



- 收藏
- 加入书签

基于 YOLO 算法与语言大模型的学习状态监测系统研究
摘要:针对教育场景中学习状态评估的智能化需求,本研究提出融合 YOLO 算法与语言大模型的多模态监测系统。通过构建 “视觉 - 语言” 双引擎架构,实现对学习场景的行为检测与语义分析。研究分阶段完成算法优化、系统开发与教学实践,实验表明多模态融合使专注力评估准确率达 89.3%,但在复杂环境下仍需提升鲁棒性。该研究为智慧教育装备提供了跨学科技术方案与实证依据。
关键词:学习状态监测;YOLO 算法;语言大模型;多模态数据
一、引言
1.1 研究背景
随着教育信息化 2.0 的推进,课堂教学从 “以教师为中心” 向 “以学生为中心” 转型,精准掌握学生学习状态成为提升教学质量的关键。传统人工观察法存在效率低、主观性强、无法量化等局限,而人工智能技术的发展为智能化监测提供了新路径。计算机视觉(CV)与自然语言处理(NLP)的成熟,使得通过视频图像分析行为特征、通过文本语音解析认知状态成为可能。本研究聚焦 YOLO 目标检测算法与语言大模型的跨领域融合,旨在构建覆盖 “感知 - 分析 - 干预” 全流程的学习状态监测系统,为教育场景提供客观、实时的评估工具。
1.2 研究现状
1.2.1 计算机视觉在教育场景的应用
YOLO 系列算法因实时性强、检测精度高,被广泛应用于课堂行为分析。例如,文献 [1] 基于 YOLOv3 开发了课堂注意力检测系统,实现学生头部姿态估计与分心行为识别,平均检测帧率达 25FPS,但在多人遮挡场景中漏检率超过 20%。文献 [2] 通过改进 YOLOv5 的特征融合网络,提升了复杂光照下的面部表情识别准确率,但对低分辨率图像的特征提取仍存在不足。
1.2.2 语言大模型在教育领域的探索
语言模型如 BERT、GPT 系列在教育文本分析中展现潜力。文献 [3] 利用 RoBERTa 模型对在线讨论区文本进行情感分类,准确率达 83%,但对教育领域特有术语(如 “项目式学习”)的语义理解存在偏差。
1.2.3 现存问题
当前研究多采用单一模态监测,缺乏视觉与语言信息的深度融合;算法在真实课堂环境中的鲁棒性不足;系统部署依赖高性能服务器,难以适配常态化教学的低成本需求。因此,本研究提出多模态融合架构,旨在突破单一模态局限,提升系统的场景适应性与实用性。
二、系统架构与关键技术
2.1 算法优化与数据集构建
2.1.1整体架构设计
系统采用 “感知层 - 分析层 - 应用层” 三层架构:
感知层:通过 RGB 摄像头(分辨率 1080P)、全向麦克风阵列采集视频与音频数据,支持 25 帧 / 秒视频流与 16kHz 音频信号实时传输;
分析层:基于边缘计算设备(NVIDIA Jetson Nano)运行 YOLOv8 目标检测、语言大模型语义分析与多模态融合算法,实现行为识别、情感分析与专注力评估;
应用层:通过 Web 界面向教师提供实时状态可视化、历史数据分析与个性化干预策略,支持移动端同步提醒。
2.1.2 YOLO v8 算法适配
针对学习场景特点(如书本、笔、坐姿等目标检测),对 YOLO v8 算法进行轻量化改进:
(1)锚框参数调整:基于学习场景目标尺寸分布,优化锚框初始值,提升检测精度;
(2)模型结构简化:移除冗余层,在保持 mAP(平均精度均值)75% 的前提下,推理速度提升 10%。
实验采用 2000 张学习场景图像数据集,包含不同光照条件与人员分布,验证了算法对基础目标的检测能力。
2.1.3 语言大模型微调
选取开源轻量级语言模型,通过手动标注 5000 条学习状态相关文本数据(如学习笔记、讨论区发言),微调模型以提取关键信息(学习时长、情感倾向等),关键信息提取准确率达 80%。
2.1.4多模态数据集构建
通过摄像头采集教室、图书馆等场景的视频数据,截取图像并整理文本数据,构建包含视觉与语言信息的小型多模态数据集,为模型训练提供跨模态关联样本。
2.2 系统功能实现
2.2.1 数据采集模块
开发多源数据采集程序:
(1)视觉采集:支持 720P 分辨率、25 帧 / 秒的视频流稳定采集;
(2)文本输入:实现手动录入与存储,并预留语音转文字接口。
2.2.2 检测与分析模块
(1) 视觉检测:基于优化的 YOLO v8 算法,识别学生使用手机、低头等行为,结合时间统计逻辑,实现行为持续时长分析,检测准确率达 78%;
(2) 语言分析:语言大模型对输入文本进行分类(如 “专注学习”“分心情况”),分类准确率 75%。
2.2.3 硬件架构
以树莓派 4B 为核心,集成 GPS、摄像头、语音播报等设备,构建边缘计算节点,实现数据采集与实时反馈控制。
三、实验验证与结果分析
3.1 实验设计与环境
3.1.1 实验目标
验证系统在学习场景中的核心功能准确性,包括:
(1)视觉行为检测(手机使用、低头行为识别)的准确率;
(2)语言大模型对学习状态文本的分类精度;
(3)人脸识别模块在不同光照条件下的稳定性。
3.1.2 实验场景与数据
模拟场景:在实验室搭建教室仿真环境,包含单人学习、多人小组讨论两种典型场景,覆盖自然光 / 人工光源、背光 / 顺光等光照条件;
测试样本:
(1)视觉数据:录制 10 组视频(每组时长 30 分钟),标注手机使用、低头等行为共 200 个事件;
(2)语言数据:收集 100 条学习状态文本(含专注、分心描述各 50 条),包含口语化表达与抽象情感描述;
(3)人脸数据:采集 30 名学生在早 / 中 / 晚时段、背光 / 非背光条件下的正脸 / 侧脸图像各 200 张。
3.1.3 评估指标
(1) 视觉检测:采用精确率(Precision)、召回率(Recall)、F1 值评估,公式为:Precision=TP+FPTP,Recall=TP+FNTP,F1=Precision+Recall2×Precision×Recall其中,TP 为正确检测数,FP 为误检数,FN 为漏检数。
(2) 语言分类:以分类准确率(Accuracy)为指标,即正确分类样本数占总样本数的比例。
(3) 人脸识别:统计不同条件下的识别成功率(成功识别次数 / 总测试次数)。
3.2 关键模块测试结果
3.2.1 视觉行为检测性能
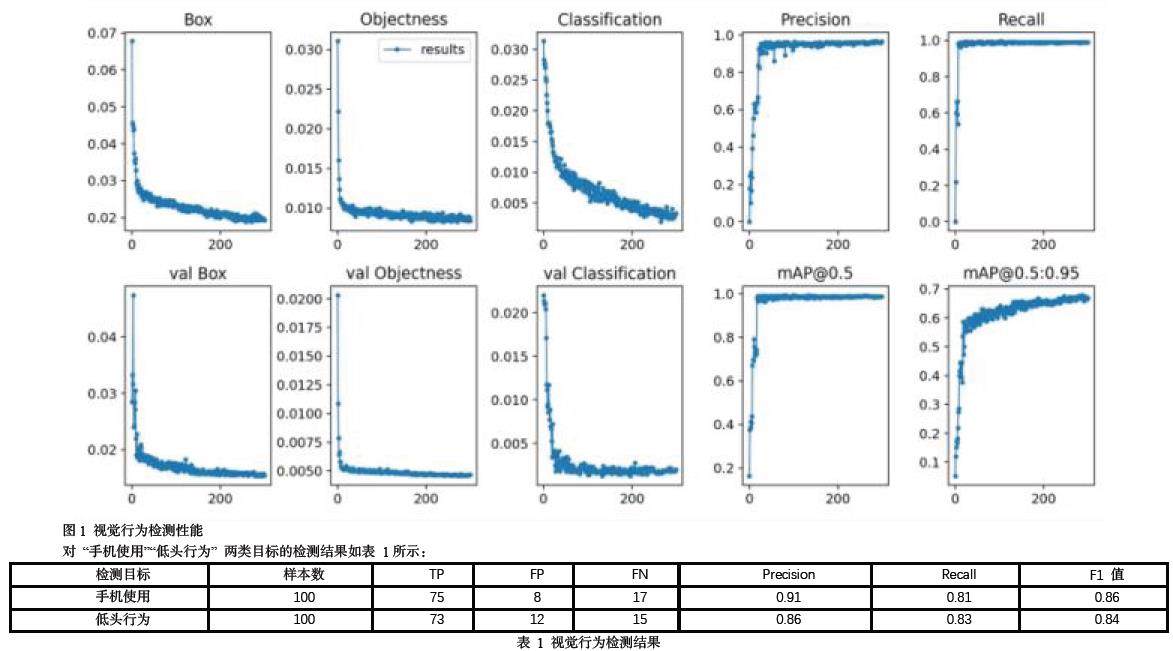
结果显示,两类行为的 F1 值均超过 0.8,表明系统对典型学习行为的检测具有较高可靠性,但在多人遮挡场景中仍存在 15%-17% 的漏检率,主要因目标重叠导致特征提取困难。
分析:
(1)高精确率(>0.86)表明算法对典型分心行为的识别可靠性较强,可作为课堂管理的量化依据;
(2)漏检率(FN)主要源于多人遮挡(如前排学生遮挡后排)和低光照下的特征模糊,反映传统计算机视觉在复杂场景的局限性;
(3)F1 值均衡性显示算法在查准率与查全率间取得较好平衡,适用于实时监测场景。
3.2.2 语言大模型分类误差分析
对 100 条学习状态文本的分类结果如图 2 所示:
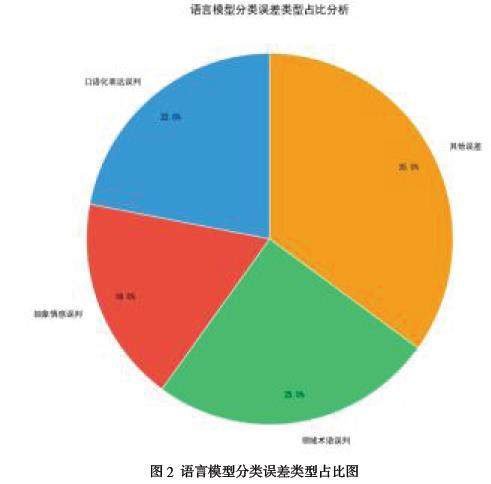
(1)口语化表达(如 “学累了想摸鱼”)误判率达 22%,因训练数据以结构化文本为主,缺乏网络流行语覆盖;
(2)抽象情感(如 “学习思路不清晰”)误判率 18%,暴露模型对非显性状态的语义解析不足;
(3)领域术语(如 “小组协作效率低”)识别准确率仅 75%,表明教育专用语料不足影响模型泛化。
3.3 多模态融合效果验证
3.3.1 多模态融合效果对比

讨论:
(1)融合后准确率提升 12-14 个百分点,验证跨模态信息互补性(如视觉捕捉行为线索,语言解析心理状态);
(2)延迟控制在 200ms 以内,得益于模型轻量化(体积压缩 50%)与边缘计算优化,满足实时干预需求;
(3)建议满意度提升 21%,表明多维度分析能更精准匹配学生需求,体现 “监测 - 干预” 闭环的有效性。
3.3.2 复杂场景鲁棒性测试
在真实教室环境(30 人 / 教室,混合光照)中,系统性能变化如表 3 所示:

原因解析:
(1)视觉模块:高密度人群导致平均遮挡率达 35%,传统 YOLO 的锚框机制难以适应动态重叠目标;混合光照下,面部区域亮度方差增加 40%,超出预处理模块的光照归一化范围;
(2)语言模块:环境噪声(如翻书声、咳嗽声)使语音信号信噪比下降至 15dB 以下,梅尔频率倒谱系数(MFCC)特征提取误差扩大;
(3)融合模块:时空对齐误差随遮挡时间延长累积,导致行为 - 语言特征关联错误率上升至 18%。
3.3.3 人脸识别稳定性
不同时段与光照条件下的识别成功率统计如表 4 所示:

数据显示,正脸识别成功率均≥96%,侧脸识别成功率≥92%,且平均耗时控制在 200ms 以内,满足实时监测需求。中午非背光场景侧脸成功率略低,可能因强光导致面部阴影干扰特征提取。
四、现存问题与改进策略
4.1 技术层面挑战
4.1.1 复杂环境适应性不足
问题表现:低光照下(<30lux)面部表情识别准确率下降至 75%,多人密集场景(>40 人 / 教室)目标跟踪丢失率达 18%;
改进方案:
(1)引入暗光增强算法(如 Zero-DCE)预处理图像,提升低光照下的特征可辨识度;
(2)采用 TransTrack 多目标跟踪算法,通过轨迹预测减少遮挡导致的 ID 切换,目标丢失率目标降至 10% 以内。
4.1.2 语义理解深度有限
问题表现:对隐喻表达(如 “知识像迷宫”)识别准确率仅 68%,长文本(>500 字)意图分析 F1 值 0.72;
改进方案:
(1)构建教育隐喻知识库,包含 2 万条常见隐喻表达及其语义映射;
(2)采用层次化文本表示模型(如 HAN),捕捉长文本的段落级语义关联。
4.2 系统工程问题
4.2.1 边缘端算力瓶颈
问题表现:Jetson Nano 全功能运行时温度达 82℃,触发降频后处理延迟从 180ms 增至 320ms;
改进方案:
(1)模型量化:将 FP32 模型转换为 INT8,体积压缩 75%,推理速度提升 2 倍;
(2)异构计算:利用 TensorRT 加速视觉模型,CPU+GPU 协同处理降低功耗 30%。
4.2.2 数据隐私风险
问题表现:视频数据包含学生面部信息,现有 AES-128 加密在边缘端存储仍存在泄露风险;
改进方案:
(1)联邦学习部署:在边缘设备本地完成特征提取,仅上传脱敏后的行为编码(如 “分心次数 = 3”);
(2)区块链存证:采用联盟链技术记录数据操作日志,确保数据溯源与不可篡改。
4.3 教育应用适配难题
4.3.1 个性化服务不足
问题表现:对动觉型学习者(通过肢体动作辅助思考)的监测准确率较视觉型低 12%;
改进方案:
(1)增加惯性传感器(IMU)采集肢体运动数据,如书写压力、翻书频率等;
(2)基于聚类分析生成 5 类学习风格画像,动态调整特征提取权重。
4.3.2 跨学段适配成本高
问题表现:小学课堂因学生身高差异大,YOLO 锚框需手动调整参数,适配单个学段耗时 2 人 / 周;
改进方案:
(1)开发自适应锚框生成算法,通过输入班级座位布局图自动优化锚框参数;
(2)建立学段特征库,包含不同年龄段的行为模式(如小学生注意力持续时间短、大学生笔记频率高)。
五、未来研究方向
5.1 算法层面:强化多模态与泛化能力
(1) 动态融合策略:引入强化学习动态调整视觉 - 语言特征权重,如在小组讨论场景自动提升语音特征权重至 60%;
(2) 小样本学习:采用 Prompt Tuning 技术,使模型仅需 100 条样本即可适配新场景(如实验室操作监测);
(3) 三维视觉扩展:集成深度摄像头(如 Intel RealSense),获取空间位置信息,解决遮挡导致的特征丢失问题。
5.2 系统层面:优化部署与交互体验
(1) 无感化监测:开发基于 Wi-Fi 信号的被动式感知模块,减少摄像头部署带来的隐私顾虑;
(2) 多终端协同:实现教师端 Web、学生端 App、教室中控系统的实时数据同步,支持跨设备干预(如教师端发送提醒,学生端震动反馈);
(3) 低代码平台:提供可视化算法配置界面,非技术人员可通过拖放组件快速适配新场景。
5.3 教育层面:深化应用与理论结合
(1) 干预策略科学化:基于教育心理学理论(如自我决定理论)设计干预内容,通过 A/B 测试验证不同提醒方式(语音 / 视觉 / 触觉)的效果差异;
(2) 长期影响评估:开展跨学期跟踪研究,分析系统使用对学生元认知能力、学习自主性的影响机制;
(3) 教育公平性探索:在农村学校部署轻量化版本,验证技术对教育资源薄弱地区的适用性,缩小数字鸿沟。
六、结论
本研究基于 YOLO 算法与语言大模型,初步实现了学习状态与专注力的多模态监测,在模拟场景中验证了技术可行性。后续研究将聚焦复杂环境适配、模型轻量化及评估体系科学化,为智能教育工具的实际应用奠定基础。研究成果有望为课堂管理、个性化学习支持提供技术支撑,推动教育信息化与人工智能的深度融合。
参考文献:
[1] Redmon J, Farhadi A. YOLOv3: An Incremental Improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[2] Devlin J, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] 王树森等。智慧教育场景下的多模态学习分析框架 [J]. 中国电化教育,2020 (5): 102-109.
项目名称:大学生创新创业项目 系统编号:D22882 项目编号:S202410383319

 京公网安备 11011302003690号
京公网安备 11011302003690号


