



- 收藏
- 加入书签

基于Spark RDD的应用实践
 打开文本图片集
打开文本图片集
摘要:Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2010年,伯克利大学正式开源了Spark项目。Shark(Spark SQL的前身)和Spark Streaming,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目。相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升,因此它成为继 MapReduce 之后,最为广泛使用的分布式计算框架。具有使用先进的 DAG 调度程序,查询优化器和物理执行引擎,以实现性能上的保证;同时具备多语言支持,目前支持的有 Java,Scala,Python 和 R;提供了 80 多个高级 API,可以轻松地构建应用程序;支持批处理,流处理和复杂的业务分析;丰富的类库支持:包括 SQL,MLlib,GraphX 和 Spark Streaming 等库,并且可以将它们无缝地进行组合;丰富的部署模式:支持本地模式和自带的集群模式,也支持在 Hadoop,Mesos,Kubernetes 上运行;支持访问 HDFS,Alluxio,Cassandra,HBase,Hive 多数据源以及数百个其他数据源中的数据。
关键词:Spark;MapReduce;多语言;多数据源
引言
MapReduce会有启动任务时的高开销、对中间数据和计算结果写入磁盘的依赖的严重缺点。这些都使得Hadoop不适合迭代式或低延迟的任务。通过Apache Spark是一个新的分布式计算框架,从设计开始便注重对低延迟任务的优化,并将中间数据和结果保存在内存中,可以为之有效的解决该类问题。RDD是spark平台下的分布式弹性数据集,为处理超大型数据提供便利。RDD:是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上。RDD可以包含 Python、Java、Scala中任意类型的对象,甚至可以包含用户自定义的对象。轻松有效地处理结构化和非结构化的数据,本文主要从RDD角度论述Spark相关应用及原理。
Spark计算过程
弹性分布式数据集,只读分区记录的集合,Spark对所处理数据的基本抽象。Spark中的计算可以简单抽象为对RDD的创建、转换和返回操作结果的过程:
创建
通过加载外部物理存储(如HDFS)中的数据集,或Application中定义的对象集合(如List)来创建。RDD在创建后不可被改变,只可以对其执行下面两种操作。
转换(Transformation)
对已有的RDD中的数据执行计算进行转换,而产生新的RDD,在这个过程中有时会产生中间RDD。Spark对于Transformation采用惰性计算机制,遇到Transformation时并不会立即计算结果,而是要等遇到Action时一起执行。
行动(Action)
对已有的RDD中的数据执行计算产生结果,将结果返回Driver程序或写入到外部物理存储。在Action过程中同样有可能生成中间RDD。
计算方法
Bagel: Pregel on Spark,可以用Spark进行图计算,这是个非常有用的小项目。Bagel自带了一个例子,实现了Google的PageRank算法。
当下Spark已不止步于实时计算,目标直指通用大数据处理平台,而终止Spark,开启SparkSQL或许已经初见端倪。
近几年来,大数据机器学习和数据挖掘的并行化算法研究成为大数据领域一个较为重要的研究热点。早几年国内外研究者和业界比较关注的是在 Hadoop 平台上的并行化算法设计。然而, HadoopMapReduce 平台由于网络和磁盘读写开销大,难以高效地实现需要大量迭代计算的机器学习并行化算法。随着 UC Berkeley AMPLab 推出的新一代大数据平台 Spark 系统的出现和逐步发展成熟,近年来国内外开始关注在 Spark 平台上如何实现各种机器学习和数据挖掘并行化算法设计。为了方便一般应用领域的数据分析人员使用所熟悉的 R 语言在 Spark 平台上完成数据分析,Spark 提供了一个称为 SparkR 的编程接口,使得一般应用领域的数据分析人员可以在 R 语言的环境里方便地使用 Spark 的并行化编程接口和强大计算能力。
Spark编程
Spark通过一个语言集成API暴露RDD,API中每个数据集被表示为一个对象,在这些对象上transformations被使用方法调用。
编程的第一步是通过在稳定存储中的数据调用transformations来定义RDDs(如map和filter)。然后他们可以对这些RDDs调用actions,actions是给应用程序返回值或者把数据导出到存储系统的操作。count、collect、save都属于actions。Spark只有在第一次调用action时才会真正计算RDDs,在此之前进行的transformations都是惰性计算,这样能对transformations进行并行流水线化(pipeline)。
另外,可以调用persist方法表明在以后的操作中他们想用哪个RDDs。Spark默认在内存中持久化RDDs,但是如果没有足够的RAM将会把多余的存入磁盘。用户也可以请求其它的持久化策略,如只在磁盘上存储RDD,或跨集群复制RDD,通过flags进行persist。最后,用户可以在每个RDD上设置持久化优先级去指定哪些内存的数据应该优先被存入磁盘,下面从一个示例说明RDD的使用。
假设有一个web服务出错了,操作员想从保存在HDFS中的TB级的日志中找出原因。通过使用Spark,操作员只需从日志中把刚才那个错误的信息加载到一组节点的RAM,并交互式地查询它们。先写出下面的Scala代码:
lines =spark.textFile("hdfs://...")
errors = lines.filter(_.startWith("ERROR"))
errors.persist()
第一行通过HDFS文件定义了一个RDD(即是文本形式的lines的集合),第二行对lines进行过滤得到一个过滤后的RDD,第三行将errors存入内存以便查询中共享。值得注意的是,在Scala语法中filter的参数是一个闭包。
此时,集群上并没有执行任何工作。但是,用户可以对该RDD执行动作(actions),如统计信息条数:
errors.count()
用户也可以在该RDD上进一步执行transformations,并使用转换后的结果,如下:
//统计errors中涉及MySQL的行数:
errors.filter(_.contains("MySQL")).count()
//以数组的形式返回errors中涉及HDFS的时间字段
//(假设时间是'\t'分隔的number为3的字段)
errors.filter(_.contains("HDFS"))
.map(_split('\t')(3))
.collect()
在errors的第一个action运行后,Spark将在内存中保存errors的分区,极大地加速了后续计算。值得注意的是,最初的RDD(lines)没有被缓存。这很合理,因为错误信息可能只是数据的一小部分(小到足以存入内存)。
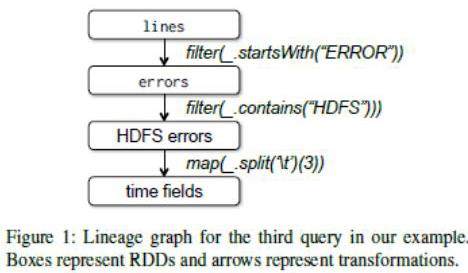
最后,为了说明我们的模型怎样容错,我们在下图中展示了第三次查询中的RDDs的血缘(lineage)图。这次查询,在lines上进行filter得到errors,然后在errors上进一步应用filter和map,之后是collect。Spark调度器将并行流水线化后两个transformations,给拥有errors的分区缓存的节点发送任务集去计算。另外,如果errors的一个分区丢失了,Spark可以仅在lines相应的分区上应用过滤器来重建该分区。
方框代表RDDs,箭头代表transformations
Spark给RDD抽象提供了一个用Scala编写了语言集成API。Scala是在JVM上的静态类型函数式编程语言。我们选择Scala是因为它简洁的组合(便于交互式使用)和效率(由于静态类型)。然而,RDD抽象并不是一定要用函数式语言。
为了使用Spark,开发者写一个驱动程序(driver program)连接wokers集群。driver定义一或多个RDDs,并在RDDs上调用action。在driver上的Spark代码还会追踪这些RDDs的lineage。wokers是长期运行的进行,能在内存中存储RDD分区。
结束语
Spark是一种针对大数据集处理的计算机集群,由Scala语言构建。用户可以通过Python, R, Scala, SQL语言对数据集进行操作。用户提交指令到Spark集群后,Spark分析指令,并构建有向无环图处理方法,接下来通过Cluster Manager和Worker的配合完成并行化的数据处理,最终输出结果,相比于普通的数据库,Spark对于大批量数据和实时数据处理具有明显优势。
参考文献
[1]高建良,盛羽.Spark大数据编程基础:Scala版.长沙:中南大学出版社.2019.03.
[2]刘军, 林文辉, 方澄. Spark大数据处理:原理、算法与实例.清华大学出版社. 2016.
注:部分内容参考Spark官网以及百度文库。

 京公网安备 11011302003690号
京公网安备 11011302003690号


