



- 收藏
- 加入书签

基于LSTM和ARIMA的股票价格预测对比分析
 打开文本图片集
打开文本图片集
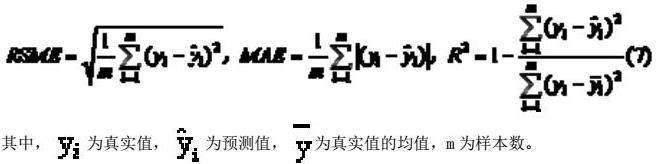
摘要:对证券价格的分析预测一直是学术界和业界探讨的重要课题。本文通过Tushare平台,获取贵州茅台和平安银行股票,2020年9月-2023年9月的数据展开研究。主要采用长短期记忆模型(LSTM)和差分自回归移动平均模型(ARIMA)对股票价格进行预测分析。实证分析中,在三种回归评价指标的评估标准下,得出LSTM的预测效果要优于ARIMA模型。
关键词:长短期记忆模型;差分自回归移动平均模型;回归评价指标;分析预测
Abstract:The analysis and prediction of securities prices has always been an important topic for academic and industry discussions.In this paper,the data of Kweichow Moutai and Ping An Bank stocks from September 2020 to September 2023 are obtained through Tushare platform.We mainly use the Long Short Term Memory Model(LSTM)and the Differential Autoregressive Moving Average Model(ARIMA)to predict and analyze stock prices.In empirical analysis,under the evaluation criteria of three regression evaluation indicators,it was found that the predictive effect of LSTM is better than that of ARIMA model.
Keywords:Long Short Term Memory Model,Differential Autoregressive Moving Average Model,Regression Evaluation Indicators,Analysis and Prediction
1.引言
金融市场实务中对证券价格的变化分析预测有着着举足轻重的作用,如在投资组合管理中,现在比较流行的多因子选股模型中,如何利用因子的历史数据来对股票的价格进行短期和长期的预测都是当下投资人所关心的问题[1]。股票价格数据作为典型的时间序列,很早人们就用传统的计量经济学模型,如ARIMA、GARCH等来对股票进行预测[1]。这些计量经济学模型很好地抓取了股票价格序列的自线性相关性的特征,对股票预测起到了一定的作用。随着计算机技术的迅猛发展,不论是算力还是存储空间都有了极大的提升。无处不在的传感器和网络用户终端,使我们跑步进入大数据时代。层出不穷的机器算法,如支持向量机,决策树,神经网络等,在一维语音,二维图片,三维视频等非结构化数据的处理中展现出了强大的力量,同时对结构化数据的处理也显示出比以往更好的效果[1]。
本文主要采用机器学习LSTM和传统计量经济学模型ARIMA对股票价格进行分析预测。
2.数学模型
LSTM模型是一种循环神经网络的变体。与传统的RNN相比,LSTM模型通过引入了输入门、遗忘门、输出门来控制信息的流动,从而有效地解决了梯度消失和梯度爆炸问题,并能够更好地处理长期依赖关系和记忆信息。在股票价格预测等时间序列数据分析任务中,LSTM模型通过输入当前的收盘价和之前的隐藏状态,利用门控机制生成当前时间步骤的隐藏状态和候选记忆单元,并将隐藏状态作为输出传递给下一个时间步骤,实现了对时间序列数据的预测和分析能力。
接下来介绍计量经济学模型ARIMA。ARIMA模型是一种常用于时间序列预测和分析的统计模型。它通过自回归(AR)模型、差分整合(I)模型和移动平均(MA)模型的组合来描述时间序列数据的特征和趋势。(6)式表示的是ARIMA模型。
其中, 表示时间序列在时刻t的观察值,是一个移动操作符,表示将观察值向后推移一个单位时间,c是常数项,表示服从白噪声误差的随机变量, 是自回归系数,衡量了当前时刻与过去p个时刻的相关性,是移动平均系数,衡量了当前时刻与过去q个误差项的相关性,d是差分阶数,表示对时间序列进行多少次差分运算以达到平稳性。
3.实证分析
3.1样本选取与数据来源
在本文中,我们利用了Tushare平台提供的数据,选取了2020年9月至2023年9月期间贵州茅台和平安银行股票的相关日度数据进行分析研究。数据包括每天的开盘价、最高价、最低价、收盘价和交易量等信息。其中,我们将收盘价作为目标变量,并通过对这些数据的处理和建模,探索了股票价格的变化趋势以及未来走势的预测,为投资决策提供了参考。
3.2数据预处理
为了确保构建的模型具有良好的质量和预测能力,我们对数据进行了仔细的预处理。对于LSTM模型:首先,我们采用了价格数据除以最大值来的归一化处理方法对股票价格数据进行了缩放,将其映射到0-1之间。这样做有助于避免数据范围差异对模型效果的影响,更好地捕捉价格变化的模式和趋势。其次,我们将数据按顺序分成训练集和测试集,前70%的数据用于模型训练,后30%的数据用于模型性能评估。这样可以帮助模型根据历史数据来预测未来的价格走势。最后,我们对训练集和标签进行了序列构建,以适配LSTM模型的输入要求,其中批次大小为1,序列长度为730,特征维度为1。通过这些预处理步骤,我们可以提高模型的准确性和稳定性,更好地实现对股票价格变化的预测。
此外,对于ARIMA模型我们进行如下预处理:首先,确保数据的稳定性。ARIMA模型要求时间序列数据是稳定的,即均值和方差不随时间变化而变化。使用单位根检验来判断数据是否稳定,如果数据不稳定,则需要进行差分处理,使其变得稳定;其次,处理缺失值和异常值:如果数据中存在缺失值,我们删除缺失值。异常值可能会影响模型的准确性,我们使用统计学方法来识别和处理异常值;最后,数据平滑和转化。对于具有较大波动性的时间序列数据,采用移动平均来减小数据的波动,使其更适用于ARIMA模型。如果数据不服从正态分布,可以对数据进行差分转化,以满足ARIMA模型对数据的要求。
3.3评价指标
为了评估LSTM和ARIMA模型对股票价格的预测性能,我们使用以下三种回归评价指标来衡量模型的表现:
方根误差(RMSE):RMSE是目标变量观测值与模型预测值之间差异的平方和的平均值的平方根。它给出了观测值与预测值之间的平均误差大小。RMSE越小,表示模型的拟合效果越好。
平均绝对误差(MAE):MAE是目标变量观测值与模型预测值之间差异的绝对值的平均值。它度量了预测值与真实值之间的平均偏差。MAE越小,表示模型的拟合效果越好。
R-平方(R²):R²是一个统计量,用于衡量预测模型对观测值变异性的解释程度。它表示预测值与目标变量之间的方差占比。R²的取值范围为0到1,越接近1表示模型的拟合效果越好,越接近0表示模型的拟合效果较差。
三种指标计算如公式(7)所示:
其中,为真实值,为预测值,为真实值的均值,m为样本数。
3.4股票价格预测
将本文提出的LSTM模型和ARIMA模型应用于贵州茅台和平安银行的股票价格预测中,每只股票包含730条股价数据。
由表1可知,LSTM模型对于贵州茅台和平安银行数据集所得到的RMSE和MAE均小于其他模型,R²更接近1,说明与其他模型相比,用LSTM模型进行股票价格预测所得的股票价格更接近实际值,预测的效果更好。
图1(a)、(b)和图2(a)、(b)分别展示了LSTM模型和ARIMA模型在贵州茅台和平安银行两只股票上预测730天的结果。从图表可以看出,与ARIMA模型相比,LSTM模型的预测结果更加接近真实的股票价格,误差更小。这表明,在预测这两只股票价格时,LSTM模型具有更好的性能,并且能够提供更准确的预测结果。
4.小结和展望
本文主要采用了LSTM神经网络模型和ARIMA计量经济学模型来对股票价格进行预测。从实证结果可知,LSTM的预测效果要优于ARIMA模型。这也充分说明了ARIMA模型这种只能提取线性性质的模型,用在非线性特征明显的股票价格序列上,效果不如拥有非线性性质提取的循环神经网络。接下去的研究计划,一方面尝试用集成学习的方法进一步提高预测精度,另一方面进行短期和长期不同期限长度的预测精度研究,使我们的研究成果能进一步指导金融实务操作。
参考文献:
[1]王昭栋.多因子选股模型在中国股票市场的实证分析.Diss.山东大学,2014.
[2]RueyS.Tsay.金融时间序列分析.机械工业出版社,2009.
[3]黄晓玮."基于机器学习的上市公司财务预警研究综述."现代商贸工业44.3(2023):2.
项目编号:202210354039 项目名称:深度神经网络在投资组合管理中的应用研究

 京公网安备 11011302003690号
京公网安备 11011302003690号


