



- 收藏
- 加入书签

基于人工智能的药学领域论文实体识别:性能与可用性研究
 打开文本图片集
打开文本图片集

摘要:【目的】本研究旨在探讨ChatGPT和文心一言在药学领域论文实体识别方面的可用性。【方法】通过标注论文的不同内容,我们利用ChatGPT和文心一言对标注内容进行识别,并通过计算返回的正确率来评估两者的可用性。【结果】实验结果显示,ChatGPT在论文实体识别上的F1值平均为47.86%,而文心一言的F1值平均为84.21%。这表明,在中文药学论文实体识别方面,文心一言表现出更高的稳定性和准确性。【局限】本研究仅在中文文献中展开了实验,ChatGPT的训练数据以英文为主,而文心一言则以中文为主。因此,我们认为ChatGPT在中文药学领域实体识别的能力可能受到限制。【结论】虽然ChatGPT和文心一言均能够从学术论文中识别出实体信息,但识别结果仍需进一步处理和分析,以提高其在药学领域实体识别中的准确性和实用性。未来研究可以拓展到其他语言领域的实体识别,以及优化模型的训练数据和算法,以提升实体识别的性能和稳定性。
关键词:人工智能;ChatGPT;文心一言;学术论文实体识别;药学
中图分类号:R911 文献标识码:A
1引言
2022年11月OpenAI基于GPT-3推出一款新的聊天程序ChatGPT[1](全名:Chat Generative Pre-trained Transformer),上线仅两个月时,活跃用户突破已超过一亿。2023年2月OpenAI推出基于GPT-4升级后的ChatGPT Plus,几周后微软宣布将GPT-4整合在全球第二大搜索引擎必应中,这款新的聊天程序不仅在用户数量上取得了巨大的成功,也在全球范围内引发了广泛的关注和讨论。作为一款强大的人工智能工具,ChatGPT能够以自然的方式与人类进行交互,并能够生成高质量的文本内容。这使得它在各个领域都有着广泛的应用前景,如教育、机器翻译、信息抽取等。
随着ChatGPT的发布,国内也涌现出一批中文大语言模型,其中具有代表性的有百度推出的文心一言[2]和科大讯飞推出的讯飞星火[3]。这些大语言模型的推出,标志着中国在人工智能领域的发展已经进入了一个新的阶段,中文大语言模型平台的出现不仅提高了人工智能技术在中文语言处理方面的水平,也为各个行业提供了更加智能化、高效化的解决方案。
2. 现有的药学领域实体识别方法
2.1 规则基础的方法
早期的药学领域实体识别方法主要基于规则,使用手工定义的规则和模板来匹配文本中的药物名、化合物名等实体。基于规则的方法在处理医疗文本时,确实是一个重要的工具。这种方法的核心思想是根据预定义的规则来分析和处理文本数据。例如:Alex等人[4]使用由专家从标记化和POS标记的医学文本为NER编写手工规则和词典,构建了一种基于文本挖掘技术的系统,对CT和MRI脑部扫描的放射学报告进行分类和标注。
2.2 机器学习方法
基于规则的方法在命名实体识别中要求人工精心制定复杂的规则集,这不仅耗时耗力,还可能因为规则的局限性而无法覆盖所有情况。相比之下,基于机器学习的方法则无需如此繁琐,它仅需利用标注好的数据集进行训练,便能让模型自动学习实体识别的模式,从而实现高效且准确的实体识别。这种方法不仅减轻了人工负担,还因其自适应性强的特点,更适用于处理大规模和多样化的文本数据[5]。随着机器学习技术的发展,药学领域实体识别逐渐转向基于统计学和机器学习的方法。传统的特征工程结合支持向量机(SVM)、隐马尔可夫模型(HMM)等算法被广泛应用。这些方法通过学习文本中实体的上下文信息和模式,提高了实体识别的准确性和泛化性。
3.测评任务和数据集
本研究选择了包含药学领域文献的公开数据集,以确保实验的可重复性和代表性。常见的数据源包括知网、维普中文等数据库以及药学领域相关的中文学术出版社。为了确保模型能够应对药学领域的多样性,我们包含了来自不同子领域的文献,包括药物化学、药理学、药物制剂等领域的内容。
3.1数据集的建立
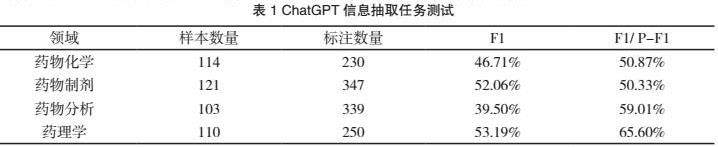
由于ChatGPT仍具有不确定性,有研究表明ChatGPT提供的信息有一定错误的几率[8],为了避免被误导我们采用人工标注的方式对ChatGPT的信息抽取能力进行验证。数据集主要包括以下两大数据集。人工标注数据集(Human-Annotated Data Set): 从论文关键信息中进行的人工标注数据,用于构建对比基准。ChatGPT 验证集(ChatGPT Validation Set): 在人工标注关键信息后进行模糊或准确提问, 用于最终评估 ChatGPT 在文献抽取任务上的性能。
3.2评价指标
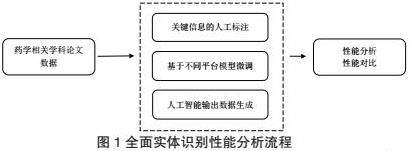
为了深入评估 ChatGPT 在实体识别任务中的表现,我们引入了一个创新的评估框架——全面实体识别性能分析(Comprehensive Entity Recognition Performance Analysis,简称CERPA)。通过模拟各种异常输入和情境,我们能够检测模型是否能够正确处理异常情况,并了解模型在异常情况下的行为模式,为模型的进一步优化提供指导。
图1全面实体识别性能分析流程
通过精确边界匹配和宽松边界匹配[6]两种方式比较ChatGPT在论文信息提取方面的性能,精确边界匹配是指无论实体边界如何,预测的实体边界都是正确的,宽松边界匹配是指实体边界重叠,与实体边界无关。在实体识别性能分析中,选择准确率P为正确识别实体数与总选择数之比,TP为成功识别事件数,FP为误识别实体数,FN为未识别真实实体数。
3.3关系抽取任务测评
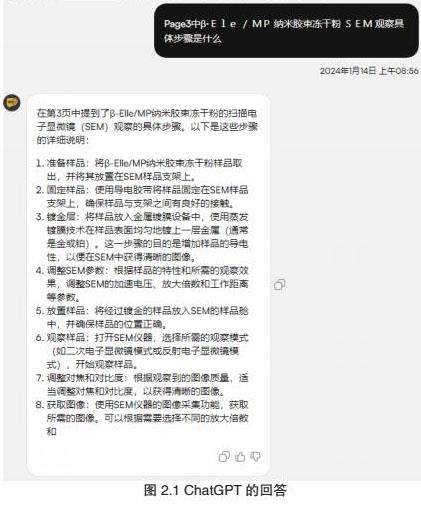
本文将基于gpt-3.5-turbo的API[7]对人工标注的关键信息与人工智能的回答进行对比,我们首先将论文以PDF格式提供给ChatGPT进行解析,然后设计了一系列问题,涵盖了摘要的主旨、实验材料的详细信息、实验步骤的操作流程、实验结果的定量数据以及讨论中的核心观点。
通过多轮测试,我们收集了ChatGPT与文心一言在相同问题下不同药学领域相关论文的回答,并将其与原文进行对比。评估的指标包括回答的准确性、关系抽取的精确度以及对于模糊语义的理解能力。我们重点关注模型在摘要、实验结果等关键部分的表现,以确保其对于文献中重要信息的抽取准确度。
4.ChatGPT与文心一言在药学信息提取任务中的对比研究
4.1 ChatGPT的性能分析
经过对ChatGPT的数据进行深入分析,我们可以观察到该模型在论文信息提取方面展现出了较高的准确性。在多数场景下,ChatGPT能够准确地回应我们提出的问题,有效地提供了相关的信息和解答。
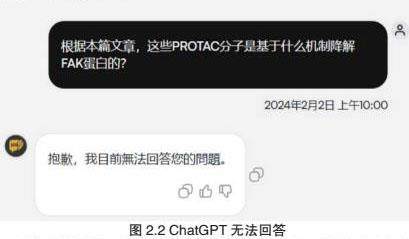
然而,在精准提问的过程中,我们也发现了一些不足之处。特别是在某些情况下,ChatGPT的回答并不全面,甚至存在错误的情况,但是大多数情况ChatGPT依然能够很好的回答我们的问题。
为了对ChatGPT的数据进行系统性分析时,我们进一步探讨了其在不同提问模式下的表现。特别是在宽松匹配提问的环境中,我们发现ChatGPT的回答往往缺乏明确的焦点,容易偏离问题的核心。这不仅使得回答的有效性降低,还可能误导提问者对其真实意图的理解。
这种局限性可能源于模型的训练数据、算法设计或其他技术因素。为了更深入地理解这些原因,未来的研究可以进一步探讨ChatGPT的工作原理及其在不同情境下的性能表现。
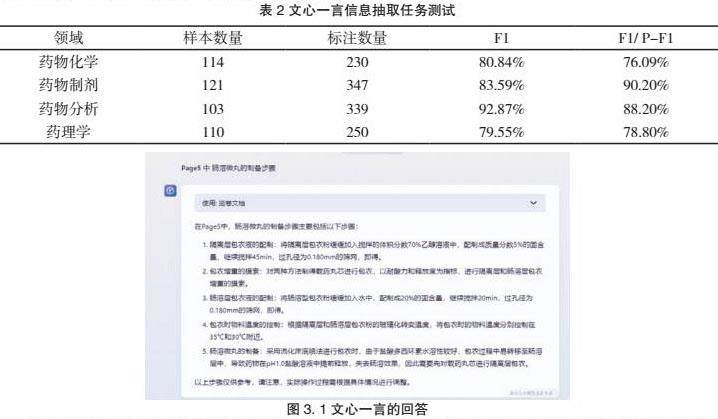
4.2文心一言的性能分析
同时通过对比文心一言也在自然语言处理领域展现出了卓越的问题处理能力。不论是在精确匹配还是宽松匹配的场景下,它都能够达到较高的准确率。在处理问题时,文心一言不仅能够提供全面而详尽的答案,而且其回答的内容通常更贴近原文,为用户提供了更加准确、有价值的信息。
文心一言对原文的深入理解和精准把握是其回答贴近原文的关键。它不仅仅停留在对问题的表面理解上,而是深入挖掘问题背后的含义和意图,从而给出更加精准的回答。这种深入的理解使得文心一言能够捕捉到原文中的关键信息,避免了信息的遗漏和误解。
然而,尽管文心一言在大多数情况下表现出色,但我们也注意到,有时其回答会引用如百度百科等外部知识库中的专业信息,而这些信息与文章的实际内容可能并不相关。这种情况可能是由于模型在整合外部知识时,未能准确判断信息的适用性和相关性。尽管如此,通过适当调整或重新表述问题,用户仍然可以引导文心一言给出准确的回答。
5.总结与展望
一、文心一言与ChatGPT在中文药学领域文献阅读的满足度
本研究表明,文心一言和ChatGPT在中文药学领域的文献阅读方面均表现出较强的辅助能力,基本可以满足科研人员在阅读论文时的需求。文心一言以其深入的理解能力和全面的信息提取能力,展现出在药学领域文献阅读中的优越性。ChatGPT虽然在某些方面稍逊一筹,但其准确率也稳定在50%以上,显示出其在这一领域的潜在价值。
二、ChatGPT与文心一言在阅读能力上的差异
通过对比分析,我们发现ChatGPT在中文药学相关文献的阅读能力上相较于文心一言稍显不足。文心一言能够回答正确绝大部分问题,显示出其强大的问题处理能力。而ChatGPT虽然也能提供一定的帮助,但其回答准确率相较于文心一言有所降低,这可能与其模型训练和数据集的选择有关。
三、ChatGPT的局限性及未来展望
本研究还发现,ChatGPT在特定领域的知识储备和推理能力上存在一定局限性。在实际测试中,有时会输出看似相关但实际上完全错误的内容。这可能与其缺乏中文特定领域的训练语料有关。因此,未来的研究可以考虑为ChatGPT增加更多的中文药学领域训练语料,以提高其在该领域的回答准确率。同时,我们也期待未来能出现更加智能、高效的辅助阅读工具,为科研人员提供更加全面、准确的信息支持。
参考文献:
[1]郭全中,张金熠.ChatGPT的技术特征与应用前景[J].中国传媒科技,2023,(01):159-160.
[2]倪浩,沈维多. 对标ChatGPT,百度将上线“文心一言”[N]. 环球时报,2023-02-08(011).DOI:10.28378/n.cnki.nhqsb.2023.000928.
[3]魏蔚. 科大讯飞大模型姗姗来迟[N]. 北京商报,2023-05-08(004).DOI:10.28036/n.cnki.nbjxd.2023.001248.
[4]2019, 10: 1-11.[18]Alex B, Grover C, Tobin R, et al. Text mining brain imaging reports[J]. Journal of biomedical semantics,
[5]成璐.面向不良反应的药品本体构建与应用研究[D].南京邮电大学,2023.DOI:10.27251/d.cnki.gnjdc.2023.001151.
[6]Grishman R, Sundheim B M. Message understanding conference-6: A brief history[C]//Proceedings of the 16th Conference on Computational Linguistics.1996: 466-471.
[7]OpenAIAPI.[2023-04-24].https://platform.openai.com/docs/api-reference.
[8]方师师,唐巧盈.聪明反被聪明误:ChatGPT错误内容生成的类型学分析[J].新闻与写作,2023(04):31-42.
资金资助:本文系2023年度辽宁省教育厅大创项目《探究Chatgpt在药学相关领域中的应用》(L20BZZ003)阶段性成果。

 京公网安备 11011302003690号
京公网安备 11011302003690号


