



- 收藏
- 加入书签

基于国产异构加速平台和FVCOM的中国东部邻海及其周边水域的数值模拟
 打开文本图片集
打开文本图片集
摘要:海洋数值模拟计算是人们对海洋环境开展研究的方法之一,其通过建立数学模型模拟真实物理场景中的物体运动,实现宏观上的海洋环境预报和推演。FVCOM正是一种基于非结构化三角网格和有限体积法的海洋数值模拟计算模式,目前已被广泛应用于近岸海洋研究中。除了数学模型之外,承接计算任务的计算平台也直接影响着最终的模拟结果。当前,x86架构的CPU在性能提升上遭遇瓶颈,难以在控制能耗的前提下得到进一步发展,基于该硬件的传统高性能计算平台也受到影响。而随着科研的深入,模拟计算在计算总量和计算精度上又提出了更高的需求,传统平台已难以满足。为解决这一问题,多种新架构被应用于平台设计中,CPU-GPU架构是其中之一。此类平台的设计中,保留了x86架构CPU用于处理逻辑任务,同时新增GPU架构的硬件用于处理计算任务。在保留系统通用性的同时,利用GPU的高并发性提升计算能力。国产异构平台基于CPU-GPU架构,由海光c86架构中央处理器和海光DCU加速卡组成,兼容x86架构系统。本研究在国产异构平台中成功编译、运行面向CPU计算的FVCOM程序;通过修改FVCOM和其依赖软件的源码,实现了在计算过程中对DCU加速卡的调用,在特定场景下缩短了计算耗时,达到了加速计算的目的。
关键词:国产异构加速平台;CPU-GPU架构;DCU加速卡;FVCOM
当前,高性能计算被广泛应用于各类科研领域中,并已建立了众多不同规模的高性能计算平台。这些平台大多以x86架构CPU作为主要计算硬件,并搭载同架构的操作系统。在经过长时间的发展后,基于该架构的软件生态环境已成为高性能计算平台中不可或缺的一部分。近些年,伴随着摩尔定律逐渐失效,单个x86架构CPU的计算性能不再快速提升。这导致了基于此架构的计算平台在控制能耗的前提下很难进一步提高计算能力。
随着科学研究的不断深入,科研人员的计算需求日益增加,在计算总量、精度和效能上都对计算平台提出了更高的要求。基于上述原因,传统面向x86架构CPU计算的平台显然难以满足这种使用需求。
为解决这一问题,一系列新的硬件架构应运而生。其中一部分选择采用全新的硬件架构,将x86架构完全抛弃。如在2020年6月的“全球超级计算机TOP500”榜单中取得第一名的日本“富岳(Fugaku)”超级计算机采用了ARM架构;在同期榜单中取得第四名的我国“神威太湖之光”采用了国产自研众核架构。虽然此类平台性能十分强劲,但是由于采用全新的硬件架构,对现有的软件生态环境并不友好。并且由于配套的开发环境仍在发展,移植工作存在较大难度。
另一部分选择采用CPU-GPU架构。此类平台仍然使用x86架构的CPU和操作系统,并在此基础上引入GPU或加速卡作为计算硬件。在使用过程中,CPU不再作为主要计算硬件,仅完成逻辑任务,将计算任务交由GPU或加速卡完成。这种架构很好地利用了计算设备的高并发性,极大程度地提高了计算性能。同时,平台仍然基于x86架构,对现有软件保留了一定的兼容性,开发者仅需对计算部分的代码进行修改即可实现计算加速功能,而无须从底层重新开发,同时也无须考虑其依赖程序的可运行性。
国产异构加速平台即采用了CPU-GPU架构,由基于c86架构的国产海光处理器和国产海光DCU加速卡组成。平台使用x86架构操作系统并兼容同架构软件。
本次研究皆在实现面向CPU计算的FVCOM在国产异构加速平台上的编译、运行,并完成正确性验证和效能统计;通过对FVCOM和依赖软件的源码进行修改、完善,在不改变FVCOM程序结构的情况下使其能调用DCU资源,并验证其加速效能。
一、研究背景
(一)FVCOM
FVCOM(The Unstructured Grid Finite Volume Community Ocean Model)是一种基于非结构化三角网格和有限体积法的海洋数值模拟计算模式,由美国麻省大学和美国伍兹霍尔海洋研究所联合开发。其对应的计算软件基于Fortran语言编写,主要使用在面向CPU计算的平台上。
(二)PETSc和HYPRE
PETSc(Portable,Extensible Toolkit for Scientific Computation)是一套用于处理偏微分方程组及相关问题的系列软件,包含线性和非线性的并行求解器、ODE积分器等,可被用于由C、C++、Fortran和Python语言编写的程序中。当前版本(即3.17.1)的PETSc实现了基于CUDA、OpenCL和Kokkos的全功能加速计算,以及基于ROCm的向量加速计算。
HYPRE是一套由美国劳伦斯·利弗莫尔国家实验室开发的软件包,可为PETSc的求解器提供基于代数多重网格(Algebraic Multigrid,AMG)方法的预处理器。当前版本(即2.25.0)的HYPRE实现了基于ROCm和CUDA的全功能加速计算。
FVCOM的半隐式计算模块使用了PETSc的KSP求解器来求解方程组,该求解器则依赖于HYPRE提供的预处理器。
(三)ROCm和HIP
ROCm是由AMD推出的一个开源高性能异构计算平台,为AMD的硬件产品提供了完整的开发和运行环境,包括驱动、编译器、运行库、数学库、性能分析工具、调试工具等。与NVIDIA的同类产品CUDA相比,ROCm为开源软件,拥有更好的灵活性;但由于其推出时间较晚,软件生态环境的丰富性相对较差。相信随着时间的推移,这一问题将得到解决。
HIP(Heterogeneous-Compute Interface for Portability)是一种ROCm平台使用的编程模型,其在使用方法、函数构建、函数调用等方面十分接近CUDA,这也使较为简单的CUDA应用能快速移植到ROCm平台上。HIP可根据硬件平台的不同自动调用ROCm和CUDA的接口。
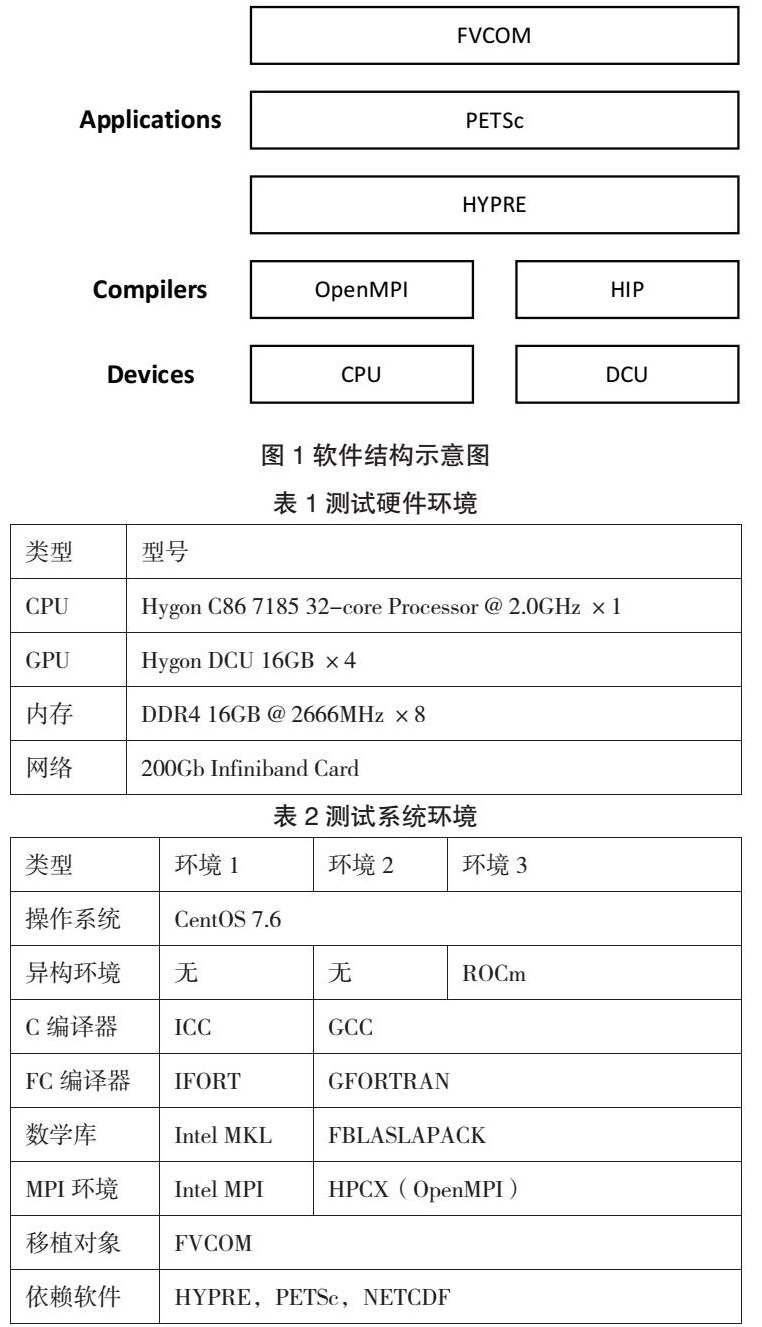
二、硬件环境与系统环境
本研究使用国产异构计算平台编译、运行FVCOM,相关的软硬件结构如图1所示;平台的硬件、系统描述如表1、表2所示;FVCOM较重要的编译参数如表3所示。
三、加速计算的实现
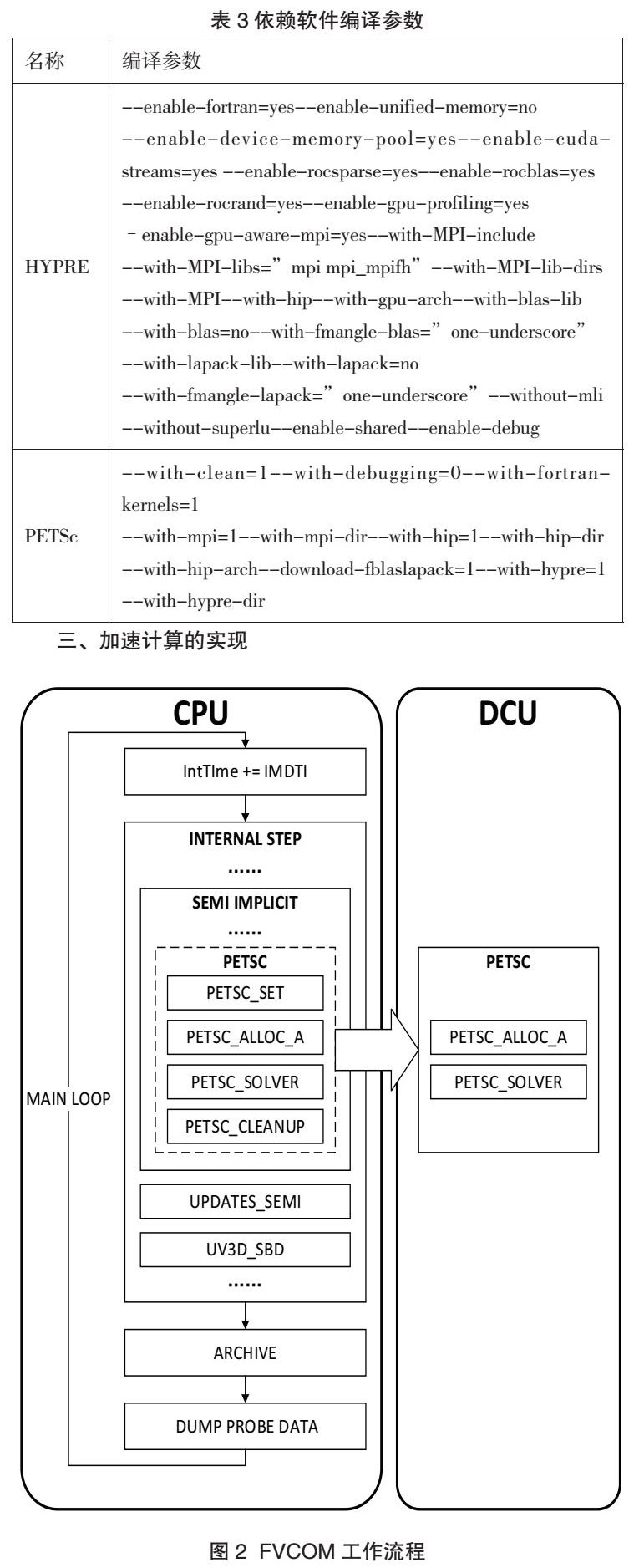
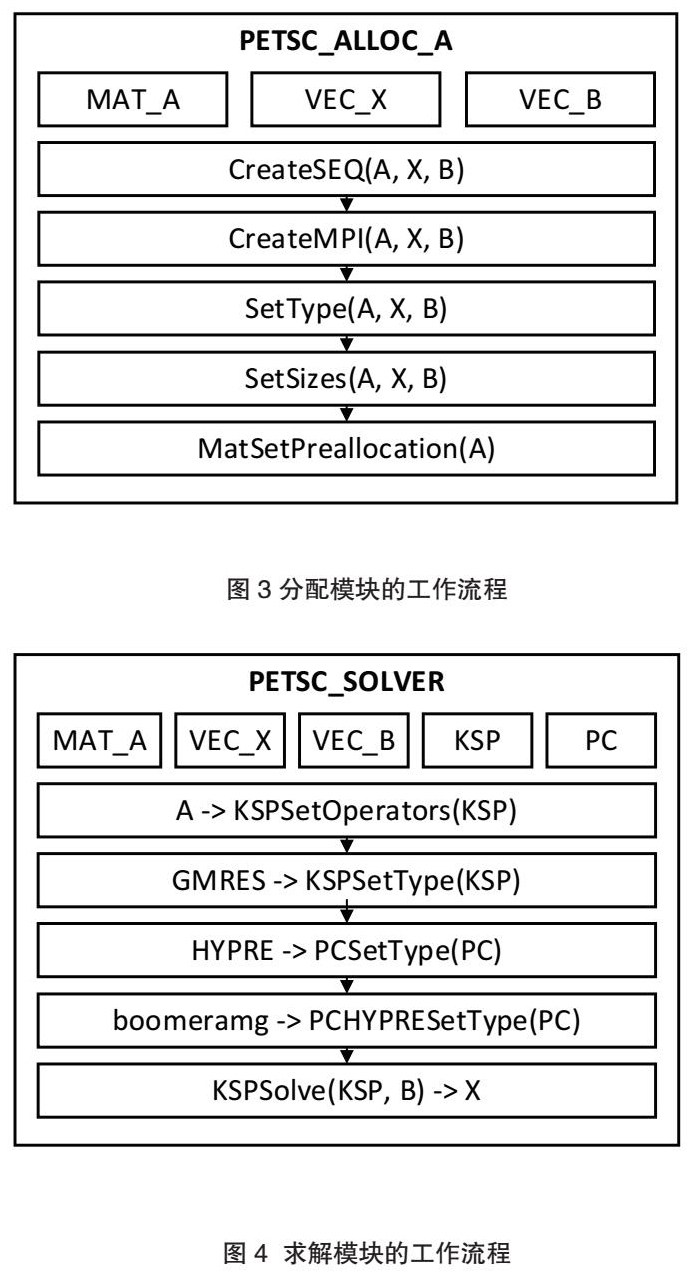
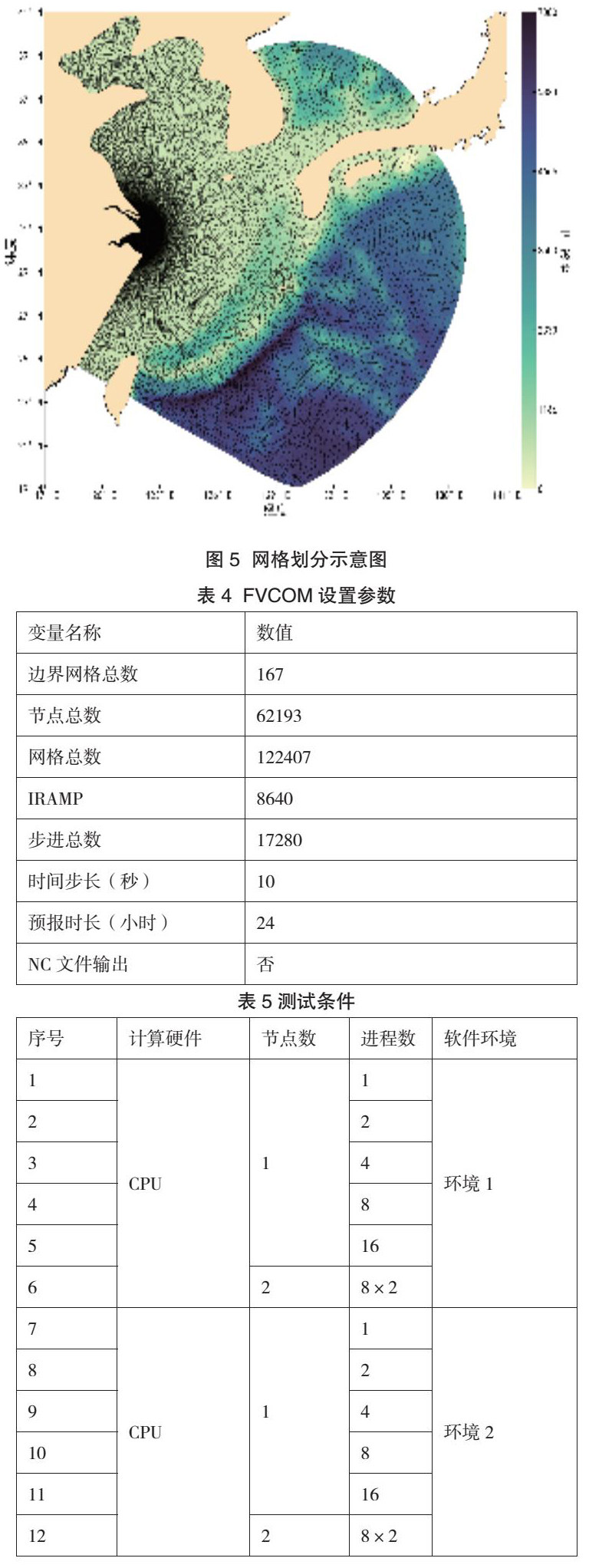
FVCOM的半隐式计算(Semi Implicit)模块使用PETSc中基于广义最小残差法(GMRES)的稀疏矩阵求解器(KSP)来处理方程组问题,该求解器又进一步使用HYPRE中基于BoomerAMG方法的预处理器(PC)。其整体的工作流程如图2所示。
本研究以面向CPU计算的FVCOM和版本为3.17.1的PETSc为基础,对这两个程序进行了如下修改:(1)修改FVCOM的半隐式计算模块,令其适配新版本的PETSc;(2)修改PETSc的头文件,完善其对Fortran语言的支持;(3)修改PETSc的MAT、PC等模块,完善其对ROCm平台的支持。
通过上述修改和完善,在保留FVCOM原有编程语言、编程模型和程序结构的情况下,较为成功地将异构加速功能引入了FVCOM的方程组求解过程中,从而缩短了其单步计算的用时,最终实现了整体的计算加速。
四、性能测试与分析
计算耗时是评判计算效能的指标之一。本研究使用FVCOM对东海及其周边海域的水位数据进行了时长为24小时的模拟计算。基于相同的设置和输入数据,以及不同的软硬件环境,得到了多组计算结果,并统计了各组的计算耗时。通过对比,得到计算耗时上的差异,并找出其影响因素。
测试使用的网格划分情况如图5所示;FVCOM的设置参数如表4所述;各组例程的测试条件如表5所示。
本研究共包含16组序号为1至16的测试。其中,序号1至10为面向CPU计算的例程,用于探明MPI环境、数学库、节点数量、进程数量对FVCOM运行效能的影响;测试13至16为面向DCU计算的例程,用于验证FVCOM调用DCU加速卡的可行性和优劣性。
将序号为1至5的测试结果分别与序号为6至10的测试结果进行横向对比,可得出节点、进程数量相同的情况下MPI环境和数学库与效能的关系;将序号为1至4、序号为6至9的测试结果进行纵向对比,可得出系统环境相同的情况下进程数量与效能的关系;将序号为4和5、序号为9和10的测试结果进行纵向对比,可一定程度地得出节点间通信能力与效能的关系。
将序号为13至16、序号为7至10的测试结果进行横向对比,可得出软件环境相同的情况下效能较高的计算硬件;将序号为13至16的测试结果进行纵向对比,可得出软件环境相同情况下效能与进程数量的关系。
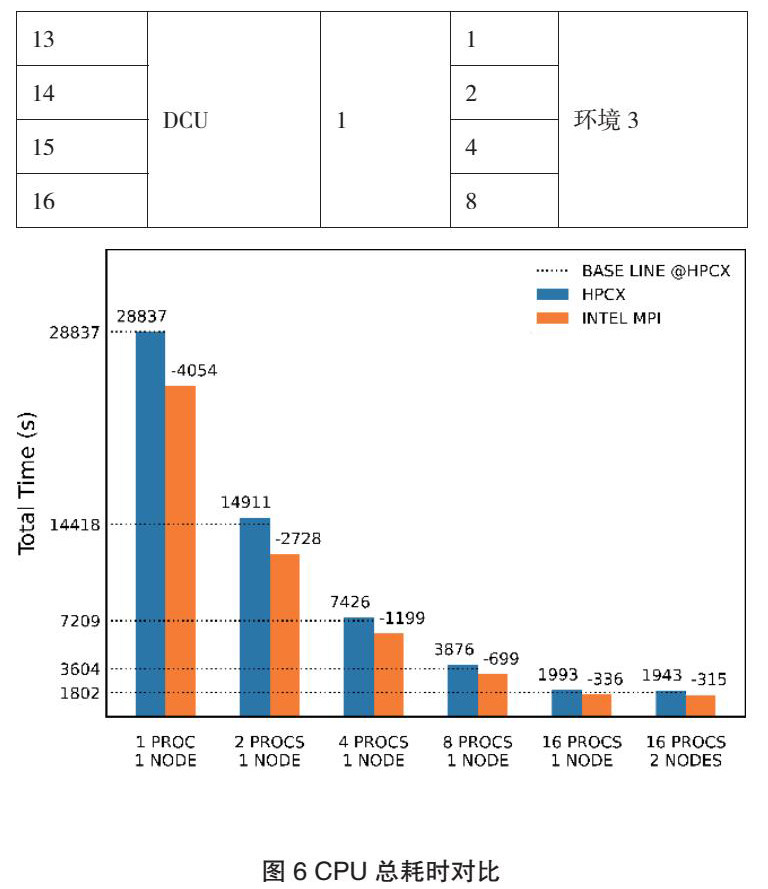
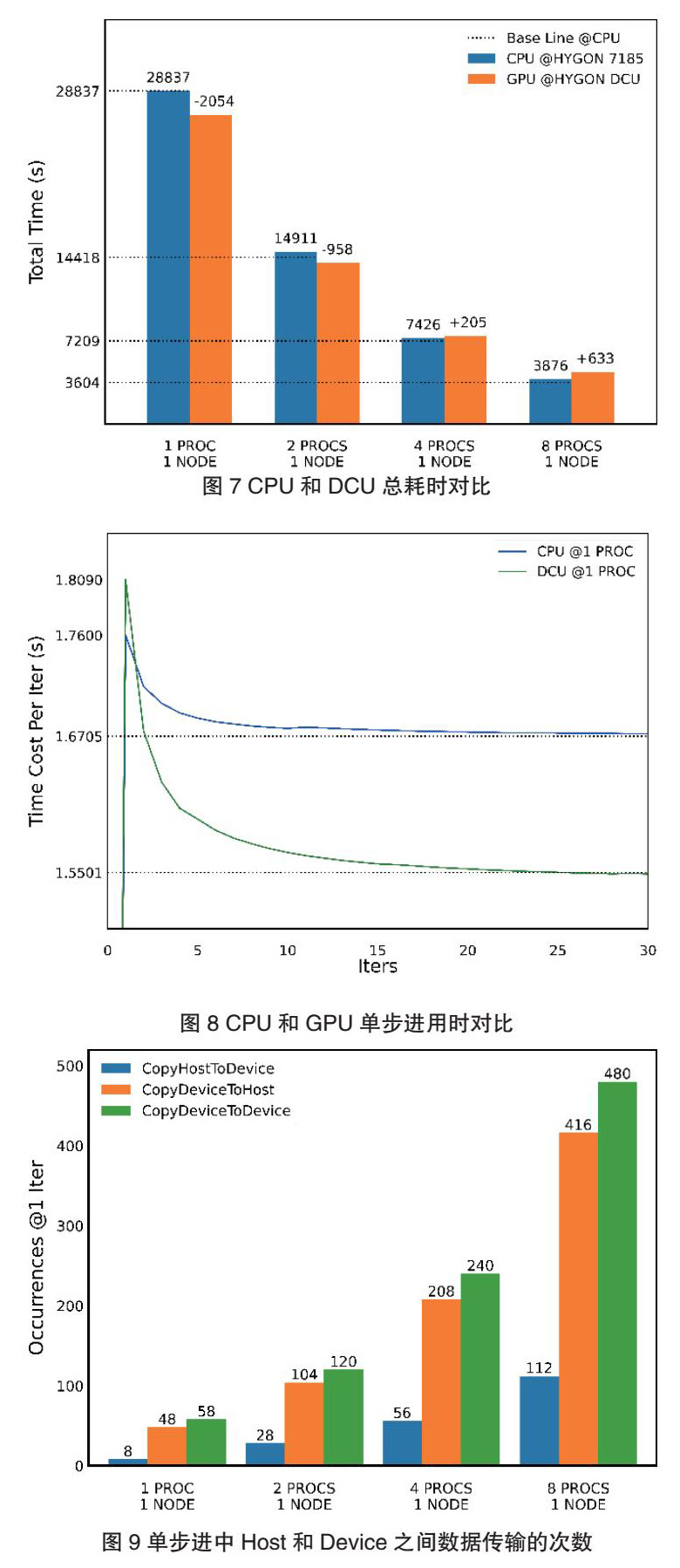
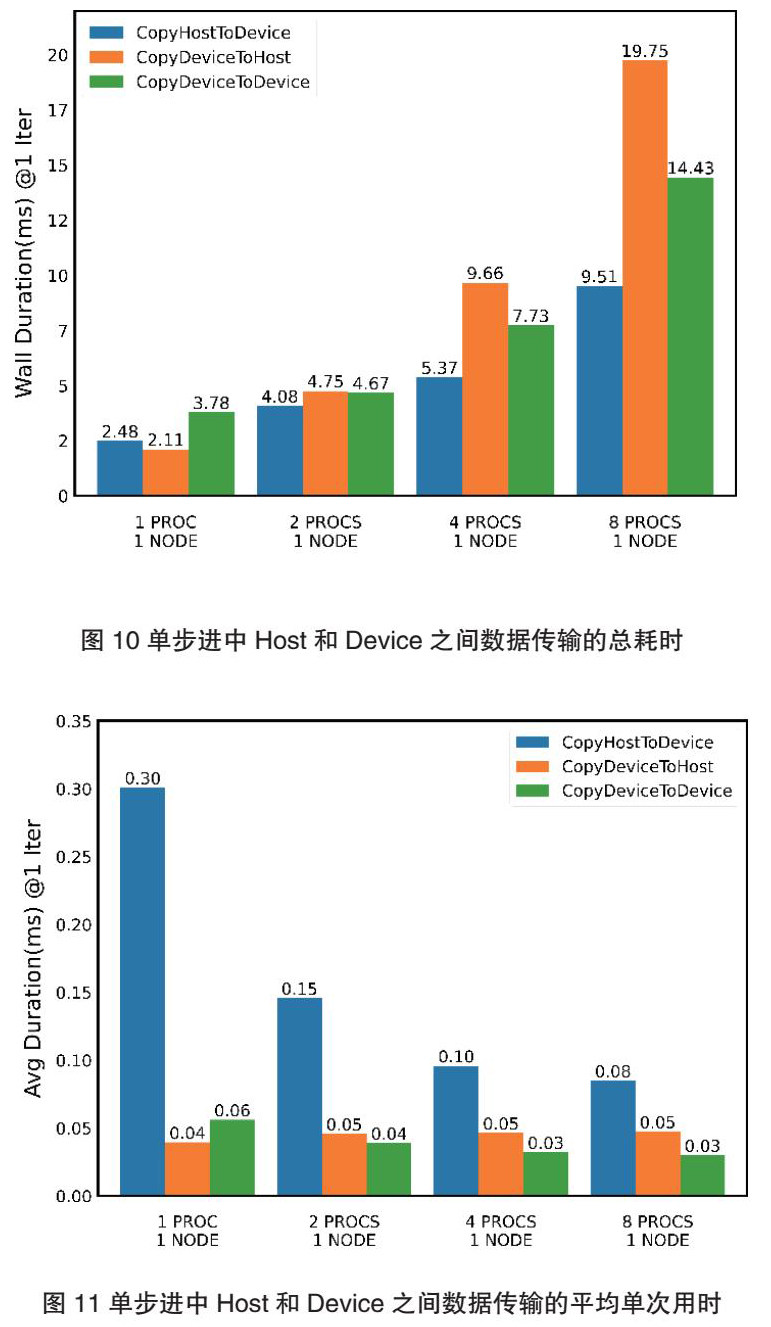
相关测试的对比结果如图6至图8所示。
通过对比面向CPU计算的各组测试例程,可以发现:(1)在面向CPU的计算中,总耗时与使用的进程数量基本呈反比关系;(2)使用INTEL MPI和MKL的测试在总耗时上存在较大的优势,但该优势随着进程数量的增加而减小;(3)在多节点下的多进程并行计算的总耗时略小于单节点下的情况;(4)以单进程计算下较高的总耗时与使用的进程数量的比值作为基准,可发现两者之间并不完全呈线性关系,实际耗时略高于基准值,存在一定的损耗情况。
通过对比各面向DCU计算的测试例程,并结合之前的结果,可以发现:(1)在面向DCU的计算中,总耗时与进程数量间同样存在反比关系;(2)在单进程和双进程计算时,使用DCU的测试在总耗时上存在优势;(3)在更多进程数量时则相反;(4)多进程下产生的损耗情况随进程的增加而增加;(5)在单进程计算下,面向DCU计算的初始步进用时更大,但之后快速减小并持续小于面向CPU计算的步进用时。
使用分析工具rocprof,基于DCU调用函数记录,对步进总数减少后的测试例程进行进一步分析,可得到不同硬件之间数据传输的情况。可以发现:(1)所有类型数据传输的使用次数与进程数量呈线性正比关系;(2)由内存向显存(HostToDevice)的数据传输,其单次用时的平均值最大,并与进程数量呈反比关系;(3)由显存向显存(DeviceToDevice)的数据传输,其单次用时的平均值不受进程数量影响;(4)由显存向内存(DeviceToHost)的数据传输,其单次用时的平均值同样不受进程数量的影响,但考虑到分析方法,该结果可能是由于统计不完全导致。
五、结束语
如何正确设置使用参数,处理好依赖关系,完成编译安装,是开展计算机科研工作的前提条件之一。随着软件功能的扩展,这一过程正变得越来越复杂。而一个处于高速发展、不断调整的计算平台,使完成这一过程的难度再一次增加。本次研究针对各软件的不同版本进行了多次尝试,最终在国产异构计算平台中构建了一套完整的FVCOM使用环境,可用于面向CPU和面向DCU的两种使用场景。当前,FVCOM在使用DCU加速功能时调用的依赖软件仍在开发和完善中,故相关结论具有时效性,同时也令整个构建过程具有很高的重复性、偶然性。
目前,ROCm平台不直接支持FVCOM使用的Fortran语言,这意味着无法通过直接添加程序段来引入异构加速功能。对于一个复杂的科研程序而言,其他技术路线的工作量较为庞大。本研究以依赖软件PETSc为突破口,在保留FVCOM原有编程语言和程序结构的情况下,将加速功能引入了FVCOM的半隐式计算模块中,在特定使用场景下缩短了计算耗时。该技术路线在开发上具有敏捷性,但其加速效果有限。
综上所述,FVCOM在使用异构加速计算功能上具有很大的潜力。而早前基于CUDA平台的成功案例,也使基于ROCm平台的异构开发具有无限的可能性。相信通过使用不同的技术路线,FVCOM在国产异构计算平台中的计算加速效果一定会获得质的提升。
参考文献:
[1]郑沛楠,宋军,张芳苒,鲍献文.常用海洋数值模式简介[J].海洋预报,2008(04):108-120.
[2]张驭洲,曹武迪,卜景德,谭光明,吉青.GROMACS 2020在ROCm平台上的移植与优化[J].计算机工程与科学,2021,43(11):1901-1909.
[3]闫霖,刘芳,刘庆军.基于ROCm并行探测部分子级联中的首次碰撞[J].计算机仿真,2020,37(03):275-278.
[4]赵旭东,梁书秀,孙昭晨,刘忠波,韩松林,任喜峰.基于GPU并行算法的水动力数学模型建立及其效率分析[J].大连理工大学学报,2014,54(02):204-209.
[5]岳孝强.几种并行AMG法及其在辐射扩散问题中的应用[D].湘潭大学,2012.
基金项目:本文系光合基金B类(20210702)课题“FVCOM海洋数值模型架构移植”(课题编号:ghfund202107021283)成果之一。
致谢:本文得到了光合组织在技术指导和经费等方面的支持,特此表示感谢。

 京公网安备 11011302003690号
京公网安备 11011302003690号


