



- 收藏
- 加入书签

基于深度学习的鲁棒视频行人检测与追踪算法
摘要 针对目前智能交通系统在对行人的检测与追踪过程中,存在着运算速度慢、检测精度低及鲁棒性差等问题,本文提出了一 种基于深度学习的视频行人交通检测与追踪算法。首先基于 YOLOv5l 网络设计了检测模块,在其主干网络中嵌入了多尺度融合的注意力结构,可以有效提高检测网络对目标物识别的准确度,并利用深度可分离卷积替换普通卷积,以此降低模型的运算量并加快运算速度。然后将获取到的目标物信息传入追踪模块中,该模块利用多种特征信息候选机制来对行人进行重识别,即使目标物受到遮挡,仍能进行跟踪。仿真结果表明,本算法与当前常见的目标检测算法相比获得了一定提升,并且有着更好的鲁棒性和时效性。
关键词 交通视频;深度学习;目标检测;行人识别
引言:目前,关于视频监控的目标识别技术在社会安全,智能交通,虚拟现实等领域有着广阔的应用前景。随着数字多媒体技术与人工智能的快速发展,为计算机视觉领域注入了新的活力[1]。
行人交通是我国交通的重要组成部分,如何准确检测行人,监控人流量对减少各类事故发生有着极大的帮助。在真实工况下,行人检测面临着更多的挑战,如烟雾,粉尘以及噪点等影响。另外,面对大量且复杂的信息,需要对算法的实时性,运算复杂度以及部署的难易程度都有较高的要求。针对这些问题,本文提出了一种基于YOLOv5l 和DeepSort 的视频行人目标检测和追踪算法,在检测模块中嵌入了多尺度融合的SKNet 注意力机制,并将普通卷积替换为深度可分离卷积;在追踪模块中,设计了多特征候选匹配机制,在保证计算效率的同时提高了模型的鲁棒性。该算法具有实际应用价值,可用于行人流量与密度监控。
1 行人检测与追踪算法方案
本文设计的行人检测与追踪模型,主要分为两个部分,一个是以 YOLOv5l 作为检测器用来提取特征信息的行人检测模块。另一部分是基于DeepSort 算法的行人追踪模块,所提出的算法主要流程如图1 所示。
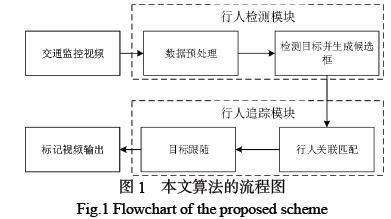
1.1 基于 YOLOv5 的视频行人检测算法
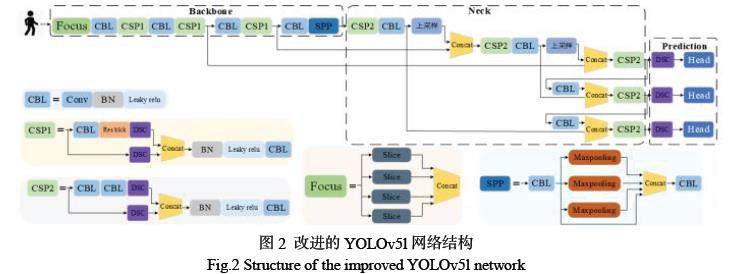
YOLOv5l 模型的基本结构由输入端、Backbone、Neck 和 Head 四部分组成,如图 2 所示,其主干网络为 CSPDarknet53,主要由 CBL 模块和 CSP 模块构成[2]。Neck 部分位于主干网络和 Head 网络的中间,利用它可以进一步提升特征的多样性及鲁棒性。Prediction 部分则由三个大小不同的 Yolo Head构成,将提取的特征转化为预测结果,并输出分类结果和目标的边界框。
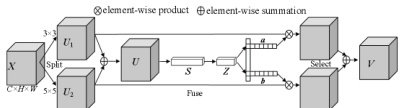
在真实工况下,需要检测网络对目标物的特征更加准确且敏感。为此,本文在CSPDarknet53 的特征提取网络的基础上嵌入了SKNet 结构[3],并与残差结构结合起来。本算法所设计的SKNet 通过构建一个非线性的方法来融合不同卷积核所提取的特征,以重点突出目标物的主要特征而抑制无关特征,从而提升特征的整体表达能力,其详细结构如图3 所示。
具体来说,给定一个特征 X∈Rc×H×W , C 为特征图通道数, H 和W 分别为高和宽。首先对其做Split 操作,即使用两个大小分别为 3×3 以及 5×5 的卷积核对输入特征进行变换,得到两个新特征U1∈RC×H×W 和 Uz∈Rc×H×W 。
再对特征 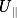 和 Uz 进行Fuse 操作,具体步骤为,先融合两个分支上的所有信息,形成新特征图 U :Uu⊕Uz=U (1)
和 Uz 进行Fuse 操作,具体步骤为,先融合两个分支上的所有信息,形成新特征图 U :Uu⊕Uz=U (1)
其中, ⊕ 为矩阵对应位置元素相加。
之后使用全局平均池化层(Global average pooling)在通道方向上整合调整,进而将特征图 U 转化为向量 S∈Rc ,向量中第 k 个的元素值为:
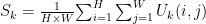
其中,i, j 分别为特征图 U 中第 k 个通道中的参数位置坐标。
接下来,通过一个全连接层(Fully connected layer, FC)对向量 s 进一步凝练与调整,同时进行降维处理,得到一个紧凑的向量 Z∈Rd 。
Z=d(WS) (3)
其中, d 为Relu 激活函数, W∈Rd×C 。
最后进行Select 操作,对得到的向量 z 通过softmax 操作以进行对不同尺寸特征的自适应选择。对于特征图 Ur 和 Uı 而言,其注意力权重向量 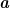 和 b 可分别由式(4)和式(5)得到:
和 b 可分别由式(4)和式(5)得到:
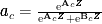
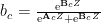
其中,矩阵 A∈RC×d , B∈RC×d 为可学习的矩阵, AC 和 Bc 为对应矩阵的第 c 行的行向量, ac 和bC 为对应向量中的第 c 个元素值。
由于 ac+bc=1 ,各通道对应的经过加权融合的特征图 u 的表达式为:
Vc=ac⋅U1,c+bc⋅U2,c
Π=ac(U1,c-U2,c)+U2,c
其中, U1,C 和 U2,C 分别为矩阵的第 c 行的行向量。
由于后面堆叠的CBL 模块已经学习了较高维度的抽象特征,再加入 SKNet 注意力机制所带来的增益较为有限,所以仅将此机制嵌入到前三个 CBL 模块之后。通过对特征图上不同通道的特征做重要性分析,可以将得到的具有高代表性的特征作为输入传入到下一个模块,借助两个支路上不同卷积核大小所提取的特征,可以丰富行人目标的语义信息,同时弱化与目标无关的特征,适合对小目标进行识别。
图 3 SKNet 结构图
Fig.3 Structure of SKNet
随着监控摄像头数量的增加,处理器往往需要同时处理多路视频信号,所以不仅需要提高算法的鲁棒性,并要求减少模型运算量。为此,本文引入了深度可分离卷积(Depthwise Separable Convolution,DSC)[4],为硬件设备减轻负担。
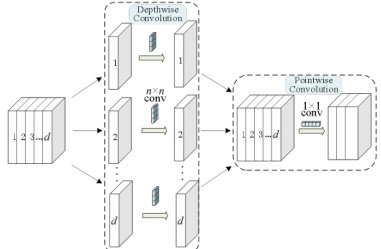
深度可分离卷积是一个可分解卷积的操作,包含Depthwise 卷积和Pointwise 卷积两个部分,具体操作流程如图4 所示。Depthwise 卷积是对输入特征图的每个通道上的数据单独做卷积,与其他通道上的数据没有交互,即逐通道卷积。Pointwise 卷积是将上一步 Depthwise 卷积得到的特征图在通道方向上进行加权融合,其核心原理是使用大小为 1×1×d 的卷积,其中 d 为上一层的通道数,在通道方向上对数据进行降维,从而达到凝练主要特征的效果。在本算法中,将SPP 和Neck 中所有的普通卷积都替换为深度可分离卷积,从而达到降低计算量的作用。具体来说,给定一个尺寸为 W×H×d 的特征图,而卷积操作设定为 Wc×Hc×d×N ,其中 d 为通道数, N 为卷积核个数。假设对应特征图空间位置中的每一个特征点都会进行一次卷积操作,并且生成的新特征图与原有特征图尺寸一致。对于普通卷积操作来说,其总的计算量为:
W×H×Wc×Hc×d×N
而深度可分离卷积的计算量为: Wc×Hc×W×H×d+W×H×N×d (8)
相对于普通卷积,深度可分离卷积与普通卷积的计算量比值为:
1/N+1/(Wc×Hc) (9)
由此可知,DSC 的计算效率优于普通卷积,同时降低了计算量并有效防止过拟合。通过上述计算方式,可以得出替换之后的计算量为使用普通卷积的模型的 76‰
图4 深度可分离卷积流程图
Fig.4 Flowchart of depthwise separable convolution
1.2 基于 DeepSort 的视频行人追踪算法
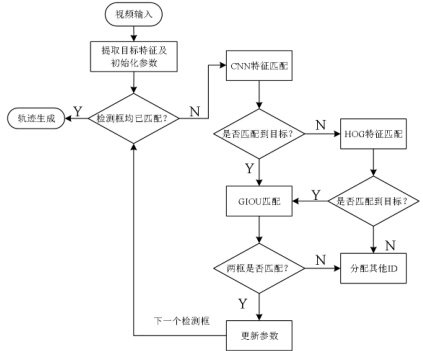
在检测到行人目标之后,需要对目标进行高效且准确的追踪。为了提高追踪算法的鲁棒性,本文在DeepSort 的基础上做改进,设计了多特征候选匹配机制,其主要流程如图5 所示。
图5 追踪算法流程图
Fig. 5 Flowchart of the tracking algorithm
使用向量 Q=[u,ν,r,h,u′,ν′,r′,h′] 来描述目标物在某一时刻的状态,其中 (u,ν) 为目标框的中心坐标, r 和 h 分别为目标边界框的长宽比和高度,其余四个变量为它们的运动速度信息。首
先对起始帧中所有目标物的检测框进行ID 编号,并设置计数器。之后通过使用具有连续速度模型和线性观测模型特点的标准卡尔曼滤波器,对帧中的目标物轨迹状态进行预测,并利用离线的已经预训练的CNN 网络对目标框进一步提取特征,将其提取的特征转换一个长度为128 的向量,将特征信息、固定的ID 以及预测信息关联。
之后,通过匈牙利算法对前一帧中的预测框和当前帧的检测框进行匹配,采用马氏距离描述两者之间的关联程度,如式(10)所示。
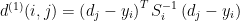
其中 d(1)(i,j) 为预测框和检测框的关联度, dj 为第j 个检测框的状态向量[?,?,?,ℎ], yi 代表第i 个轨迹的预测框, Si 为由卡尔曼滤波器得到的当前时刻的协方差矩阵。选取 8.5 作为阈值,若距离小于等于阈值,则认为关联成功。若大于阈值,则将利用重识别网络,即 CNN 特征,每一个检测框都生成一个长度为128 的特征向量,同时对每一个目标物构建一个确定轨迹的100 帧外观特征向量。通过式(11)计算两者的最小余弦距离。
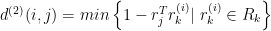
其中 rj 为检测框对应的外观特征向量, rk 代表最近100 帧已成功关联的特征向量, Rk 特征向量库,限制条件为 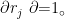 。距离阈值设置为2.5,若距离小于或等于阈值则认为匹配成功,若大于则对目标框内的内容提取HOG 特征,再次通过式(11)的方式进行匹配,此处阈值设置为3.5,如果依旧没有匹配成功,则认为是一条新轨迹,分配不同的ID;如果匹配成功,则和CNN 匹配到的框图一样,通过计算基于广义交并比的代价矩阵对检测框和预测框进行匹配,得到匹配结果。若是全部匹配完成,则使用卡尔曼滤波器更新目标物的下一帧状态。
。距离阈值设置为2.5,若距离小于或等于阈值则认为匹配成功,若大于则对目标框内的内容提取HOG 特征,再次通过式(11)的方式进行匹配,此处阈值设置为3.5,如果依旧没有匹配成功,则认为是一条新轨迹,分配不同的ID;如果匹配成功,则和CNN 匹配到的框图一样,通过计算基于广义交并比的代价矩阵对检测框和预测框进行匹配,得到匹配结果。若是全部匹配完成,则使用卡尔曼滤波器更新目标物的下一帧状态。
采用CNN 特征和HOG 两种特征的候选分级匹配方式,与原有的DeepSort 算法相比,增加了HOG特征的提取,并且由于仅对候选框中进行HOG 特征提取,基本不会额外增加时间成本。通过两种不同类型特征的匹配,提高了鲁棒性,可以有效防止轨迹的遗漏。
2 实验结果与分析比较
2.1 实验环境和数据集
为了验证本方法的可行性和有效性,基于PyTorch 框架进行实验,操作系统为Linux 64 位系统。硬件环境为 3.60 GHz Intel Xeon W-2123 CPU,32GB 内存以及 NVIDIA TITAN RTX GPU。软件环境为Python 3.8,Cuda 10.1 以及 Cudnn 7.4。
模型分别在 PASCAL VOC2012 和 MOT16 上进行训练和测试。PASCAL VOC2012 是一个在计算机视觉领域常用的数据集,MOT16 数据集是在2016 年提出来的用于衡量多目标追踪方法标准的数据集,其目的是将每个目标和其他目标进行区分开来。
2.2 评价指标
行人检测任务的关键在于是否能准确识别视频或者图片中的行人目标,本文选择精度(Precision)与召回率(Recall)作为评价模型性能的指标。
对于追踪任务而言,选择多目标追踪精度(Multiple Object Tracking Precision, MOTP),多目标追踪准确度(Multiple Object Tracking Accuracy, MOTA)以及 ID Switch 来衡量模型对目标物的追踪性能。MOTP 表现为目标位置的偏差程度,即注释框和预测框的对齐程度。MOTA 体现了追踪算法的准确度指标,具体表现为对多个目标追踪的准确度。ID switch 表示追踪器对目标物体改变标号的次数。
2.3 目标检测模块结果分析与比较
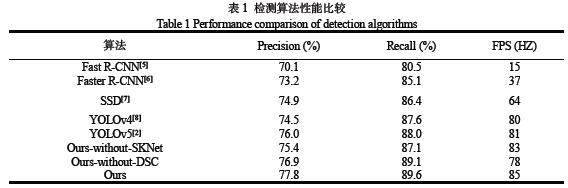
在相同的实验环境及数据集下,分别选取了 Fast R-CNN[5]、Faster R-CNN[6]、SSD[7]、YOLOv4[8]以及YOLOv5[2]等算法作为对比,来证明本算法在行人检测功能上的性能,相关实验结果如表1 所示。对比其他的算法,本算法在精度和召回率上都占优,且得益于使用深度可分离卷积和SKNet,与文献[2]中的 YOLOv5 算法相比,不仅在算法性能上有了一定的提升,而且处理的速度也比基础算法提高了 4.9% ,除此之外,本实验分别对SKNet 和DSC 两个模块分别进行了消融实验,这说明本算法所加入的SKNet 注意力机制可以增强对行人特征的提取,能给模型带来一定的增益;同时证明了本算法,对相关硬件设备的要求也比较低。
2.4 目标追踪模块结果分析与效果可视化
在追踪性能方面的实验上,选取了Sort[9]以及DeepSort[10]作为对比算法,为了体现公平性,都统一使用本文所设计的行人检测网络作为前端的检测工具,且在标准的MOT16 数据集上进行测试。表2 为三个算法的详细实验数据,本算法在经过改进之后,在MOTA 和MOTP 两个实验指标上,相较于其余算法有了较大提升,同时视频的处理速度也几近持平,不增加额外的计算负担。另外,ID Switch的次数明显降低,说明即使目标物特征发生一定的变化,仍可以准确追踪。

为了进一步直观体现本算法在检测和追踪方面的性能,将部分实验结果以视频截图的形式展示出来。图6 显示了当行人目标在画面中发生重叠,或者多个行人目标相互遮挡的情形,从中可以看出本算法依旧能全部识别各个行人并准确分配各自的ID,同时没有发生漏检和错检的情况,给予行人目标的标注框也可以准确地标注行人。
图7 展示了本算法的追踪性能在较为复杂的场景下的性能表现,如图 7(a)中检测到的人物 ID 为196,当此目标在经过障碍物或者其他人物遮挡的情况下,目标物的特征发生变化,一时间未被跟踪算法所捕捉,如图7(b)。但是经过一段时间后,当目标运动出障碍物后,仍然会被模型识别,并准确关联分配原来的ID,如图7(c),由此证明了本算法的鲁棒性。
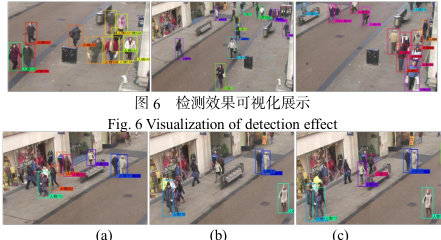
图7 多目标追踪效果可视化展示Fig. 7 Visualization of multi-target tracking effect
3 结语
本文提出了一种高鲁棒的视频行人目标检测与追踪算法,在检测模块中改进了原有的 YOLOv5l检测算法,在特征提取模块中嵌入了 SKNet 注意力机制,更好地突出行人目标的特征,并且将网络中原有的普通卷积替换成深度可分离卷积。在行人多目标追踪模块中,利用CNN 特征和HOG 特征的分级候选机制,可以有效减少漏检的概率。本算法将目标检测模型和追踪模型相结合,克服了画面质量差以及目标物被遮挡的问题,同时兼顾了时效性,对硬件设备要求不高,可以大规模部署在各种交通监测系统中,满足大众对行人智能交通的需求。
参考文献
[1] 马永杰,程时升,马芸婷,等.卷积神经网络及其在智能交通系统中的应用综述[J]. 交通运输工程 学报, 2021, 21(04): 48-71. MA Y J, CHENG S S, MA Y T, et. al. Review of convolutional neural network and its application in intelligent transportation system[J]. Journal of Traffic and Transportation Engineering, 2021, 21(04): 48-71.
[2] Yan B, Fan P, Lei X, et al. A real-time apple targets detection method for picking robot based on improved YOLOv5[J]. Remote Sensing, 2021, 13(9): 1619.
[3] Li, X, Wang, W., Hu, X., et al. Selective kernel networks[C]//Proceedings of the IEEE/CVF Co-nference on Computer Vision and Pattern Recognition. Long Beach: IEEE Press, 2019: 510-519.
[4] HAASE D, AMTHOR M. Rethinking Depthwi-se Separable Convolutions: How Intra-Kernel Correlations Lead to Improved MobileNets[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE Press, 2020: 14588-14597.
[5] GIRSHICK R. Fast R-CNN[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago: IEEE Press, 2015:1440-1448.
[6] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137-1149.
[7] WEI L, DRAGOMIR A, DUMITRU E, et al. SSD: Single Shot MultiBox Detector[C]//Proceedings of the 2016 European Conference on computer vision. Amsterdam: Springer Press, 2016: 21-37.
[8] LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature Pyramid Networks for Object Detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE Press, 2017: 2117—2125.
[9] BEWLEY A, GE Z, OTT L, et al. Simple Online and Realtime Tracking[C]//Proceedings of the 2016 International Conference on Image Processing. Phoenix: IEEE Press, 2016: 3464-3468.

 京公网安备 11011302003690号
京公网安备 11011302003690号


