



- 收藏
- 加入书签

基于Redis 分布式锁的多线程数据同步机制研究与实现
摘要:在分布式系统中,数据同步是确保系统一致性、稳定性与高可用性的核心环节。尤其在多线程并发写入场景中,如何实现高效同步、控制写入顺序,并避免数据冲突、遗漏或重复,成为关键技术难点。针对高并发数据写入中存在的一致性控制与容错问题,提出了一种基于 Redis 分布式锁的多线程数据同步机制。该机制通过线程池调度模型、Redis 锁保护共享写入边界、Elasticsearch 批量写入策略以及失败重试与指数退避策略的组合,实现了高并发、强一致、可容错的数据写入流程。最终通过工程实践验证了系统在写入性能与数据一致性方面的良好表现。
关键词:Redis 分布式锁;多线程同步;数据一致性;Elasticsearch ;批量写入
引言
随着信息技术的迅猛发展,分布式系统已广泛应用于大规模数据处理、实时计算与高可用服务架构之中。在此背景下,数据同步机制成为保障系统稳定性、数据一致性与实时性的重要基础。特别是在多线程并发写入场景中,系统需在性能与一致性之间实现平衡。不当的并发控制往往会导致数据重复、冲突、覆盖,甚至丢失,严重影响业务系统的准确性与稳定性。
Elasticsearch(ES)作为一款高性能的分布式检索与分析引擎,在日志分析、监控系统等领域得到广泛应用[2]。尽管其支持如 Bulk API 等高效批量写入接口,但在实际工程实践中,如何在多线程并发环境下安全、高效地组织数据写入策略,依然面临挑战。常见问题包括写入顺序错乱、数据冗余、边界重复等,尤其当缺乏有效同步机制时问题尤为突出。
针对这一问题,本文提出一种基于 Redis 分布式锁的多线程数据同步机制 ,结合线程池调度、批处理、失败重试与指数退避等策略,有效实现了数据同步过 过对写入边界的加锁控制,避免线程间处理范围重叠,同时提升了在高并发环境下 率与稳定性。本文将在此基础上详细探讨该机制的设计原理、实现方法与工程应用效果,为构建高可用、强一致的数据同步系统提供可行方案。
一、相关研究与技术基础
1.1 分布式锁机制
在多线程或多进程并发访问共享资源的场景中,锁机制是保证数据一致性和完整性的基本手段。在单机环境中,线程锁(如 Python 中的 threading.Lock)可以有效管理资源竞争。然而,在分布式系统中,由于进程可能分布在多个节点,传统的本地锁机制无法满足跨节点资源同步的需求,分布式锁应运而生 [4]。常见的分布式锁实现方式包括:
基于数据库的锁:通过数据库表中的某些字段作为锁标记进行互斥控制,优点是实现简单,但性能较差,数据库压力大,不适合高并发场景[1] ;
基于Zookeeper 的锁:Zookeeper 本身具有强一致性,通过临时有序节点和watch 机制实现可靠锁控制,适用于高可用场景,但部署和维护复杂;
基于Redis 的分布式锁:通过 Redis 的原子操作(如SETNX、EXPIRE、DEL)实现轻量级分布式锁,具备高性能和较强实用性,适合处理并发访问中的短时互斥控制[3]。
本文采用 Redis 作为分布式锁的实现基础,其主要优势在于部署简便、访问速度快、支持多种语言客户端,且可通过过期时间防止死锁。Redis 锁的一般实现会包含三步操作:加锁(set if not exists)、设置锁超时防止死锁,以及解锁时的原子性保障(防止误释放其他线程锁)。
1.2 多线程数据处理技术常用的多线程处理机制包括:
线程池(ThreadPoolExecutor):将线程的创建与销毁操作托管于线程池,避免频繁创建开销,提高资源利用率;
任务调度(Submit+Future):通过任务提交与回调机制实现对线程执行状态的监控与异常捕获;
本文在设计中引入 ThreadPoolExecutor 实现线程调度,同时通过 Redis 分布式锁控制共享变量的访问,确保多个线程在数据分批处理过程中互不干扰、顺序正确、边界清晰,避免了重复处理或数据遗漏的风险。
共享变量管理:多线程访问共享变量需配合锁机制使用,防止出现竞态条件与数据不一致问题。
. 字段过滤:剔除无关字段(如调试日志、临时状态),仅保留业务必要属性;
1.3Elasticsearch 数据写入策略
Elasticsearch 是基于 Lucene 的分布式搜索与分析引擎,支持对大规模数据的实时存储、搜索与分析操作 [5]。在写入数据时,ES 提供了多种API,其中bulk 接口是实现高效写入的核心手段之一。
Elasticsearch 的写入性能依赖于以下几个因素:
批量写入(Bulk API):允许将多个操作(如 index、update、delete)合并为一个请求,减少网络开销与节点间交互时间;
写入顺序控制:在并发写入场景中需保证批次数据边界清晰,避免数据顺序错乱;
资源配置:如写入线程数、刷新间隔(refresh interval)、副本设置等,也会直接影响写入性能;
失败重试策略:ES 写入过程中可能因网络抖动、节点负载等原因失败,需设计异常捕获与重试机制功率。
在本文中,使用 bulk 接口对格式化后的数据进行批量提交,配合时间记录与异常日志输出,实现对写入过程的全程追踪。同时,引入失败批次记录与指数退避重试机制,提升系统的容错能力和写入稳定性。
二、系统设计与架构
为应对高并发数据写入过程中存在的并发冲突、资源竞争与写入失败等典型问题,本文设计并实现了一种基于Redis 分布式锁机制与多线程调度策略融合的数据同步系统。该系统以“并发处理、高一致性、强容错”为核心目标,围绕数据提取、写入边界同步、批量处理与故障回溯等关键环节构建完整的技术闭环,旨在实现高并发场景下的数据高效写入与一致性保障。
与传统串行写入机制或仅依赖线程池调度的方案相 ,本文提出的机制在以下两个方面具有创新性与实用价值:一方面,采用基于 Redis 的分布式锁作为 制,有效避免了线程间共享变量访问时可能产生的数据重叠、遗漏或顺序错乱问题;另 方面,通过将线程池调度与分布式锁粒度控制结合,实现了处理单元的并行分发与全局同步控制的有机统一,提升了系统的并发能力与可控性。
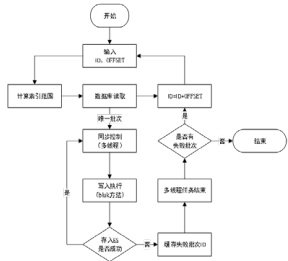
本章将从系统整体架构出发,依次介绍系统的功能分层、关键模块职责及其设计逻辑,全面展示该数据同步机制的结构性设计与工程实现路径, 如图1 所示。系统整体结构划分为以下四个功能层次,各层协同配合、职责分明:
1) 数据读取层
该层负责从业务数据库中批量提取待同步的数据记录,并对其进行结构标准化与预处理(如时间字段转换、字段拼接、异常过滤等)。为应对大规模数据量带来的性能挑战,系统放弃传统 OFFSET 分页方案,转而采用基于主键ID 的范围查询策略(如id=batch_id),以充分利用数据库索引,提高查询效率并降低主库压力。
2) 同步控制层
该层为整个系统的数据一致性提供保障。系统利用 Redis 提供的原子操作封装为线程间互斥的分布式锁机制,实现对关键共享变量(如end_id)的独占访问控制。每个线程必须在获取锁后才能推进数据处理边界,完成任务后自动释放锁,从而保证所有线程处理的数据区间无重叠、不遗漏,实现对“处理范围”的串行化保护
3) 写入执行层
该层由线程池调度多个并发线程对提取数据进行结构化转换,并封装为符合 Elasticsearch Bulk API 格式的批量请求体进行写入。通过设置合理的数据块大小 如每批 5000 条)与并发度(线程数),系统可显著减少与Elasticsearch 的通信开销,提升写入吞吐量。同时,写入前对数据执行清洗与 JSON 序列化,剔除非必要字段,确保结构合法性与索引效率。
4) 容错与回溯层
为提高系统的鲁棒性,系统引入失败批次记录与自动重试机制。当某批次写入 Elasticsearch 失败时,系统仅记录该批的起始 ID(避免内存占用过大),并在主线程阶段统一触发补偿重试流程。重试逻辑采用指数退避策略,通过逐次延长重试间隔(如2s、4s、8s...),控制请求频率并提升写入成功率,避免因集中重试造成系统瞬时过载。
3.1Redis 分布式锁控制机制
Redis 提供的原子操作支持轻量级分布式锁实现,是高并发场景下控制共享资源访问的常见手段。系统采用SETNX(SET if Not eXists)指令确保锁的互斥性,并结合 EXPIRE 设置锁的超时时间(如 15 秒),防止因进程崩溃或网络异常导致的死锁问题。此外,通过 Lua 脚本保证锁的获取与释放操作的原子性,避免因客户端异常导致的锁泄漏。
锁的管理采用上下文管理器(Context Manager)模式,确保无论业务逻辑是否抛出异常,锁都能被正确释放。锁的粒度控制在“数据边界推进”环节,即多个线程竞争更新全局end_id 时加锁,而在实际数据处理阶段无锁运行,以平衡并发效率与数据一致性。
3.2 多线程调度与数据边界控制
系统采用动态线程池模型,主线程根据数据总量和单批次处理量(如 5000 条)计算所需线程数,并启动对应数量的工作线程。每个线程通过互斥锁(Mutex)访问共享变量end_id,确保数据分片无重叠或遗漏。线程每次获取end_id 后,立即递增其值,形成连续的数据处理区间(如 [start_id,end_id])。
多线程是一种常见的并发处理方式,广泛应用于高性能系统的数据处理场景中。合理利用多线程技术可以显著提高数据处理的吞吐量,减少同步时间,提升系统的响应能力。
主线程通过 Thread.join 监控所有子线程的完成状态,并捕获异常。若某线程因数据异常或网络问题失败,系统记录其处理区间,并在所有线程完成后触发补偿机制,如重试或写入死信队列(Dead Letter Queue)。该设计既保证了高吞吐量,又具备容错能力。
3.3 数据结构化与批量写入机制数据写入前需经过标准化处理:
2. 格式转换:统一时间戳为ISO 8601 格式,数值类型转为标准JSON 数值;
3. 数据裁剪:对长文本字段(如content)截断至合理长度(如1000 字符)。
批量写入采用 Elasticsearch 的 Bulk API,每条数据由操作头(如 {"index":{"_index":"articles"}})和 JSON 数据体组成,通过换行符拼接为文本块。相比单条写入,批量提交减少网络往返开销,写入性能提升约10–20 倍(实测5000 条 / 批次时吞吐量达 5w docs/sec)。
系统维护一个失败队列(Failed Queue),仅记录失败批次的数据批次 id(如 start_id、batch_size、error_code),而非原始数据,避免内存膨胀。重试策略采用指数退避(Exponential Backoff):
3.4 失败重试与指数退避机制
1. 退避公式:delay=base_delay*(2^(attempt-1)),其中 base_delay=2s ;
Storm)。
2. 最大尝试次数:6 次,总等待时间约 126 秒(2+4+8+16+32+64);
3. 最终处理:仍失败则写入持久化日志,供人工干预。
该策略有效应对瞬时故障(如网络抖动、ES 集群短暂过载),同时避免因频繁重试导致的“重试风暴”(Retry
四、优势与创新点
基于上文中提到的核心机制设计与实现细节,本节总结了机制的优势与创新点,主要分为如下三点:多线程共享状态一致性、分布式锁竞争与释放策略、容错能力与极端场景应对。
4.1 多线程共享状态一致性
高并发线程共享变量 end_id 控制当前写入边界,若未加锁控制,极易发生重复写入、遗漏、乱序等问题。系统通过 Redis 锁串行推进边界,确保每个线程处理的 ID 区间唯一且不交叉,满足批次级别的数据一致性要求。在第三章的锁机制基础上,本节从策略角度分析一致性保障的层次化设计:
1. 原子层:通过 Redis 锁的原子操作(SETNX+EXPIRE)确保 end_id 更新的互斥性;
2. 批次层:每个线程处理固定大小的数据区间(如 5000 条),区间边界由锁严格保护,批次内允许无锁并发处理;
3. 语义层:通过 Elasticsearch 的 _id 去重和版本号(_version)机制,最终保障数据幂等性。
策略创新点:相比于传统锁方案,采用 乐观并发控制 (Optimistic Concurrency Control)思想,仅在关键边界(end_id 更新)加锁,减少锁竞争开销,有效优化资源利用率问题。
4.2 分布式锁竞争与释放策略
系统通过 SETNX 实现原子加锁,设定超时时间防止死锁。锁释放使用上下文托管方式确保线程异常退出时也能安全释放,具备幂等性验证,防止其他线程误释放锁资源。
系统内置失败重试机制已涵盖大多数故障情形。对于极端情况,如多次失败、ES 索引不可用、Redis 宕机等,系统设计可扩展补偿机制:
4.3 容错能力与极端场景应对
失败日志持久化:将失败批次ID 和错误信息写入日志或数据库,便于后续人工干预;
幂等性设计:为数据设置唯一写入标识(如自定义_id 字段),避免重复写入;
综上,通过合理设计并发边界推进、分布式锁控制和异常补偿机制,系统在高并发环境下实现了稳定、高效、可恢复的数据写入能力。下一章将从实验角度评估系统在实际运行中的性能表现与稳定性。
补偿任务接口:支持人工或定时任务重新触发失败批次回滚与写入。
本文针对高并发环境下数据同步面临的一致性与性能挑战,设计并实现了一种基于 Redis 分布式锁的多线程同步机制,有效保障了数据批量写入Elasticsearch 过程中的安全性、高效性与稳定性。该机制通过Redis 锁对关键共享状态(如 end_id)进行细粒度控制,并结合边界推进策略与指数退避重试机制,在保证数据无重复、无遗漏写入的同时,显著提升了系统的并发处理能力与容错水平。
参考文献:
[1] 赵 新 平 .MySQL 数 据 库 在 高 并 发 Web 系 统 中 的 优 化 技 术 [J]. 软 件 ,2025,46(03):116-119.Zhao Xinping.
[2] 邵新添 , 陈俊丽 , 张汉举 . 基于 Elasticsearch 的服务器集群监控与评估系统设计 [J/OL]. 计算机技术与 发 展 ,1-9[2025-06-06].Shao Xintian,Chen Junli,Zhang Hanjv.Design of a Server Cluster Monitoring and Evaluation System Based on Elasticsearch.Computer Technology and Development,pp.1–9[Online;accessed 2025-06-06].
[3] 王栋柱 , 王青青 , 陈华林 , 等 . 基于 Redis 的高性能分布式锁设计与实现 [J]. 软件 ,2024,45(06):4-6.WangDongzhu,Wang Qingqing,Chen Hualin,et al.Design and Implementation of High-Performance Distributed Locks Based onRedis.Software,2024,vol.45,no.06,pp.4–6.
[4] 王磊 , 孟利民 . 基于高并发的分布式系统幂等设计 [J]. 计算机测量与控制 ,2022,30(03):234-238+243. DOI:10.16526/j.cnki.11-4762/tp.2022.03.039.Wang Lei,Meng Limin.Idempotent Design for Distributed Systems under High Concurrency.Computer Measurement and Control,2022,vol.30,no.03,pp.234–238+243.DOI:10.16526/j.cnki.11-4762/ tp.2022.03.039.
[5] 亓莹 , 肖哲凯 . 数据库间数据同步批量入库工具分析 [J]. 长江信息通信 ,2024,37(03):165-167.DOI:10.20153/ j.issn.2096-9759.2024.03.048.Qi Ying,Xiao Zhekai.Analysis of Data Synchronization and Batch Insertion Tools between Databases.Yangtze River Information and Communication,2024,vol.37,no.03,pp.165–167.DOI:10.20153/ j.issn.2096-9759.2024.03.048.

 京公网安备 11011302003690号
京公网安备 11011302003690号


