



- 收藏
- 加入书签

基于Python的豆瓣读书排行榜的爬取与可视化分析
 打开文本图片集
打开文本图片集

摘要:随着网络的发展,阅读已成为日常生活的一部分,而网上阅读已经成为当前主流之一。本文章主要利用Python爬虫技术对豆瓣阅读的书籍排行信息进行爬虫分析,通过数据可视化技术,直观地展示排行书籍种类以及类型,分析当代阅读人群的阅读领域、情感等阅读现状,为作者、编者提供编写方向以及为读者提供阅读参考意义。
关键字:Python;爬虫;数据可视化;数据分析
中图分类号:TP520.2099 文献标识码:A 文章编号:
Abstract:With the development of the internet, reading has become a part of daily life, and online reading has become one of the current mainstream. This article mainly uses Python web scraping technology to analyze the ranking information of Douban Reading books. Through data visualization technology, it intuitively displays the types and types of ranked books, analyzes the reading field, emotions, and other reading status of contemporary readers, and provides writing direction for authors and editors as well as reading reference significance for readers.
Keywords: Python; Reptiles; Data visualization; Data analysis
0 引言
1 Python网络爬虫
自动获取网页数据的脚本或程序称为网络爬虫,目前利用Python语言进行爬虫是非常广泛的。网络爬虫主要按照规则模拟浏览器上网,将所需要的数据进行提取或收集信息[2]。网络爬虫可指定一个网页地址或多个网页地址,爬取初始网页并提取网页上的数据并解析,然后将收录的网页中在找到相关的网页,并且能按照排名规则对URL进行排序,最后将排序后的结果返回[3]。网络爬虫主要有以下4步:
(1)发起请求:利用好GET和POST,向目标网站服务器发出请求,其中请求中一般包括请求头、方法等信息,并等待目标服务器的回应。
(2)获取响应内容:发出请求之后,一般都能得到目标服务器返回的结果。
(3)解析内容:目标服务器返回结果一般是HTML内容,为获取目标数据,利用xpath、正则表达式、定位方式来提取数据。
(4)保存数据:将提取到的数据保存到csv或者execl中,以便查看。
2 阅读排行榜数据爬取
2.1 数据爬取对象
本文章的研究对象是豆瓣阅读网站上的阅读排行数据信息,通过对比各大阅读网站发现,豆瓣阅读上书籍数量、阅读人群基数等是比较多的,而且豆瓣阅读能够及时更新书籍、阅读数量、评分等信息。选择豆瓣阅读的排行榜信息进行爬取,主要获取排行中的书籍的排名、作者、体载、类型等书籍,通过分析豆瓣排行榜来研究当前主流阅读现状[8]。
2.2 数据爬取流程
2.2.1 分析排行榜URL
豆瓣官网上包括多种种类的书籍而且排行榜中,按不同方式排行的较多。如以连载榜为例,网址为’https://read.douban.com/charts/featured?type=unfinished_column&dcs=charts&dcm=chart-card-more&dcc=featured&dct=unfinished_column’,通过分析URL发现,URL中的”unfinished_column”表示连载榜,通过改变类型就可以爬取不同类型排行榜的书籍信息。
2.2.2 爬取排行数据
通过利用Selenium模拟浏览器交互来自动爬取阅读排行信息,Selenium是一款基于浏览器、功能十分强大的自动化测试工具,而且其获取数据比传统爬取数据方便的多,因为Selenium不像传统的爬虫一样要利用Requests来分析每个请求的具体参数。首先创建 WebDriver 对象,指定使用的浏览器,再利用WebDriver 对象的get()函数来打开目标网页,再后通过 class、id、xpath等定位方式来识别定位元素,获取页面上某个数据的元素。关键代码如下:
browser=webdriver.Chrome()
browser.get(url)
browser.find_elements(By.定位方式,value).text
2.2.3 定位元素解析数据
Selenium能够自定识别并定位到所需的元素,其中Selenium定位方式有id、calss、css、xpath、name、link等。例如,书名信息在标签<span class="title-text"></span>中,通browser.find_elements(By.CLASS_NANE,’title-text’).text就可以获取书名。书名、排名、种类、评分等数据都是按照以上方式来获取。关键代码如下:
rank=self.browser.find_elements(By.CLASS_NAME,'rankingNumber--TO57l')[i].text # 排名
name=self.browser.find_elements(By.CLASS_NAME,'title-text')[i].text #书名
kind=self.browser.find_elements(By.CLASS_NAME,'kind-link')[i].text # 种类
tag=self.browser.find_elements(By.CLASS_NAME,'tag')[i].text#标签
2.2.4 数据保存
定位到指定元素后,将书名排名信息数据以字典的形式进行封装。再利用 Workbook()对象把封装好的数据写到excel文件中,方便查看。
3 阅读排行榜分析及数据可视化
数据可视化主要是将目标数据以2D、3D图形的形式展示出来,使得数据更直观更易于分析。Python中被广泛应用的可视化库是Matploatlib。其通过绘制散点图、条形图、饼状图等图形,直观地展示数据,便于研究人员理解分析数据及更好地帮助研究人员作出决策[8]。
3.1 数据预处理
通过网络爬虫得到的阅读排行榜数据,将数据进行预处理是必须的,其中数据预处理包括删除异常值、整合数据等,这有利于数据可视化[5]。具体步骤如下:
(1)删除缺失种类、排名等关键书籍的书籍信息,保留缺失评分、评语等非关键性书籍信息。
(2)删除书籍字数、评分数据中的单位信息,仅保留数字,便于后期绘制图表和分析数据。如“20万字”改为”20”,”8.4分”改为”8.4”。
3.2 可视化
3.2.1 排行榜书籍种类分析
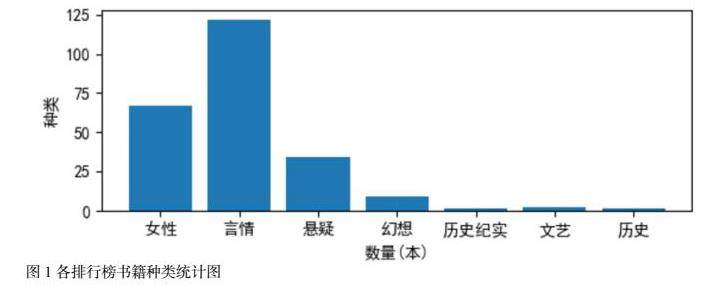
随着电子阅读行业的发展,越来越多的不同年龄群体加入到电子阅读中,因此不同类型的书籍阅读量也有很大的差距。通过排行方式不同,本次选择了豆瓣阅读8个排行榜,统计排行榜种类并绘制图表,如图1。据图1统计结果所示,不同种类的书籍存在较大的差异,”女性”,”言情”种类的书籍数量较多,而”历史纪实”,”文艺”,”历史”类的数量极少。
3.2.2 排行书籍热点分析
豆瓣网站上书籍信息很多,因为了吸引读者阅读、订购,书籍上架一般会包含特定词语介绍并突出特点。为了分析排行榜书籍的热点,将爬取到的热点利用Jieba库对热点文本分词,统计词频,再利用WordCloud库绘制词云图,如图2所示。据图2结果展示,”现代言情”,”古代言情”是最高的,说明言情更让读者产生代入感,以及读者渴望遇到完美的爱情,”成长逆袭”,”职场女性”等词频也比较高,说明读者多数为女性,且女性读者对职场上取到一定的成绩是很向往的。
4 结论
文章基于Python爬虫技术,爬取了豆瓣阅读排行榜的阅读排行数据并且进行分析,通过Numpy、Matplotlib等可视化技术直观地展示了当代阅读人群的阅读状况,为阅读者提供参考阅读意义以及编者、作者提供编写领域方向。
参考文献
[1] 罗晓军.基于聚类算法的学生学籍数据分析[J].湖南邮电职业技术学院学报,2023,22(04):52-56.
[2] 王蔷,郭琪.基于Python语言的微博网络数据可视化系统设计与应用[J].电脑编程技巧与维护,2023,(11):101-104.DOI:10.16184/j.cnki.comprg.2023.11.012.
[3] 马腾,余粟.基于Python爬虫的二手房信息数据可视化分析[J].软件,2023,44(07):29-31.
[4] 苏明焱.基于Python的招聘网站信息的爬取与数据分析[J].信息与电脑(理论版),2022,34(24):193-195.
[5] 刘晓知.基于Python的招聘网站信息爬取与数据分析[J].电子测试,2020,(12):75-76+110.DOI:10.16520/j.cnki.1000-8519.2020.12.027.
[6] 王芳.基于Python的招聘网站信息爬取与数据分析[J].信息技术与网络安全,2019,38(08):42-46+57.DOI:10.19358/j.issn.2096-5133.2019.08.009.
[7]陈太沁.基于Python的视频数据爬虫系统设计与实现[J].广播电视网络,2024,31(01):110-112.DOI:10.16045/j.cnki.catvtec.2024.01.012.
[8]蔡文乐,秦立静.基于Python爬虫的招聘数据可视化分析[J].物联网技术,2024,14(01):102-105.DOI:10.16667/j.issn.2095-1302.2024.01.028
[9]时业茂,颜晓宏,章祖华.基于Python使用爬虫从豆瓣网获取最新上映的电影信息[J].电脑编程技巧与维护,2023,(12):153-155.DOI:10.16184/j.cnki.comprg.2023.12.035.
[10]张启宁,吴国俊.基于Python网络爬虫技术的乡村旅游数据采集与分析[J].产业科技创新,2023,5(06):66-68.

 京公网安备 11011302003690号
京公网安备 11011302003690号


