回归分析法和方差分析法。回归分析法更加偏向预测性,考察实验结果和实验条件间的关系,以达到预测性分析的目的;方差分析法则研究各个因子的变化对实验最终结果的贡献度大小,以谋求更高效的实验外部因素等。该文将利用概率与统计的基本原理,对收集到的随机数据进行分析,通过EXCEL画出频数直方图,再考虑随机数据的现实背景,综合这两点来对随机数据的分布类型做出假设。下一步将验证原始数据是否可以用这个分布类进行拟合,一般使用皮尔逊卡方检验或者Kolmogorov-Smirnov检验。确定了拟合的分布类以后将进行参数估计,随机数据的分布拟合研究就完成了。研究随机数据的分布拟合方法是一种非常有效的数据理解方法,因此研究随机数据的分布拟合具有重要的意义。
研究现状
1.随机数据的来源
笔者通过互联网途径收集到了三组通过实验或者观察得到的不同分布类的随机数据。
第一组数据是关于法国红葡萄酒中硫酸盐浓度水平的随机数据。
第二组数据就是2016/2017赛季英超联赛每一场比赛客场球队的进球颗数的随机数据。将数据进行处理,将其变成客场进球数i个的比赛有xi场这样的一一对应的一组向量。
第三组数据就是医院任一患者所需接受的医疗服务的时间长短的频数。对数据进行整合,最后得到患者所需接受医疗服务的时间落在不同时间区间内的频数。
2.分析随机数据
数据分析的方法是通用的。首先,需要下载所需的随机数据,然后将其输入到EXCEL中,并选择保存文件格式为“CSV(逗号分隔)”以便后续使用R调用数据。接下来,将数据输入到R中,通常使用read.csv()函数打开EXCEL文件,并使用as.vector()函数选择所需的行列数据。同时,也需要用字母来定义这些数据集。在分析随机数据时,关键步骤之一是将其转化为频数直方图。这种做法是有理论依据的,根据格里汶科定理,当样本量很大时,样本经验分布函数将依概率收敛到总体分布函数。具体操作上,可以利用EXCEL自带的作图功能,将一系列随机数据处理成频数直方图。
常见的三种指数分布
指数分布的定义
若随机变量X的概率密度函数为p(x)=λe-λx,x≥0,则称X~Exp(λ)服从指数分布,记作X,其中λ>0。
指数分布的性质及应用
随机变量的分布可分为连续概率分布和离散概率分布。指数分布是连续型分布中最重要的之一。在描述两个独立随机事件之间的时间差时,常常使用指数分布公式。比如两个不同旅客进入飞机场候机厅的时间间隔、微博最新热搜发布的时间间隔等。由于指数分布是不对称的,因此许多关于“寿命”的分布可以通过指数分布来表示,比如移动电脑的使用寿命分布。指数分布是可靠度和排队理论研究中最常用的分布方式之一。
正态分布
1.正态分布的定理
2.正态分布的性质及应用
正态分布具有两头低、中间高的特点,并呈现左右对称的“钟形”。正态分布与常态分布是同一概念。数学家拉普拉斯在高斯的研究基础上对正态分布进行了完善,丰富了其性质。在数学、物理、工程等领域,正态分布都是重要的概率分布,对统计学和其他领域也产生了巨大影响。正态分布被广泛应用于连续随机变量的概率分布中,并在自然界、社会科学、教育心理等领域发挥重要作用。例如,社会中劳动者能力的分布、学校学生成绩的分布等都可以用正态分布来描述。
泊松分布
1.泊松分布的定理
2.泊松分布的性质及应用
当描述单位时间内的发生随机时间的次数时候常常考虑到使用泊松分布,单位时间(或单位面积、单位产品等)上的计数过程都和泊松分布联系紧密。泊松分布的参数λ是描述泊松分布强度的参数,他的意义是单位时间(或单位面积)内随机事件的平均发生次数。泊松分布的适用领域很宽广,常常用于描述一天内来到飞机场火车站的旅客人数、单位时间内地球大气层受宇宙粒子辐射的次数等。泊松分布也常常在大量小概率发生事件的背景下代替二项分布,方便计算。
参数估计方法
极大似然估计
极大似然估计是利用已知样本事件结果来推断未知参数值的方法。在实际计算中,引入似然函数的概念,其实质是样本联合分布函数。为了方便求解似然函数的最大值,通常采用对似然函数取对数,然后求导数或偏导数的方法,最终得出未知参数的极大似然估计值(MLE)。
极大似然估计不仅是概率理论和统计学之间的联系,也是一种参数估计的方式。它通常应用于已知随机数据样本服从某一目标概率分布,但未知分布中的参数值的情况。参数估计的基本步骤是进行多次实验,记录实验结果,得到多组样本数据,然后利用这些数据推断未知参数的最大概率取值。极大似然估计法的核心思想是,已知一个参数可以使样本出现的概率最大化,因此选择这个参数作为真实估计值,而不考虑其他较低概率的参数取值。
极大似然估计法具有显著的特点。首先,采用极大似然估计法不仅直观易懂,而且简单易行。其次,极大似然估计值具有渐进收敛性,当样本值足够大时,所得估计值非常准确。最后,极大似然估计具有良好的拟合性,若假设模型正确,通常能得到良好的结果;但若假设模型存在较大偏差,将导致估计结果较差。
原理与发展过程
极大似然估计是统计学中著名的概率事件原理,其核心思想是在独立简单随机试验中,当某一结果的概率小于一定下界时,就可以认为在独立简单试验中不会得到这样的结果。
极大似然估计方法最早由德国数学家高斯于1821年提出,后由英国统计学家费希尔于1922年再次提出并证明了其性质,使得该方法得到广泛应用。极大似然估计的命名也是由费希尔提出的。然而,人们后来发现在某些分布中存在多余的参数或者截尾、缺失的情况下,极大似然估计可能变得困难。为解决这一问题,登普斯特等人于1977年首次提出了em算法,该算法将极大似然估计分为两个阶段:首先求期望,剔除多余信息和数据;然后求极值,进行多次迭代直至收敛,从而得到更精确的极大似然估计。
如何使用R求极大似然估计
在R中,有两种方法可以用来求得概率分布中未知参数的极大似然估计值。第一种方法是将分布函数的对数似然函数输入到R中,然后将未知参数视为未知数,将函数转化为方程,最后求得对数似然方程的解,即为参数的极大似然估计值。这种方法的优点在于可以适用于任何复杂的分布函数,例如一些较难求解的数似然方程,如Cauchy分布等。然而,这种方法的缺点在于计算量较大,且得到的极大似然估计值为对数似然方程的数值解,精确度不高。
第二种方法是通过理论推导,首先求取样本联合分布函数,然后对样本联合分布函数取对数,得到似然函数。为了得到似然函数的最大值,需要对似然函数进行求导或偏导,得到导数方程或偏导数方程,最终得到的根即为位置参数的极大似然估计的解析解。这种方法的优势在于R中的语句简单明了,计算方便,且求得的极大似然估计值精度很高。然而,这种方法的缺点在于对于一些复杂的分布类,较难求得最后的解析解。
假设检验方法
假设检验
假设检验,又称统计假设检验,是一种专门用来确定和评估样本与样品、样品和总体差异之间是由于抽样误差导致的或者是因本质差异所导致的差别而直接造成的一种统计学推断技术。显著性的检验是统计假设在检验中最常见和普遍采用的一种检验方法,也可以说是一种最基本的统计推断表现形式。假设检验就是先做出一个原假设和一个与原假设相反的备择假设,然后在原假设成立的条件下,根据给定的置信度求得检验统计量的置信区间,比较样本观测值,如果样本观测值落在置信区间内,就接受原假设,否则拒绝。
1.原理与基本思想
假设检验的基本思路是基于小概率事件的原理,其中统计推断的方法可以被视为一种带有特定概率属性的逆证法。小概率观念指的是在一次实验中,小概率的事件几乎不会发生。反证法的思想是先提出一个检验假设,然后利用适当的统计分析方法和小概率的原理来确定这个假设的正确性和可靠度。一般情况下,认为事件可能发生的概率小于0.1、0.05或0.01等,即被称为“小概率事件”。
2.假设检验的方法
假设检验大体上分成两类,一类是参数检验,主要是针对正态分布,根据单个总体或者多个总体和在检验一个参数时另一个参数值是否已知来选取不同的检验统计量,使用不同的检验统计量进行单边或者双边检验。还有一类是非参数检验,非参数检验的方法众多,比较常见的就是皮尔逊卡方检验和kolmogorov-smirnov检验是两种比较常用的检验方法。非参数检验的原理就是把每一个理论值和实际数据之间偏离量综合成一个指标,用这个指标来衡量分布类的拟合优度。
如何使用R进行假设检验
使用R进行参数检验:在单个总体时,检验均值μ的时候会使用P_value()函数。程序的输出内容包含均值,自由度,检验统计量和P值。检验方差σ2的时候会使用var.onetest()函数。使用R进行非参数检验:使用皮尔逊卡方检验时,使用chisq.test()函数,使用kolmogorov-smirnov检验时,使用ks.test()函数。
如何使用R求极大似然估计
使用R求得概率分布中未知参数的极大似然估计值的方法有两种。第一种是在R里面输入分布函数的对数似然函数,然后把未知参数当作未知数,将函数转化成为方程,最后求得对数似然方程的算数解,参数的极大似然估计值就是这个根。这种方法的好处在于无论什么多么复杂的分布函数都可以这样一步一步的做求得极大似然估计值,像有一些较难求解的数似然方程,例如Cauchy分布等就适合用这种方法。他的缺点就是计算量较大,求得的极大似然估计是对数似然方程的数值解,精确度不是很高。
第二种方法就是通过理论推导,先是对求样本联合分布函数,再对样本联合分布函数取对数,得到似然函数。为了得到似然函数的最大值,就要对似然函数求导数或者偏导数,得到导数方程或者偏导数方程,最后得到的根就是位置参数的极大似然估计的解析解。这种方法的优势在于R中的语句简单明了,计算方便,求得的极大似然估计值精度很高。缺点就是有一些复杂的分布类的较难求得最后的解析解。
葡萄酒中硫酸盐含量的分布拟合研究总体思路
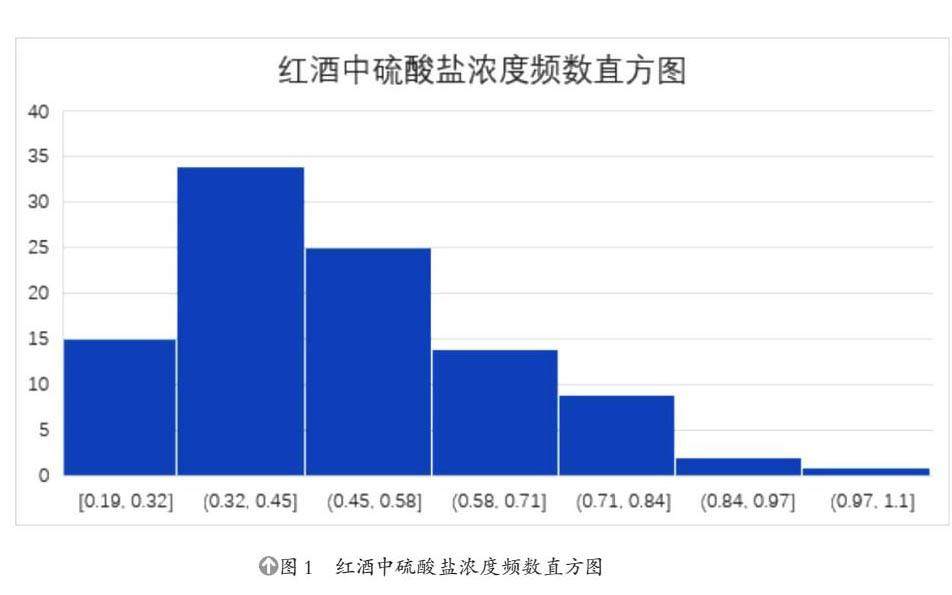
本次研究首先进行的是猜测分布类,一般途径有根据频率直方图形状和考虑各个分布类的应用领域和数据的背景之间的联系紧密程度(见图1)。为了证实之前对分布类的假设是正确的,需要进行非参数检验,本次研究使用了卡方检验,验证样本数据是否服从此分布类。如果卡方检验的p值大于0.05,就接受此分布,反之拒绝。确定了分布类,接下来就要进行参数估计,本次研究使用了极大似然估计。完成了估计以后,数据的拟合分布就完整了,最后为了研究的严谨性,还需要进行参数检验,验证以极大似然估计值为参数是否合理,本次研究选用假设检验法。
猜测分布类
本文首先使用EXCEL的自带画图功能,做出频率直方图,观察频率直方图的形状发现,符合正态分布的“呈钟形,两头低,中间高,左右对称因其曲线呈钟形”的特点,又考虑到正态分布描述自然界发生的一些现象,而本次估计的数据也是酿酒过程中产生的硫酸盐浓度也是自然过程,考虑到这两点,故本次拟合研究初步假设使用正态分布进行拟合。
皮尔逊卡方检验
假设原数据服从正态分布,使用R软件进行非参数检验的卡方检验。
原假设:随机数据服从正态分布。VS 备择假设:随机数据不服从正态分布。
卡方检验得到,检验的p值等于0.6439,远大于0.05。因此无法拒绝原假设(原数据服从正态分布),得到结论:原数据服从正态分布。
拟合效果评价
就非参数检验的结果而言,P值是所得数据与原始数据的拟合优度。 P值越大,分布类的拟合效果越好,本次研究中P值等于0.6439,是一个较高水平的拟合优度了,对于给定的显著性水平0.05,正态分布的拟合效果是远超预期的。就参数检验而言,P值是随机数据大于或者小于某个给定值的概率。P值越大,参数估计的贴合程度就越好,本次研究中P值分别等于0.7414和0.9054305,都位于较高的水平,对于给定的显著性水平0.05,参数估计0.4956061,0.0281324显然是可信的。
综上所述,本次研究的对象:葡萄酒中硫酸盐浓度的随机数据是服从N(0.4956061,0.0281324)的。
结论
本次研究得到的拟合结果在现实生活中也有一定的应用价值。众所周知,品味葡萄酒中重要的一环就是醒酒,醒酒的目的有一部分是为了让酒液与空气充分接触,以此来减轻葡萄酒中硫酸盐令人不适的气味,以达到更好的体验。如果醒酒的时间过短,硫酸盐的气味过于猛烈,则会掩盖住葡萄酒的醇香的本味,影响品酒体验;如果醒酒的时间过长,虽然硫酸盐的气味散尽,可是同时酒液也会与空气氧化,导致风味的衰减。因此,葡萄酒厂家会针对每款葡萄酒中硫酸盐的浓度,测算出一个推荐的醒酒时长,以此保证酒的风味能最大程度的保留。本次研究的最终拟合结果给酒厂测算推荐醒酒时间提供强力的理论基础。

 京公网安备 11011302003690号
京公网安备 11011302003690号


