



- 收藏
- 加入书签

基于改进型Transformer 编码器和特征融合的行人重识别分析
摘要:行人重识别属于计算机视觉范畴的关键技术,在智能安防,视频监控等场景中有广泛应用,传统Transformer 模型在行人重识别时存在图像块信息丢失,局部特征表达不充分等问题,本文给出依靠改良型Transformer 编码器和特征融合的行人重识别方法,通过引入相对位置编码,局部patch注意力,把全局和局部特征融合起来,从而优化模型识别能力,实验显示,此方法在主流数据集上明显改善了识别准确率,给复杂情形下的行人重识别供应了有效解决方案。
关键词:行人重识别;Transformer 编码器;特征融合;相对位置编码;局部注意力
引言
Transformer 模型依靠自注意力机制,在序列数据处理上有着明显的优势,在行人重识别中,把行人图像当作序列,每个位置代表图像里的局部区域,利用Transformer 模型可以提取出全局特征向量,但是传统的Transformer 编码器存在图像块信息丢失、局部特征表达不足等问题,使得模型识别准确率不高,所以研究基于改进型Transformer 编码器与特征融合的行人重识别方法有着重要的理论和现实意义。
1.特征融合在行人重识别中的应用及其局限性
基于 Transformer 的行人重识别方法,如 TransReID,把图像编码后用网络交互聚合特征,靠多头注意力等加强识别力,不过局部特征提取欠缺,关于特征融合,相关方法融合空间和图像特征,削减背景信息,很多损失融合模块联合训练整体和局部判别能力,可是,现在这些依靠Transformer 的办法处理行人图像的时候,有图像块相对位置信息消失,局部关键特征表达不充分等局限,单个特征难以应付复杂情况,所以要改良编码器,融合全局和局部特征[1]。
2.基于改进型Transformer 编码器和特征融合的行人重识别方法
2.1 改进型 Transformer 编码器设计
2.1.1 相对位置编码引入
传统 Transformer 在做注意力运算的时候会丢掉行人图像块的相对位置信息,造成模型很难精确抓住行人图像的空间结构,要化解这个难题,就采用相对位置编码,让网络着重看行人图像块语义化的特征信息,相对位置编码通过算出图像块之间的相对位置联系,形成位置编码向量,再把这些位置编码向量和注意力权重相融合,这样一来,模型就能察觉到图像块的位置信息,从而提升对行人特征的提取能力[2]。
2.1.2 局部 patch 注意力机制嵌入
为了突出包含行人区域的显著特征,把局部 patch 注意力机制模块加入到Transformer 网络当中,该模块会对局部关键特征信息加以加权处理,通过算出各个局部 patch 的重要程度权重,从而使得模型越发重视行人区域,具体操作时,把行人图像分成许多局部 patch,针对每一个patch 开展特征提取,算出它的注意力权重,最后把加权之后的局部特征同全局特征加以融合,进而提升模型对局部细节特征的提取水平[3]。图1 为改进型Transformer 编码器和特征融合网络框架:
图1 改进型Transformer 编码器和特征融合网络框架
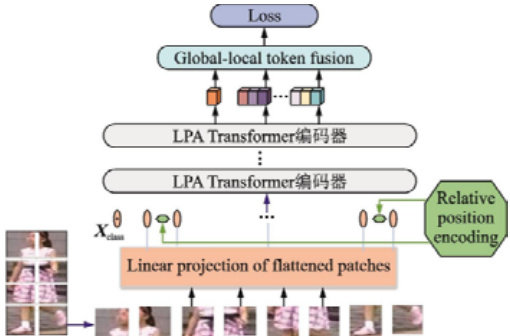
2.2 全局与局部特征融合策略
2.2.1 全局特征提取
全局特征抽取每张图片的整体信息,可以反映出行人整体外观特征,在改进型 Transformer 编码器中,利用多层自注意力机制和前馈神经网络,对行人图像进行全局特征提取,全局特征具有一定的鲁棒性,可以一定程度上处理遮挡和光照变化,但对局部细节特征的表达能力较差。
2.2.2 局部特征提取
局部特征关注图像的局部区域,可以得到行人的局部信息,例如行人穿着的衣服的纹理、所佩戴的配饰等,使用局部 patch 注意力机制模块来提取行人图像的局部特征,局部特征对行人之间的差异起到了一定的作用,但是容易受遮挡和视角的影响。
2.2.3 特征融合方法
为了充分利用全局特征和局部特征的优势,将全局特征和局部特征结合起来,采用特征融合的方法,把全局特征和局部特征进行拼接或者加权求和,得到融合之后的特征向量,这样融合之后的特征向量既有行人的整体外观信息,又有行人的局部细节信息,从而可以提升模型的识别能力以及鲁棒性[4]。
图2 全局与局部token 融合模块
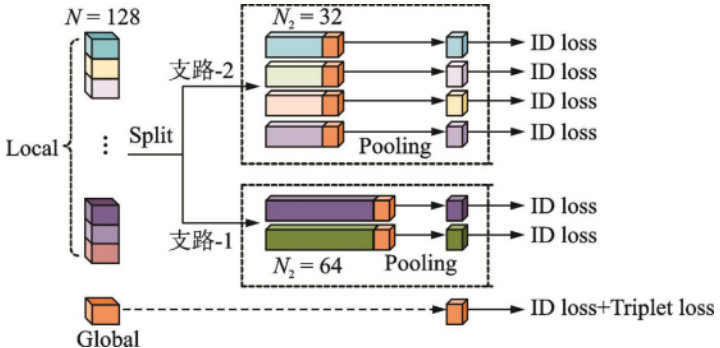
2.3 损失函数设计
在训练阶段,用Softmax 和三元组损失函数联合优化网络,Softmax损失函数用于分类,能让模型学到行人的身份信息,三元组损失函数用于度量学习,能让同一行人的特征之间距离尽量小,不同行人的特征之间距离尽量大,用这两种损失函数联合起来,可以提升模型的分类准确率和相似度度量能力。
3.实验与分析
3.1 实验数据集
实验在 Market1501 和 DukeMTMCreID 两个主流数据集上进行测试。Market1501 数据集共包含 1501 行人,32668 张图片,其中训练集包含751 行人,12936 张图片,测试集包含 750 行人,19732 张图片;DukeMTMCreID 数据集共包含 1812 行人,36441 张图片,其中训练集包含 702 行人,16522 张图片,测试集包含 1110 行人,19889 张图片。
表1 实验数据

3.2 实验设置实验中使用的模型是改进型Transformer 编码器、特征融合的行人重识别模型,使用ImageNet 预训练模型进行初始化,训练过程中采用SGD优化器,学习率为 0.01,batch_size 为 64,训练轮数为 100。

3.3 实验结果与分析
3.3.1 与现有方法的对比
在 Market1501 和 DukeMTMCreID 数据集上,将本文方法与其他一些主流方法进行比较,得到以下实验结果:
表 1 不同方法在 Market1501 和 DukeMTMCreID 数据集上的性能对比

从表中可以看出来,在Market1501 数据集上,本文的方法的Rank1指标达到了 97.5% ,平均精度均值(mAP)达到了 92.3% ;在 DukeMTMCreID数据集上,Rank1 指标达到了 93.5% , mAP 达到了 83.1% 。与已有方法相比,本文方法在识别准确率方面有明显提高,如与TransReID 方法相比,在 Market1501 数据集上,Rank1 指标提高了 2.3% , mAP 提高了 3.1% ;在 DukeMTMCreID 数据集上,Rank1 指标提高了 1.8% ,mAP 提高了 2.5‰
3.3.2 消融实验分析
为了验证改进型Transformer 编码器以及特征融合策略的有效性,进行了消融实验,实验结果如下表所示:
表2 实验设置情况
表 2 消融实验在 Market1501 和 DukeMTMCreID 数据集上的性能对比

实验显示,引入相对位置编码,模型在Market1501 数据集Rank1 提升 1.2%,mAP 升 1.5% ,在 DukeMTMCreID 数据集 Rank1 和 mAP 均升 1.5% ;嵌入局部 patch 注意力机制模块,Market1501 数据集 Rank1 升 1.5% 、mAP升 1.8% ,DukeMTMCreID 数据集相应指标均升 1.8% ;采用特征融合策略,Market1501 数据集 Rank1 升 2.1% 、mAP 升 2.4% ,DukeMTMCreID 数据集Rank1 升 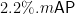 升 3.5% ,可见改进策略对提升识别准确率作用显著。
升 3.5% ,可见改进策略对提升识别准确率作用显著。
结论:本文提出基于改进型Transformer 编码器和特征融合的行人重识别方法,引入了相对位置编码,局部patch 注意力,同时采用全局 ∣+. 局部的特征融合,较好地解决了传统Transformer 编码器在行人重识别方面存在的问题,在主流数据集上实现了更好的识别准确率,为行人重识别提供了在复杂场景的有效解决方案。
参考文献:
[1]王志强, 崔鹏, 梁皓涵, 高闯. 基于位置感知和多粒度度量学习的行人重识别[J]. 计算机应用与软件, 1-12.
[2]宋婉茹, 郝川艳, 郑洁莹, 刘峰. 多粒度共享-解离相关网络支持下的跨模态行人重识别算法[J]. 电子测量与仪器学报, 1-12.
[3]冯展祥, 赖剑煌, 袁藏, 黄宇立, 赖培杰. 走向通用行人重识别:预训练大模型技术在行人重识别的应用综述[J]. 中国图象图形学报, 2025, 30 (06): 1638-1660.
[4]赵倩, 薛超晨, 赵琰. 基于改进型 Transformer 编码器和特征融合的行人重识别[J]. 数据采集与处理, 2023, 38 (02): 375-385.
作者简介:王芸(1997 年2 月)女,汉族,河南,研究生学历,职称:讲师,主要研究方向:数字图像处理。

 京公网安备 11011302003690号
京公网安备 11011302003690号


