



- 收藏
- 加入书签

电子病历结构化多维检索系统的研究与应用
 打开文本图片集
打开文本图片集
摘要:当前医院历史电子病历通常以文本或XML等非结构化文本的形式进行存储,其病历模板建立过程缺乏统一管理,导致格式混乱、难以直接进行结构化检索,不便于进一步分析利用,且容易受到数据类型及硬件性能的限制。研究结合Hadoop及Spark大数据存储与处理技术,在对历史电子病历后结构化处理的基础上,设计并实现一种基于Spark的电子病历多维结构化检索系统,能够很好地满足对海量电子病历数据的检索与分析需求,有效改善传统电子病历非结构化存储难以扩展及检索分析效率低下的问题。
关键词:电子病历;Spark;多维检索
当前,医疗新技术的快速发展,医疗集团、医疗共同体、专科联盟等形式的出现以及医院信息化的不断更新,导致医疗数据出现爆炸性增长;医疗数据类型复杂,结构化数据以及电子病历的自由文本、医学影像数据等大量非结构化数据并存,且实时性、交互性要求较高[1-2];另外,区别于传统大数据特性,临床大数据以患者为中心,通常数据的生命周期比较长,数据的整合性要求较高[3];针对这些临床大数据的特性,传统的以数据仓库模式为主的医疗信息系统的分析处理方式,由于受到硬件性能、成本等限制,无法对大量半结构化或非结构化数据进行处理与分析[4]。此外,对存储能力和计算能力的双向扩展更是极大的挑战。
以电子病历为例,大部分医疗机构在进行电子病历存储时,通常有结构化存储或者结构化+非结构化存储两种形式,第一种全结构化电子病历,数据检索统计分析相对比较方便,但一定程度上能够降低临床医生病历书写的自由度与灵活度,且数据处理或统计分析时,通常直接在数据库中,以联机事务处理的方式进行数据库中表的查询统计,这种方式对决策分析的支持有限,且可能会对日常在线业务造成影响,当面临大规模数据时,由于数据之间的关联性通常比较复杂,对服务器计算性能的要求很高,然而,单靠提高服务器的性能的方式来解决成本过高且难以保证效率;第二种形式结构化+非结构化存储,非结构化文本存储通常以普通文本或XML等形式存储在数据库中,由于XML病历文本的存储形式通常在管理过程中,由于管理不严格可能存在明显弊端,通常XML格式的病历文本模板是由各医院临床科室医生自主建立,医务部门审核后使用。模板涉及元素、节点、控件等多方面要素,因此建立和审核过程中的主观性会导致模板的统一性、完整性和规范性较差。数据使用者将会花费大量时间在处理和筛选环节,阻碍了医疗数据的再利用,且此类形式存储的电子病历难以直接进行结构化检索并且不便于进一步分析使用,且容易受到数据类型及硬件性能的限制。
目前,有一些大型医疗机构通过运用SPSS、SAS等专业统计软件或BI工具来进行数据分析,但专业统计软件通常仅用于有针对性或特定目的的统计分析,侧重于实验和统计学方法运用,其能够处理的数据量小、结构简单,交互性差[5]。此外,BI一般独立于业务数据库,通过建立数据仓库的形式进行分析,对在线日常业务影响较小,但限于数据更新周期,实时性比较差。
综上,基于当前电子病历数据处理及数据检索方式所面临的问题,本文基于Hadoop与Spark技术,在对历史电子病历后结构化处理的基础上,设计并实现一种电子病历多维结构化检索系统,能够很好的满足对海量非结构化电子病历数据的检索与分析需求。
1 电子病历文本结构化处理
1.1 电子病历数据治理
电子病历数据治理的必要性以历史病程文本中查询为例,查询“使用了包含某种成分,可能存在某种副作用的降压药”,即在进行包含分类体系的映射或修饰的查询;“病理类型为集合管癌,病理类型IV期,出现肺部转移,做过肾切除手术”为例,“肺部转移”为非结构化信息,“肾切除手术”为临床事件,即在进行包含非结构化信息以及临床事件的查询时,面临着较大的困难,这都要求在使用历史数据之前,需要进行数据治理。
当前,医疗数据治理在宏观上需要政策的驱动,并且需要进行资源的规划、标准体系的建设以及患者隐私与安全的保护;最后,需要微观上的技术能力,包含组织建设、数据采集存储、处理分析以及应用的建设。数据治理的关键在于数据的标准化、数据的结构化、数据的集成化,另外还要包含对各临床业务系统数据质量的要求与控制。
(1)医疗数据的标准化,通过参考NCCN、临床治疗指南、CTCAE等国内外标准与指南,建设病种标准数据集。
(2)在医疗数据的结构化方面,以非结构化中文文本电子病历数据为基础,对文本中的实体、关系、属性进行标注,并基于自然语言处理技术对电子病历非结构化信息进行提取。
(3)通过可视化、智能化的查询实现对临床数据的集成化,例如针对病理组学诊断的统计分析。
1.2电子病历文本预处理
患者诊疗过程中会产生多个病历文件,病历通常以文本形或XML格式存储在数据库中,此类形式存储的电子病历难以直接检索并且不便于进一步分析使用。此外,XML病历文本的存储形式存在明显弊端,通常XML格式的病历文本模板是由各医院临床科室医生自主建立,医务部门审核后使用。模板涉及元素、节点、控件等多方面要素,因此建立和审核过程中的主观性会导致模板的统一性、完整性和规范性较差。数据使用者将会花费大量时间在处理和筛选环节,阻碍医疗数据的再利用。
1.3 电子病历结构化处理
电子病历结构化则是指将描述型的文本信息按照一定规则进行拆分并以二维的形式存储在关系型数据库中。电子病历结构化从处理方式上可以分为前结构化处理和后结构化处理。前结构化处理需要临床病历系统按照医学语义规则对临床医学文书进行模板化,系统使用者则需要按照规范进行信息录入。后结构化是指利用信息化手段对医生录入的非结构化或半结构化的文本信息进行“理解”和处理,将其转换为结构化的数据。
前结构化对临床系统使用者要求较高即用户需要严格按照模板规范逐一填写所有条目,系统灵活性较弱、用户体验感较差、文书模板定义没有统一的标准和规则,可能存在定义不规范或者完整性缺失的问题,而且当模板内容调整时,级联的修改工作较为繁琐。但前结构化处理方式信息准确性较高,数据库存储的内容直接来源于临床工作者录入的原始信息。
后结构化处理是结合临床工作者标注的实体集,根据定制的规则对文本信息进行数据抽取,然后通过模型批量处理现有的病历资料将其转换为关系型数据。因此信息的准确度会受到处理方法的影响,但是在模型反复训练和学习的基础上准确性会提高,达到可接受的范围,后处理方式也会改善病历系统的用户体验感,同时也非常适合处理现有的大量 XML 格式电子病历文档。
2 系统设计
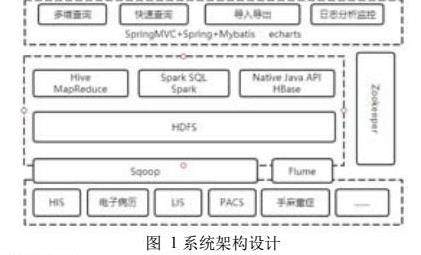
本文基于Spark设计电子病历结构化多维检索系统体系架构,如图1包含对电子病历等原始医疗数据的定时增量抽取、存储、分析计算、应用展示等过程。
2.1 数据ETL及分布式存储
利用Sqoop将医院电子病历业务系统中的原始数据文件进行定时采集,并进行简单清洗后导入HDFS分布式存储,通过利用-check-column-、-incremental及-last-value等参数指定多个需要增量更新的列、增量导入模式及上一次导入中检查列指定字段的最大值。由于Sqoop支持时间戳,可根据时间进行定时增量导入或更新,能够很好的满足电子病历等临床数据的时序性。针对电子病历中的系统日志信息,可以采用Flume自动定时采集各系统日志。
分布式存储的载体主要有分布式文件系统HDFS及HBase分布式数据库,数据经过ETL被转换到HDFS中,经过切割分块之后,存储在各个数据节点,以实现分片管理及负载均衡,保证数据的高容错、高可用性。
2.2 分布式计算框架
利用Spark Core、Spark QL以及 Hive on Spark等组件,实现电子病历检索的各种复杂业务逻辑。数据处理的计算任务提交至Spark计算框架后,将不同来源、不同类型的数据进行统一转换为弹性分布式数据集RDD,并构建RDD之间的依赖关系,将RDD转换为分阶段的有向无环图。根据空闲计算资源情况进行任务提交,并对任务的运行状态进行监测和处理。通过搭建的任务运行环境来执行任务并返回任务计算之后的结果。依据依赖关系的情况,判断是否需要进行Shuffle操作。从每个任务收集并汇总结果,计算的结果根据不同的主题,加入时间戳后存储在HBase数据库中,大部分统计分析的需求都是可以根据临床科研指标体系进行预定义的,同时也可以支持实时的交互式自定义指标的查询分析。
由于电子病历等医疗数据处理的特殊性,通常需要满足不同类别、不同用途的分析功能,因此需要为不同的分析功能都开发一个Spark作业并运行在Yarn集群上,针对Hive中的海量电子病历非结构化数据进行计算,最终将携带时间戳的计算结果写入数据库中。
2.3 数据展示
电子病历结构化多维检索与分析系统能够为数据使用者提供定制的检索功能,数据使用者可以方便快捷地进行病历筛选。用户在系统界面中选择某个功能对应的菜单,并进入对应的任务创建界面,然后选择筛选条件和任务参数,并提交任务,根据用户提交的任务类型选择其对应的 Spark作业,启动一个子线程来执行 Spark-submit-命令以提交 Spark作业。
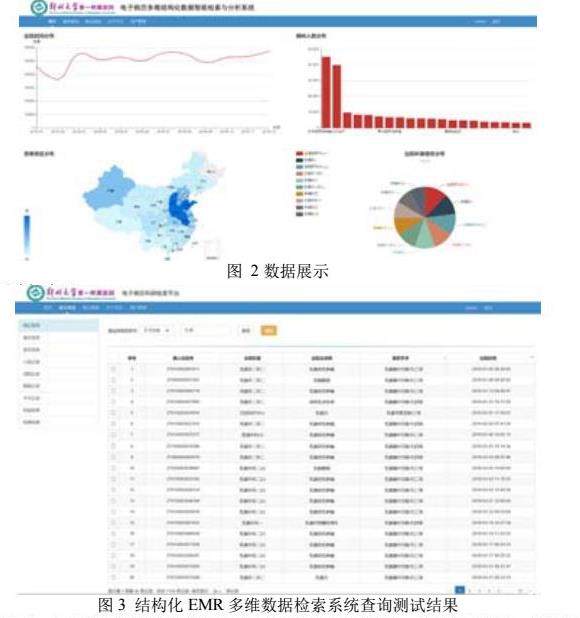
采用基于JavaWeb开发实现电子病历结构化多维检索与分析系统,用户通过系统界面查看分析结果,并将数据库中的计算结果返回给前端,利用开源可视化库Echarts插件对数据结果进行图形化展现。图2展示对现有病历资料从病种人数、患者出院科室、患者来源地区等几个方面进行分析并形成图表,方便用户对数据有一个更直观、全面地掌握。
3 系统测试与应用
基于OLAP的检索分析方式通常采用固定报表、计算、以及临时数据提取等方式来实现数据分析,目前,许多OLAP工具并不能很好的支持从HDFS上直接获取数据,而需要将数据转换到关系型数据库中OLAP,随着医疗大数据的形成,这种方式存在着很多的问题。
采用基于Spark的电子病历结构化多维检索与分析模型,根据在后期选择的维度和指标,通过接口开发从HBase中获取数据来展示。此外,可以利用 Kylin作为OLAP引擎,在 Kylin中设计好Cube,通过 Kylin来完成数据分析需求。
如图3所示,电子病历的结构化多维检索与分析包含快速检索、多维符合检索、统计分析等多方面,并能够实现相似度联结,相似度联接是通过提取多个特征,形成特征矩阵,计算相似度的形式实现,可以应用于寻找相似的病例与诊断等多个地方。
4 结语
基于Spark的医疗大数据处理模型通过利用 Hadoop及 Spark大数据存储与处理技术,能够满足海量医疗数据下细粒度的统计与计算模式,并在存储或处理的数据量激增时,通过增加节点的方式提升分析处理和存储的能力,具有良好的扩展性。此外,基于 Spark的医疗大数据处理模型同时也能满足以迭代计算为代表的OLAP、即时查询、数据挖掘、图形分析等数据处理需求,将在医疗服务大数据处理中得到更广泛和深入的应用。
参考文献:
[1] 毛戈,李晶,姚弘毅. 基于智慧医院的电子病历应用和设计[J]. 湖北大学学报(自然科学版),2021,43(6):706-712.
[2] 唐斌,姚陆晨,姜胜耀. 医院科研大数据平台的应用实践探索[J]. 中国数字医学,2021,16(11):104-108.
[3] 吴宗友,白昆龙,杨林蕊,等. 电子病历文本挖掘研究综述[J]. 计算机研究与发展,2021,58(3):513-527.
[4] 陈洞天,汪火明. 半结构化电子病历数据的质控系统构建[J]. 中华医学图书情报杂志,2021,30(10):66-73.
[5]吴骋,王志勇,徐蕾,等. 基于人工智能的电子病历数据质量控制[J]. 解放军医院管理杂志,2021,28(2):134-135,168.
作者简介:王伶俐,出生年月:1991年3月,性别:女,民族:汉族,籍贯:河南固始
学历:硕士研究生,职称:助理工程师,研究方向:设备质量控制
河南省医学科技攻关计划软科学重点项目(NO.RKX202201007)

 京公网安备 11011302003690号
京公网安备 11011302003690号


