



- 收藏
- 加入书签

基于PCA-KNN模型的财务预警实证研究
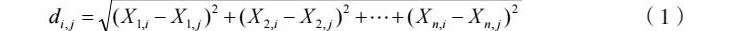 打开文本图片集
打开文本图片集
摘要:精准的财务预警模型对于公司进行财务危机管理具有重要的意义。文章以138家上市公司为研究对象,提出一种基于主成分分析法(PCA)和K近邻(KNN)算法的财务危机预警方法。首先,将财务数据进行标准化处理,然后通过构建的财务预警指标体系对公司的财务状况进行特征提取,最后通过PCA-KNN算法对公司的财务数据进行学习并构建出财务预警模型,实现对公司财务状况的预警。实证分析结果表明,该财务预警模型对实际发生财务危机的企业预测正确率达到100%,对实际未发生危机的企业误判率为26.7%,其综合准确率为86%。文章的研究特色为:考虑了第一类错误(将财务危机误判为非财务危机)与第二类错误(将非财务危机误判为财务危机)给投资者及公司管理者造成的犯错成本差异,PCA-KNN模型对发生财务危机的公司识别的准确率较高,可以极大地降低投资者及公司管理者的犯错成本,为公司财务危机预警提供一种新思路。
关键词:财务预警;PCA-KNN模型;实证研究
1、引言
财务预警是指通过建立企业的数据与财务风险之间的关系,进而对企业是否会发生财务危机做出预测。财务预警可以在企业发生财务危机之前给与管理者危机信号,使企业及时采取相应措施,避免企业陷入窘境,保证企业健康可持续的发展。同时财务预警对于投资者等利益相关者来说,也可为其决策提供参考。
关于财务预警模型,早期学者们应用较为广泛的包括:单变量判别模型[1]、多变量判别模型[2]、逻辑回归模型[3]等。随着信息技术的进步,学者们将机器学习技术应用于危机预警,如神经网络模型[4]、支持向量机[5]、随机森林[6]、决策树[7]等。与基于统计方法的财务预警模型如单变量判别模型等相比较,基于机器学习技术的财务预警模型不仅可以克服复杂的分析计算等困难,而且具有较强的学习能力和适应能力,因此也提高了财务预警模型的准确性和稳定性。其中,K近邻(KNN)算法可以通过计算待评估公司与已知样本公司的财务特征之间的距离,选出与待评估公司财务特征最相近的K个公司,再根据K个公司的财务状况以投票机制来实现对公司财务状况的预警评估。与以上机器学习技术相比,K近邻算法操作简单、易于从公司财务特征相似性原则来理解且精确度高,因此文章将K近邻算法引入到财务危机预警中。此外,文章不只考虑到模型预测的综合准确率,还关注模型的第一类错误(将财务危机误判为非财务危机),这是因为第一类错误给公司及利益相关者等带来的成本远高于第二类错误(将非财务危机误判为财务危机)[8]。基于以上情况,文章提出了财务危机预警模型—PCA-KNN模型,为财务危机的预测提供了一种新思路。
2、PCA-KNN财务预警模型构建
2.1 数理工具的选择
2.1.1 主成分分析
主成分分析(Principal Component Analysis,PCA)是一种经典的特征提取方法[9],这种方法将相关性高而且紧密联系的指标,在统计软件中进行降维处理,这些低维度指标将会尽可能多地概括未降维之前指标所要表达的信息。
2.1.2 KNN算法
K-近邻算法(KNN)是一种有监督的机器学习方法,常用于复杂高维数据的分类。由于危机公司预测的本质就是给已有的数据进行分类,即判别公司是否被ST,结果只有两种(ST公司,非ST公司),故KNN算法可用于这类样本的数据学习。该算法给数据分类的原则是:如果一个待分类公司在特征空间(即财务预警指标)中的K个最相近的样本公司大多数都属于同一种公司时,则该样本也同样属于这种公司类别,并且具有此类公司都存在的特性,即此类公司共同都具有的财务特性。
KNN算法中样本公司距离远近的度量有多种类型,包括欧氏距离、曼哈顿距离和切比雪夫距离等,距离越大,样本之间的差异性越大,反之,则相似性越高。文章选用的度量两个样本公司之间距离的标准为欧氏距离法。两个n维样本空间的欧氏距离计算方法如式(1)所示:
(1)
式中,i,j分别表示第i个和第j个样本公司。di,j表示第i个和第j个样本公司之间的欧氏距离。X表示样本的特征值,即预警指标值。n代表样本空间的维度,在这里指的是评价一个公司财务预警指标的维度,即n个预警指标。
2.2 财务预警指标选取
财务指标的选取直接影响着财务危机预警模型预测的准确性,文章参考了国内外多数学者的指标选取方法。基于指标选取的全面性与可获得性,文章选取了能充分反映公司经营发展状况的五大能力指标。其中偿债能力指标包括流动比率、速动比率、现金比率、资产负债率、产权比率、利息支付倍数;盈利能力指标包括净资产收益率、资产报酬率、主营业务利润率、销售净利率、每股收益;营运能力指标包括总资产周转率(次)、应收账款周转率(次)、存货周转率(次)、流动资产周转率(次);发展能力指标包括主营业务收入增长率、总资产增长率;现金流能力指标包括经营现金净流量对销售收入比率、资产的经营现金流量回报率、经营现金净流量对负债比率。
2.3 PCA-KNN财务预警模型的建立
公司的财务预警指标属于高维度数据,在实际应用中,这种模型输入变量之间会存在相关性。为了避免数据维度过高而造成算法的计算开销过大,文章通过SPSS软件将数据进行降维,作为KNN模型的输入变量。输出变量Y的赋值取决于公司是否被ST:若为ST公司,则Y=0;若为非ST公司,则Y=1。
基于PCA-KNN的财务预警模型的实现步骤如下:
(1)将原始数据用SPSS进行标准化处理,再用PCA进行数据降维;
(2)根据随机抽样技术,随机选取80%的数据(110组)作为PCA-KNN模型的训练集,剩下20%的数据(28组)作为测试集;
(3)初始化KNN算法的初始近邻样本数K值;
(4)采用欧式距离法计算训练样本中待测样本的K个近邻样本;
(5)根据K个近邻样本公司的的输出值(即是否为ST公司),采用投票机制对待测样本公司进行预测;
(6)采用5折交叉验证法计算PCA-KNN模型的最佳K值;
(7)用训练得到的模型在测试集上进行评估。
2.4 模型评估
为了对构建的PCA-KNN财务预警模型进行效果评估,文章引入混淆矩阵对该分类模型的预测误差进行考察。对于本模型的预测结果,混淆矩阵可以将其划分为四种结果,即将非ST公司判断为非ST公司、将非ST公司判断为ST公司、将ST公司判断为非ST公司、将ST公司判断为ST公司。
通过混淆矩阵计算出这四种结果所包括的数目,便可将模型分类的准确率(准确率=正确预测的数目/总数)计算出来,从而实现对财务预警模型的评估。
另外,企业管理层及利益相关者最重视的指标是第一类错误(将财务危机误判为非财务危机)和第二类错误(将非财务危机误判为财务危机)。因此,上述两个指标也作为文章对财务预警模型的一种评估手段,其计算公式为:
第一类错误=1-(正确预测的ST数目/实际ST数目)
第二类错误=1-(正确预测的非ST数目/实际非ST数目)
3、基于PCA-KNN的财务预警模型的应用
3.1 数据来源及样本选择
文章选取了2016-2021年制造业上市公司中出现ST及*ST的75家公司作为“财务危机公司”样本,同时以相同行业、相同规模的原则按照1:1的比例选取了75家公司作为“非财务危机公司”样本,共有150家制造业企业作为研究样本。
文章将因亏损严重等财务状况的发生而使上市公司被特别处理的年份记为T年,以此作为上市公司发生财务危机的分界点,研究数据选取自公司T-2年的财务数据。这是因为,公司在被ST之前的三年及以上,是ST公司刚开始从盈利转为亏损的年份,一般ST公司都会进行盈余管理,使ST公司的财务状况与财务状况正常的公司相比没有显著差异。因此,采用公司被ST之前的三年及以上的数据对公司进行财务危机预测没有参考价值。而公司当年的财务数据一般于次年的4月份左右才会公布,因此公司被ST的当年或T-1年,公司的不良财务状况已经发生,对公司再进行财务危机预测已经没什么意义。总体来看,选取ST公司T-2年的财务数据进行财务危机预测是最合适的。
3.2 数据收集与标准化处理
3.2.1 数据收集
文章选取了沪深A股的部分制造业上市公司作为研究对象,数据通过Python编写网络爬虫程序爬取于东方财富、新浪财经等网站的公开数据,包括公司年报、公告等。由于部分公司的某些数据存在缺失,经过手动核算缺失的指标以及剔除无效数据后,最终确定的研究样本为138家上市公司,其中“财务危机公司”69家,“非财务危机公司”69家。
3.2.2 标准化处理
由于不同的财务指标之间数值的大小差别较大,如果不对收集到的数据进行标准化处理,可能会影响数据分析的准确性及稳定性,因此文章采用z-score标准化对数据进行处理,使数据服从正态分布,即经过处理的数据的均值为0,标准差为1。
3.3 基于PCA-KNN的财务预警模型的分析
3.3.1 使用PCA提取主成分
公司的财务指标在计算时一般都存在勾稽关系,文章选取的20个候选指标之间可能存在相关性,这会影响财务预警模型的准确性和稳定性。因此有必要对选取的20个候选指标通过SPSS软件进行进一步筛选。
(1)KMO和Bartlett检验
为了对PCA的适用性进行说明,文章选用KMO和Bartlett进行检验。KMO检验可以用来分析各个财务指标之间的相关性,取值越接近于1越好;Bartlett检验用来判断财务指标之间的独立性,取值越接近0越好。经检验,KMO的结果为0.557>0.5,Bartlett的结果Sig.=0<0.01。综合分析,说明文章选取的指标可以进行因子分析。
(2)因子分析
因子分析的主要目的就是要选取出较少的因子来概括较大部分信息。在指标选取和对数据进行处理之后,通过计算相关矩阵来反映指标之间的相关关系,然后通过统计软件提取公共因子。运用这种技术,可以快速找出造成财务危机的因素以及影响力大小,并运用于实践[10]。
文章通过SPSS软件进行因子分析,选取累计方差贡献率达到75%时的因子作为公共因子。前7个公共因子的累计贡献率达到77.011%,因此认为前7个指标可以概括整体信息。
在选取了7个公共因子之后,对成分矩阵进行旋转处理后可得出决定7个公共因子的指标分别为:流动比率、总资产周转率、经营现金净流量对销售收入比率、每股收益、应收账款周转率、产权比率、利息支付倍数。
3.3.2 基于PCA-KNN财务预警模型的财务危机预测
为了对PCA-KNN财务预警模型进行评估,文章对138组上市公司财务数据进行实证研究,其中,随机选取80%的数据(110组)作为PCA-KNN模型的训练集,剩下20%的数据(28组)作为测试集。
同时需要设置KNN算法的参数来保证模型的评估效果。K是KNN算法的一个超参数,需要通过经验对其进行设置。为了避免数据集划分对财务预警模型的训练结果产生影响,文章采用5折交叉验证法获得PCA-KNN财务预警模型的最佳K值,即K=8。
采用PCA-KNN财务预警模型的测试结果如下:
针对训练集的测试结果:将ST公司预测为ST公司的频数为56,将ST公司预测为非ST公司的频数为0;将非ST公司预测为ST公司的频数为0,将非ST公司预测为非ST公司的频数为54。
针对预测集的测试结果:将ST公司预测为ST公司的频数为13,将ST公司预测为非ST公司的频数为0;将非ST公司预测为ST公司的频数为4,将非ST公司预测为非ST公司的频数为11。
由上述结果可知,PCA-KNN预警模型在训练集上的准确率为100%,即模型对训练集样本公司进行分类时,可以将财务危机公司及非财务危机公司全部识别正确。PCA-KNN预警模型在测试集上的综合准确率为86%,进行测试集测试时可以将财务危机公司全部识别正确,准确率为100%,大大降低了预警模型犯第一类错误所导致的成本;对非财务危机公司的误判率(即发生第二类错误)为26.7%,误判率较低。
4、结语
文章所建立的PCA-KNN财务预警模型对财务危机公司识别的准确率较高,对非财务危机公司的误判率较低,可见此模型有较高的综合准确率。该模型可以极大的降低预警模型犯错误的损失,这是因为把一个财务危机公司错分类为非财务危机公司的成本,远比把一个非财务危机公司错分类为财务危机公司的成本要大得多,即第一类错误带来的成本远高于第二类错误。这对于公司管理者及其他利益相关者来说,可以大大降低其犯错成本。可见,PCA-KNN财务预警模型可以为上市公司提供较准确的危机预警,便于上市公司提前制定应对财务危机的策略;同时对于投资者等利益相关者来说,也为其决策提供了参考。PCA-KNN财务预警模型为公司的财务危机预警提供了一种新思路。
参考文献:
[1]陈静.上市公司财务恶化预测的实证分析[J].会计研究,1999(04):31-38.
[2]袁康来.我国农业上市公司财务困境预测的实证研究[J].华东经济管理,2008(01):78-84.
[3]马丰宁,尹雪丽,谭庆美.基于Logsitic回归模型的香港上市公司退市情况分析[J].管理现代化,2016,36(04):6-9.
[4]杨淑娥,王乐平.基于BP神经网络和面板数据的上市公司财务危机预警[J].系统工程理论与实践.2007,(02):61-67.
[5]严良,李淑雯,蒋梦婷等.基于PCA的DE-SVM资源型企业财务风险识别模式研究[J].会计之友.2019,(07):58-65.
[6]刘佳.K折随机森林算法在企业财务危机预警中的应用研究[J].贵阳学院学报.2021,16(04):46-49.
[7]鲍新中,傅宏宇.基于变精度加权平均粗糙度决策树的财务预警研究[J].运筹与管理.2015,24(03):189-196.
[8]关欣,王征.基于Logistic回归和BP神经网络的财务预警模型比较[J].企业管理,2016,17(461):179-181.
[9]Tipping M E,Bishop C M.Probabilistic Principal Component Analysis[J].Journal of the Royal Statistical Society,1999,61(3):611-622.
[10]赵辰,南星恒.基于MEA-BP神经网络的财务危机预警研究[J].财会通讯,2016,(01):43-46.

 京公网安备 11011302003690号
京公网安备 11011302003690号


