



- 收藏
- 加入书签

探究多元统计分析在R语言中的优化可能
 打开文本图片集
打开文本图片集
摘要:在大数据时代来临的背景下,对于数据分析尤其是多元统计分析的需求逐步提升。因此,分析软件的发展与优化日趋明显,在几个极具代表性的数据分析软件当中,R语言作为早期就存在且仍不断发展的S(statistic)语言,其开源的特性和优秀的能力在当下仍然适用。而在这个高楼大厦的底端不免的随着时代的发展暴露出许多问题,我们就这些问题提出优化和改良的实验与试想,期望R语言在未来仍位居分析软件的前列。
关键词:R语言;多元统计分析;优化
Abstract:With the advent of the era of big data, the demand for data analysis, especially multivariate statistical analysis, has gradually increased. Therefore, the development and optimization of analysis software are becoming more and more obvious. Among several representative data analysis software, R language, as an early existing and still developing s (statistical) language, its open source characteristics and excellent ability are still applicable at present. At the bottom of this high-rise building, many problems are inevitably exposed with the development of the times. We put forward experiments and ideas for optimization and improvement on these problems, and hope that R language will still be in the forefront of analysis software in the future.
Key words:R language; Multivariate statistical analysis; optimization
一、引言
多元统计分析是统计学中极为重要的分支,其优秀的数据处理、分析能力在各类科学、经济学中表现突出,尤其是在20世纪的当下,他成为了处理大数据问题的一个非常重要的统计工具。同时纵观数十年来的市场,已拥有多种此类统计分析能力的软件应用在各领域。我们分别对现有的资料查询,发现在 SAS、R 语言、SPSS、Stata 等常见的统计软件中,R 语言是十分适合作为教辅软件[1],以供广大读者使用与学习的,因此就R语言在该方面的领域中的改良发现了些许可能。
二、概况:
R语言在分析数据时虽然功能完善,操作便携,且R与多元统计分析被广泛地应用到各个学科和生产当中。在信息化时代的背景下,多元统计分析还能与数据库技术相结合,使得海量数据的处理效率大大提升[2]。但在其算法的底层逻辑中,仍存一些繁琐的问题以待处理,接下来笔者会一一说明使用R语言会有哪些已知的缺点及对于这些缺点如何处理做出探究与猜想。
三、R语言的不足之处
1.数据处理:
R在数据处理时,会以大量已安装的R包作为基础框架进行构建,随后载入分析再处理,如果这些R包的版本不一致便会频繁报错,同时由于版本的更迭,其运行的稳定性较难把握,兼容性也随之变差;这与其他类型的编程语言形成了较强的对比。相较于拥有同类功能的python时,R会使用更多的内存,甚至会出现需要自己编写R包载入的情况出现,从而浪费大量的时间。如果这个时候我们需要处理一些大数据,选择R并不理想。
2.语言复杂度:
R语言的命令语句的格式和种类非常的众多,使用者需要通过一定的时间的学习才能掌握其具体的使用方法[3]。对于没有预备知识或编程经验的人来说,学习成本较高,学习曲线较为陡峭。在学习R语言时,除了需要掌握R自身的编程结构与技巧,还需要对使用的R包有明确的定位和个人理解。当我们想要用R语言来进行一些大数据分析时,不免的要调用许多读者并不了解的R包来使用。这就要求使用者必须花费诸多的时间来学习和掌握。
3.运行速度:
R语言相较于其他编程类语言(如前文提到的MATLAB),速度缓慢,往往在高强度的运行环境下不堪重负,这一点在下载R包的时候更为突出。同时在处理部分实际问题时缓慢且可能出错。
这是笔者对某个1201x7的表格的数据处理,特地使用了不同版本的R包进行分析,尝试一次性生成大量图形时发生的错误结果(仍然生成了结果图)。由于报错与警告超过50个,几乎没有办法一一解决并分析处理。
四、如何优化和改良
在本小节中,笔者会针对部分问题结合自己的探究与实验做出合理的猜想。尝试对多元统计分析在R语言中实现的优化与改良。
1.利用R包
笔者在前文中提到大量R包的载入使得R语言的学习成本增加,R语言的数据分析也会变得稍许缓慢。然而,Rcpp这个扩展包可以使我们能够利用R和C++的无缝整合来编写C++的代码,这些代码还可以调用R本身的函数,利用已有的R语言的数据结构的优势,我们可以在保留R本身强大的数据操作功能时,编写出高性能的代码。
已知现如今C/C++语言在编程类语言的使用当中排名第二,C/C++语言同时也是许多当代大学生入门编程时的第一语言,所以在学习成本这一方面无疑是省下了大量的时间,根据自身已有的经验便可以利用C/C++自身的优势写入和调用R语言及其本身的函数。轻松实现其与R语言的交互。
由于它是被编译为本地的指令,比R语言这样的脚本语言更接近于硬件级别。所以C++的代码的运行速度通常来说是比较快的,当我们使用C++的代码来替换某些繁琐的语言逻辑时,可以更快速的运行和处理,充分的解决了R语言这一部分的尴尬处境,使用户在处理大量数据时提高了效率,更是减少了软件卡死闪退的可能性。
这里拿菲波那切数列举例说明,由于该数列在R语言中的实现方法有多种,笔者在这里只例举其中的一种写法:
F <- function(n){
x <- c(1,1)
for(i in 1:n)#采用for循环
{
x[i+2] = x[i+1] + x[i]
}
print(x[1:n]) #print(x[n])直接输出数列第n项
}
F(13) #输出数列前13项,这里也可以改成其他的数字
如果利用Rcpp这个扩展包则可以这样设置:
#include "Rcpp.h"
// [[Rcpp::export]]
int fibonacci(const int x) {
if (x < 2) return(x);
return (fibonacci(x - 1)) + fibonacci(x - 2);
}
/***R
system.time(print(fibonacci(30))) */
这里我们将R语言的实例用法也放在了C++的文件后,速度的变化仍然可以体会到。
2.用外部程序调用执行
R语言本身作为编程类工具,其本身不仅仅是可以作为多元统计分析、教学的工具,仍然是优秀的计算机编程语言。在此基础上,如果我们仅仅只使用它的部分模块,或许能极大的优化数据分析这一部分的运行速度,从而提升整体的速度。
这里笔者举两个简单例子,第一个是用户群体较多的C语言调用方法,它可以调用同类或者是尾缀为EXE的可执行程序等等。
#include<stdio.h>
#include<stdlib.h>
int main(void)
{
system("name.r");//调用名字为name的可执行的R文件
return 0;
}
这里只需要提前准备好一个名字叫做name的R文件就可以直接调用并输出在电脑屏幕上,
从而方便了我们直接打开所需要的文件或者是程序,在操作步骤上,省去了查找的时间,同时替代了例如传统的使用快捷方式调用软件程序的办法。
第二个则是java的调用模块,当我们配置好相应的环境后,输入以下代码;
import java.io.IOException;
/**
* @auther heihao
* @creater 2022-03-19 21:30
*/ //这是笔者使用的IDEX软件自带的头文件部分
public class Test {
public static void main(String[] args){
// 创建一个runtime对象。
Runtime run = Runtime.getRuntime();
// 接着通过exec调用执行我们的exe程序。
try {
// 处理异常
Process process = run.exec("路径"); //这里的路径为需要调用的文件(软件)路径
} catch (IOException e) {
e.printStackTrace();
}
// 接着进入命令窗口,通过javac编译我们的test程序。
}
}
上述代码同样是可以替代了传统的打开文件的方式,节省了部分时间,一定程度上提升了软件的运行速度。值得注意的是,在使用R语言的编译软件时,它还含有诸如Rstudio、Rtools等工具,由于Rstudio是一个提供具有很多功能的免费提供的开源集成开发环境(IDE),它的存在使R本身更加容易使用。因此我们在调用的过程中,可以尝试只调用Rstudio处理数据的那一部分。通俗来说,就是绕过繁琐的中间过程,输入数据,输出我们需要的结果。而这个结果可以是图形,预测建议等多种表现形式。总之,如果将中间过程整合成至运行界面舞台的后面进行打包处理,我们只需要调用这个“中间过程”并输入待处理的数据,便可以直接得到我们所需要的结果了。
而关于这个中间过程是什么,怎么去实现,笔者根据目前的实验结果认为:编译环境本身是仍是存在且需要的,它是运算分析的根本。我们只是让它不显示在计算机的界面上,其仍然在后台按照原先的程序运行。从目前已有的资料和分析,这是可行且存在的;然而,关于如何把Rstudio或者R语言的一系列分析工具嵌套在别的调用程序或软件中,笔者能力有限,还无法得知。仅仅就这一问题提出猜想,希望能给读者带来一些启发。
五、改良后多元统计分析的相关体现及试想
多元统计分析中各种方法有一个共同特点:初始数据、中间结果和最后结果数据量大,计算过程繁杂[4]。所以我们用现有的条件,对相关领域在优化后的作用作出部分总结及试想。
多元统计分析——线性回归,线性回归是利用线性回归方程中的一种最小平方函数一个或多个自变量X对一个因变量Y的影响关系情况。这种函数可以是一个或多个称为回归系数的模型参数的线性组合。在多元回归分析中,如果因变量和多个自变量的关系为线性时,就属于多元线性回归。在线性回归中,数据使用线性预测函数来建模,这些模型也因此被叫做线性模型,最常用的线性回归建模是给定X值的y的条件均值是X的仿射函数。并且未知的模型参数也是通过数据来估计,因此在线性回归分析中,最重要的就是数据的分析。不太一般的情况,线性回归模型可以是一个中位数或一些其他的给定X的条件下y的条件分布的分位数作为X的线性函数表示。在模型中我们通常需要用最小二乘法来逼近拟合,在此过程中,我们可以提前将二乘法函数写入,在编程中利用C/C++算法效率较高的特性,加入计算包做基层架构,在此基础上进行相关性检验,使用者使用R做分析图时,直接导入数据,并调用提前写好的函数,此过程使得在应用中效率得到提升。
另外从一元线性回归说起,回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。其基本形式为:Y=a * X + b。需要做到的是拟合训练集数据找出合适的参数a , b,确定方程式,用于预测未知的样本。
如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
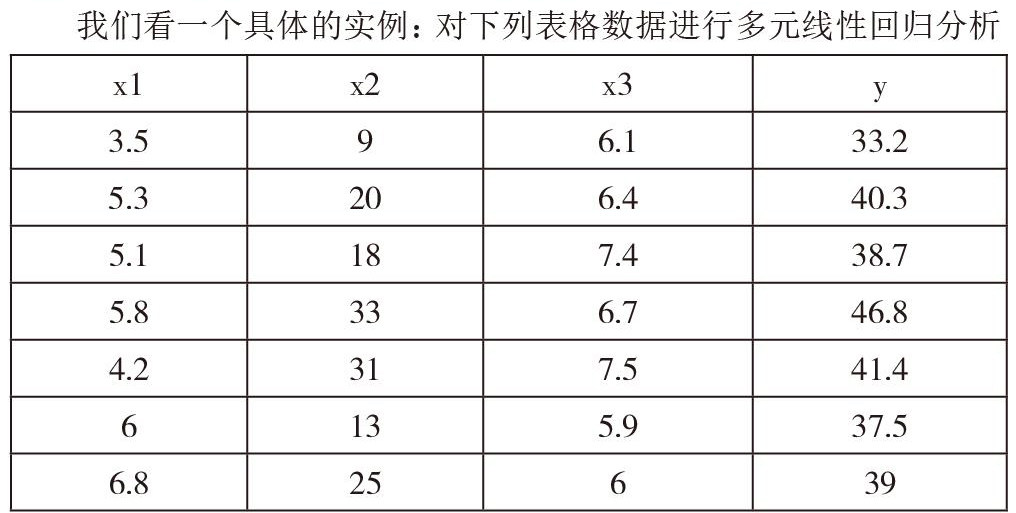
我们看一个具体的实例:对下列表格数据进行多元线性回归分析
模型建立:
首先控制因变量:如果找到了X1和X2之间的***回归方程,那么控制X1,就可以控制X2。
预测因变量:如果找到了X3与Y的回归关系,就可以根据X3来估计Y。
我们不妨设Y=β0+β1X1+β2X2+β3X3+F
βj(j=1,2,…,k)称为回归系数(regression coefficient)。
我们将三组观测数据代入,得到多元线性回归模型:
上式中X也称为设计矩阵
对损失函数求导并令其为0可解得参数
参数β的最小二乘法估计β是使得误差平方和达到最小量,得到方程组的解。
·用最小二乘法求回归系数的过程中,并不一定知道Y与自变量x1,-,X,是否有线性关系
·若不存在线性关系,则得到的回归方程是毫无态义的
·在一元回归中,若β=0,则认为丫并没有随x的变化而线性的变化:
·在多元回归中,对回归方程的显著性的假设检验为:Ho:β1=…=βp=0<一>H1:至少有一βi不等于0。
显著性校验:
回归系数的显著性校验我们直接使用函数,置信区间我们设为95%
计算出对应4个检验值,R?检验值、F检验值、p、绝对误差的方差s
四个值分别为0.9131 70.0454 0.0000 2.9868
其中0.9131接近1,70.0454很大,0.0000<0.05,可知道回归模型
Y=β0+β1X1+β2X2+β3X3+F成立
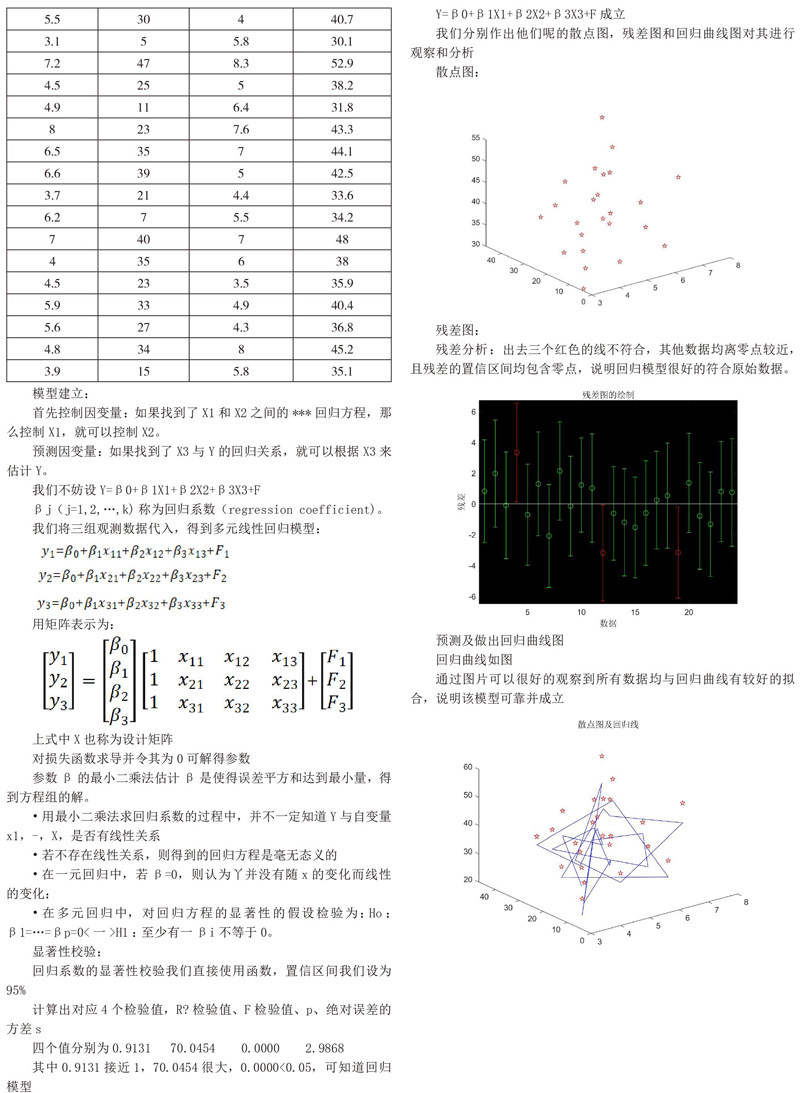
我们分别作出他们呢的散点图,残差图和回归曲线图对其进行观察和分析
残差分析:出去三个红色的线不符合,其他数据均离零点较近,且残差的置信区间均包含零点,说明回归模型很好的符合原始数据。
通过图片可以很好的观察到所有数据均与回归曲线有较好的拟合,说明该模型可靠并成立
多元统计分析——判别分析,是一种统计判别和分组技术,就一定相关数量的数据的一个分组变量以及其他多元变量的已知信息,确定分组与其他多元变量信息所属的样本进行判别分组。判别分析的特点是根据已掌握的、历史上每个类别的若干样本的数据信息,总结出客观事物分类的规律性,建立判别公式和判别准则。当遇到新的样本点时,只要根据总结出来的判别公式和判别准则,就能判别该样本点所属的类别。同样地,根据所需数据的性质不同以及需求同其判别方法也不尽然相同,针对不同的情况数据判断也需要不同的函数进行判别分析,这就需要搭配多个函数进行完成。在常规的R语言使用调用往往只能一种性质的判别公式函数,因此在进行多组数据判断时是非常麻烦的。我们利用已经做好的R包函数,在几个函数中用C++进行整合,使得分散的个体化为一个整体,在判别的过程中便无需反复调用各类R包,各类数据也可一次性进行判别,大大的简化了操作难度,也使得效率得到提升。
以上具体举了两个简单的例子在多元统计分析方面关于R语言上的优化。至于聚类分析、主成成分分析、因子分析、对应分析等,在R的基础上利用了C/C++进行函数优化,一定程度上都弥补了R在这一方面的运行效率的缺点。另外在利用Rcpp,RJava外部编译代码与R嵌套,这种方式使得各类语言之间实现了完整的映射,从诸多方面降低了R的复杂度。
六、结论
R语言最初只是一个统计分析软件包,在统计学和数据处理方面应用广泛。近年来,随着版本的升级和扩展程序包的日益丰富,在优化问题处理方面的应用也逐渐增多[5]。因此本文示例了R语言及其扩展程序包的优化可能与试想,发现R语言在部分方面的优化与改良完全是可行的,甚至是已经有所发展的。那么随着科学的进一步研发,R语言在保持已有的优点上,不断完善、弥补缺点,其所具备的开源、开放等诸多条件仍会使R语言本身位居分析软件的前列。
[1]黎中彦, 陈建超. R语言在《应用多元统计分析》教学中的应用[J]. 大众科技, 2020, 22(9):4.
[2]游士兵, 徐小婷. 统计学方法的发展及其在大数据中的应用[J]. 统计与决策, 2020(4):5.
[3]徐启猛. 交互式R语言开发工具的设计与实现[D]. 吉林大学, 2011.
[4]赵万龙, 徐燕. 用Visual Basic开发体育多元统计分析软件的研究[J]. 体育科学, 2001, 21(2):47-48.
[5]高成强.R语言在几类优化问题中的应用[J].价值工程,2019,38(17):238-240.
作者简介
赵峰(2001.01-),男,汉,安徽人,本科在读,信阳学院全日制在读学生,研究方向:计算机科学与技术。
项目来源:信阳学院大学生校级科研项目
项目编号:2021-DXSLYB-009
项目名称:多元统计分析一软件包
通讯老师:钱建刚

 京公网安备 11011302003690号
京公网安备 11011302003690号


