



- 收藏
- 加入书签

基于LLM的12385残疾人服务智能问答方法研究与应用
 打开文本图片集
打开文本图片集
摘要: 智能问答系统以其高效解决问题、广泛适用性、个性化定制和持续学习优化等优点,受到客户服务行业的青睐,为提高12385残疾人智能问答服务的建设提供了全新的解决方案。大语言模型(LLM,Large Language Model)在理解和响应人类指令方面的突出表现,推动了智能问答任务在自然语言处理中的创新进展,但是LLM无意义或一些完全虚构的内容,引发了人们对LLM在实践场景中可靠性的担忧,幻觉问题仍是制约LLM在垂直领域应用的关键因素,这种现象对其实际部署提出了巨大挑战。因此,为了提高LLM在残疾人服务领域智能问答系统的准确率,本文提出了一种数据增强的方法改进和提升问答效果,并应用于实践。
关键词: 大语言模型;数据增强;残疾人服务;智能问答
1问题的提出
信息技术的快速发展促进了第四范式下大数据时代的到来,面对大量的知识信息,如何更准确、快速地获取到所需内容却成为了愈发严峻的挑战[1]。智能问答系统[2]的发展为信息检索带来了新的可能性。系统允许用户以人类语言进行方便快捷的交互,结合相关自然语言处理技术[3]通过对问题进行分析理解,并根据模型“记忆知识”和在知识库中检索返回最佳答案。
大语言模型(Large Language Model,LLM) [4]在纷繁复杂、类型多样的数据上训练得到,天然适应于各类自然语言处理任务。同时,由于原始训练出来的大语言模型在微调阶段引入了大量的人工注释样本,生成的语言更符合人类的表达习惯。因此LLM可以更高效、准确地理解人类提出的复杂语义问题,为用户进行智能问答、文本生成提供技术支撑。
12385残疾人服务热线作为连接残疾人士与社会服务的重要桥梁,在长期运营过程中积累了丰富的问答知识库。这一知识宝库不仅涵盖了各类残疾人士可能遇到的疑问和难题,还凝聚了众多服务人员的智慧和经验。为了进一步提升服务效率和质量,基于大语言模型技术,可以开发这个垂直领域的智能问答系统。该系统能够深度学习和理解这些知识内容,模拟人类专家的思考方式,为残疾人士提供更为准确、及时的回答。这类创新应用,不仅能够缓解12385人工服务热线的压力,还能够让残疾人士在寻求帮助时感受到更加便捷和个性化的服务体验。
尽管基于LLM大语言模型的智能问答系统在理论上具有巨大的潜力,但在实际应用中,我们不得不面对一个严峻的挑战——模型幻觉问题[5]。这一问题表现为模型在生成回答时,有时会产生与事实不符、逻辑错误或完全虚构的信息。这种现象不仅损害了回答的准确性,还可能对依赖这些信息的残疾人士造成误导,甚至带来严重后果。
因此,在推进智能问答系统开发的同时,我们必须高度重视并解决模型幻觉问题。这需要我们深入研究LLM模型的内在机制,识别导致幻觉产生的关键因素,并采取相应的技术手段进行干预和优化。只有通过持续改进和完善,确保模型生成的回答始终基于真实、可靠的知识库,我们才能实现智能问答系统的真正落地应用,为残疾人士提供更加高效、精准的服务。
2基于知识增强的解决方案
基于LLM研发实现在12385热线服务领域智能问答系统产生幻觉问题的主要原因有:
1)缺乏高质量12385问答数据集。高质量的数据集获取困难包括两个方面:①用户查询问题“五花八门”,残疾人服务涉及政策多、办事事项多,办事种类也很繁杂,事项需要跨越多个部门,难以形成标准的问答集。②数据格式和标准,不同的部门采用不同的数据格式和标准,数据整合和利用变得困难。③部分知识通过调用搜索引擎在互联网中检索得到,无意义甚至虚假信息较多,知识库质量较低。
2)检索增强生成问题。生成式语言模型通常依赖大量的参数来存储知识,面对没有训练学习过的问题时,原有研究主要通过在模型外部引入知识库的方式进行补充模型记忆参数知识,检索是集中在判断检索到的段落知识与问题的相关性程度上,没有从问题语义出发考虑对检索结果的影响。
为解决基于LLM大语言模型的智能问答系统中的模型幻觉问题,可以通过优化数据质量、改进模型架构、引入外部知识库、建立不确定性建模、实施持续学习与用户反馈机制、加强人工审核以及提高模型解释性和透明度等技术措施来综合应对。本文提出一种基于检索增强生成(Retrieval Augmented Generation,RAG)[6]、引入外部知识库的解决方案。主要方法如下:
1)通过结合大语言模型和提示学习(Prompt Learning)[7]的数据增强(Data Augmentation,DA)[8]方法构建高质量12385智能服务数据集。利用LLM的语义理解、文本生成能力,结合提示学习(Prompt Learning)构造提示模板,对已有的问答数据进行处理,将数据转换为更多的可利用样本,从而扩展原有智能问题训练数据集。
2)优化检索增强生成技术,在接受用户输入并进行知识库检索之前,引入LLM进行语义分析,并生成三个与问题相关的查询问题,使得检索过程更加精准地匹配用户需求,排除相关但不符合用户意图的内容,从而提高检索结果的准确性。
3)引入向量数据库[9],将12385智能服务数据向量化后存储在向量数据库中,并构建相应的索引结构提高查询效率。同时,向量数据库可以快速的支持内容的增加和删除,便于服务数据快速查询,确保模型检索到的外部数据来源可靠。
3模型构建
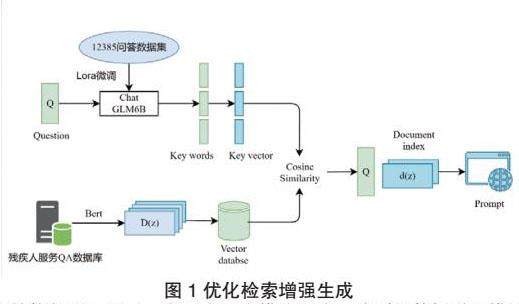
本模型结构如图1所示,主要由三个模块组成,分别是数据增强模块、优化检索增强模块和构建向量数据库模块。首先,在数据增强模块对少量12385问答数据扩充,构建高质量12385问答数据集,微调基础通用LLM得到残疾人服务垂直领域LLM;然后,将用户问题输入该LLM分解得到三个子问题,由此用户问题语义信息得到进一步的丰富;最后,将12385知识文本切分后向量化,再存入向量数据库并接入微调后的LLM中,为系统输出回答提供新的知识内容。
3.1 数据增强模块
足量的12385服务数据是实现智能问答系统的基础,其优劣对于智能何答系统的适用性以及可靠性起着至关重要的作用。12385服务QA数据集中的问题要能够基本覆盖残疾人朋友会遇到的常见问题,答案需要根据当地政府和残联的实际情况和问题进行有针对性地解答。常用的积累QA问题数据的方法,一种是利用爬虫技术爬取相关网站和社交网站中的问题数据[10],另外一种是通过问卷调查的方式,收集残疾人在保障政策、康复就业、教育文化、维权保障中容易碰到的问题。这两种方式收集到的常见问题种类和数量一般较少、质量较低。
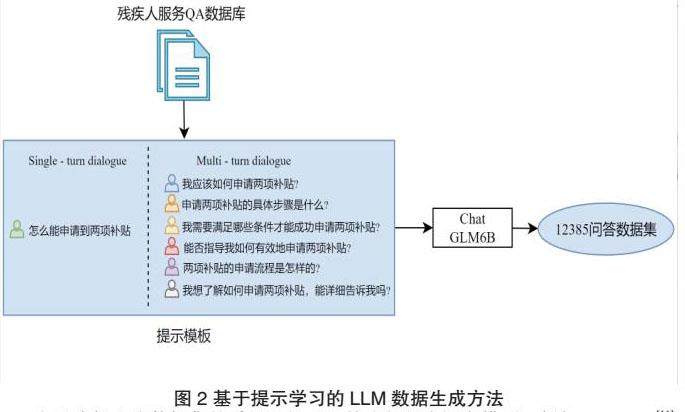
数据增强模块在少量的但高质量的12385数据集基础上,利用大语言模型和提示学习扩充数据集。LLM通过学习已有的文本数据,理解和捕捉语言的规律和模式,给定一些输入提示,这些输入提示可以是关于残疾人参与社会生活中的某个特定方面的问题或者是与残疾人相关的关键词或短语,模型可以根据这些提示生成与输入相关的回答或信息,从而能够预测和生成自然流畅的符合实际情况的新数据文本。
如图2所示,输入一个长度为n的12385服务QA数据文档S,先利用分词算法,将整篇文档分割成若干个token,例如关于两项补贴的一份数据,原始文档为“问题一:什么是两项补贴政策?答案: 两项补贴政策是指困难残疾人生活补贴和重度残疾人护理补贴。困难残疾人生活补贴主要补助残疾人因残疾产生的额外生活支出,对象为低保家庭中的残疾人,有条件的地方可逐步扩大到低收入残疾人及其他困难残疾人。重度残疾人护理补贴主要补助残疾人因残疾产生的额外长期照护支出,对象为残疾等级被评定为一级、二级且需要长期照护的重度残疾人,有条件的地方可扩大到非重度智力、精神残疾人或其他残疾人,逐步推动形成面向所有需要长期照护残疾人的护理补贴制度。问题二:如何申请两项补贴?答案: 残疾人两项补贴由本人或其法定监护人向户籍所在地的乡(镇)政府或街道办事处提出申请。填写《困难残疾人生活补贴审核表》、《重度残疾人护理补贴审核表》(一式三份,以下简称《审核表》),同时提供居民身份证或户口本、残疾人证及复印件,贫困残疾人同时提供困难证明及复印件,个人申请确有困难的,可委托他人或由所在的村(居)民委员会代为申请。”
可以分割为“问题一:什么是两项补贴政策?答案: 两项补贴政策是指困难残疾人生活补贴和重度残疾人护理补贴。困难残疾人生活补贴主要补助残疾人因残疾产生的额外生活支出,对象为低保家庭中的残疾人,有条件的地方可逐步扩大到低收入残疾人及其他困难残疾人。重度残疾人护理补贴主要补助残疾人因残疾产生的额外长期照护支出,对象为残疾等级被评定为一级、二级且需要长期照护的重度残疾人,有条件的地方可扩大到非重度智力、精神残疾人或其他残疾人,逐步推动形成面向所有需要长期照护残疾人的护理补贴制度。”和“问题二:如何申请两项补贴?答案: 残疾人两项补贴由本人或其法定监护人向户籍所在地的乡(镇)政府或街道办事处提出申请。填写《困难残疾人生活补贴审核表》、《重度残疾人护理补贴审核表》(一式三份,以下简称《审核表》),同时提供居民身份证或户口本、残疾人证及复印件,贫困残疾人同时提供困难证明及复印件,个人申请确有困难的,可委托他人或由所在的村(居)民委员会代为申请。”两个token。因此,分词后的文本St,首先从St中选择一条数据用来生成提示,将提示输入大模型生成 N 条数据进行汇总,重复以上述步骤,直到St被选完得到新的12385服务QA知识数据集Hn。
为了确保生成数据集的质量,针对目前流行的大语言模型,例如Chat GPT[11]、文心一言[12]、智谱清言[13]等,进行对比实验,最终选取生成质量最高的一组作为微调通用大语言模型的新数据集。
3.2 优化检索增强生成模块
问题理解作为问答系统的首要环节,其结果为后续的信息检索和答案抽取两个环节提供了指导信息,在12385热线服务场景中,残疾人朋友常常因无法准确描述需要查询的信息,导致问答效率较低。已有检索增强生成技术没有考虑复杂语义下的检索质量,因此本模块首先微调基线轻量级大语言模型ChatGLM2-6B[14],再引入问题分解的思想,通过对复杂问题进行分解,达到理解问题的目的,最终提高系统模型回答的准确率。
3.2.1 微调
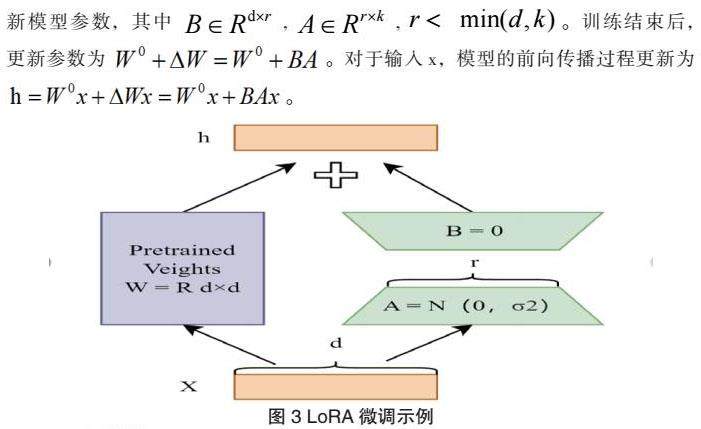
目前开源的大语言模型没有针对12385热线服务领域专门训练,在回答残疾人朋友问题时,会出现答案偏向准确但是无意义情形。本框架引入LoRA微调的思想[15],通过优化适应期间密集层变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预训练权重冻结,增加旁路矩阵来模拟全参数微调,将3.1节中的12385知识储存到基线模型中。如图3所示,在基线大语言模型ChatGLM2-6B旁边增加一个旁路,通过先做降维再升维的改变来更新内在秩;用随机高斯分布初始化A,用零矩阵初始化B,训练时冻结原预训练模型的参数,只训练旁路中的矩阵A与矩阵B;训练完成后,将B矩阵与A矩阵相乘后合并预训练模型参数作为微调后的模型参数。在微调过程中假设权重的更新也具有较低的“本征维度”,对于预训练模型的权重矩阵 ,通过低秩分解(Low-Rank Decomposition)来表示约束其更新。训练过程中 被固定不再进行梯度更新,通过训练A和B更新模型参数,其中 ,,。训练结束后,更新参数为 。对于输入x,模型的前向传播过程更新为。
3.2.2 问题分解
问答系统中的复杂问题分解技术[16]是指将一个复杂问题分解为若干简单问题,将这些简单问题与其答案作为原始复杂问题的上下文提供给模型,从而降低直接 回答复杂问题的难度。简单问题在句型上主要是简单句,而且需要的线索往往是单个句子,可以直接在文件材料中获得答案,而不需要经过推理。复杂问题可以看作是由多个简单问题经过融合而成的,而且其中的简单问题往往是描述同一实体的不同方面。因此本框架使用微调后的ChatGLM2-6B模型将师生问题分解成简单问题,提高检索效率。
如图所示,对于问题文本Q,将其输入微调后的ChatGLM2-6B模型得到一个问题文本序列Q={q1,q2,q3},提取师生复杂问题的深层语义信息。首先利用微调后的ChatGLM2-6B模型的理解能力总结出3个关键词key words,然后根据关键词生成3个简单问题{q1,q2,q3},最后利用生成的简单问题检索数据库中的信息,为系统模型回答提供知识源。
假设问题答案出现在语料库中的一个或多个段落跨度内。D集合为校园知识数据库,将每个D拆分为长度相同文本段落作为基本的检索单元,总共获得了M个段落。当给定一个Question (Q) ,使用BERT对分解得到的{q1,q2,q3}进行编码,得到简单问题向量表示q(i),再使用相似度计算简单问题向量表示q(i)和文本段落向量表示D(z)得到K个和用户问题最相关的文本段落向量d(z),最后存入模板中当作上下文信息输入系统模型。那么我们就可以得到retriever映射 R:(q,d),即输入问题Question (Q)和 一个语料库D ,返回K个最匹配文本,其中d=K<<D 。对于给定的K,可以使用 top-k retrieval accuracy来进行修改。
3.3向量数据库构建
传统的数据库查询通常可以归结为点查和范围查,而无论是点查和范围查都是一种关键词查找,即查询得到的结果要么符合条件要么不符合条件。实际应用中大都是模糊查找,无法给予精确的问题,查找准确率不高。
本框架采用FAISS向量数据库构建方法。校园文本数据中有一些行中的文本数据格外长,是由好多个句子组成的,对向量特征计算、以及精准定位检索结果造成影响。需要将多个长句拆成每行一个的短句子,为了提高长句拆分成短句的质量,FAISS使用Node.js脚本来处理数据,然后使用Zhao Z文章[17]中的预训练模型将对载入内存的文本进行向量计算,对每一行数据进行特征向量抽取,最终所有校园文本向量化为了768 维的向量数据。与传统数据库相比,向量数据库的向量查询通常是近似查找,即查找与查询条件相近的结果,即查询得到的结果是与输入条件最相似的,可以得到更为精确和准确的搜索结果。
4实验
本章为系统的效果提供了实验证据,包括数据增强实验和问题分解实验。
4.1实验设置
本文实验采用的硬件配置为GPU:16G RTXA4000,CPU:32G 12-core Intel(R) Xeon(R) Gold 5320 CPU @ 2.20GHz。实验工具及软件环境为python-3.8,pytorch-1.10.0,Cuda-11.3。
4.2实验结果
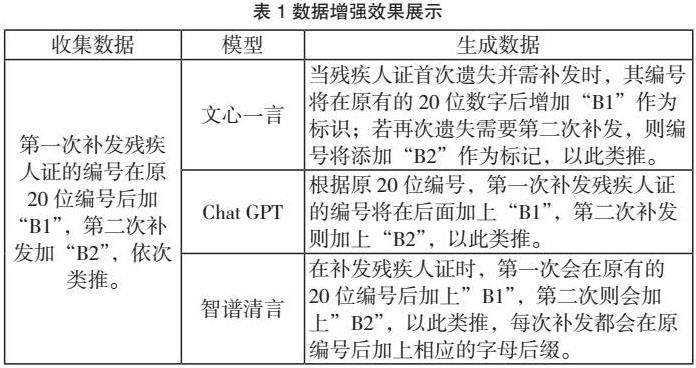
表1展示了不同模型下数据增强后的数据质量展示,根据生成数据显示,利用大语言模型和提示学习的方法进行数据增强是有效的。
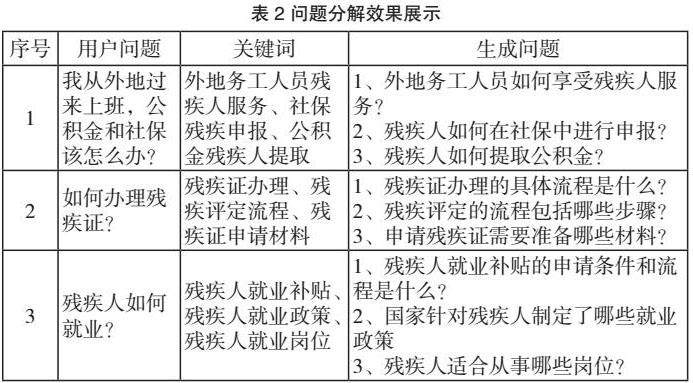
表2展示了问题分解的性能,通过实验证明,本模块可以根据用户问题分析用户意图,生成更详细的查询问题,验证了方法的有效性。
5总结与展望
为了提高大语言模型在残疾人服务领域智能问答的效率,解决该领域缺乏高质量数据集问题、回答准确率低问题、数据库质量差的问题,本文提出了一种数据增强的方法改进和提升问答效果,并通过实验验证了方法的有效性。在未来的工作中,我们将进一步研究大语言模型在残疾人服务领域智能问答面临的问题,提高智能问答系统回答质量,构建多模态的问答系统,根据用户的个性化需求和反馈来定制智能问答系统的功能。例如,结合用户的历史查询记录和行为模式,系统可以学习用户的偏好并提供更加符合其需求的回答,使智能问答系统在残疾人服务领域的实用性和适应性有进一步提升。
参考文献:
[1]潘教峰, 张晓林. 第四范式: 数据密集型科学发现[M . 科学出版社, 2012.
[2]邱楠,王昊奋,邵浩.从聊天机器人到虚拟生命-人工智能技术的新机遇[J].中国人工智能学会通讯,2017,11(7):32-40. QIU N,WANG H F,SHAO H.From chatbots to virtual life-new opportunities for artificial intelligence technology[J].Communications of the CAAI,2017,11(7):32-40.
[3]Collobert R, Weston J. A unified architecture for natural language processing: Deep neural networks with multitask learning[C]//Proceedings of the 25th international conference on Machine learning. 2008: 160-167.
[4]Wei J, Tay Y, Bommasani R, et al. Emergent abilities of large language models[J]. arxiv preprint arxiv:2206.07682, 2022.
[5]Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu,Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. 2023a. Survey of hallucination in natural language generation. ACM Comput.Surv., 55(12):248:1–248:38.
[6]Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.
[7]鲍琛龙,吕明阳,唐晋韬等.与知识相结合的提示学习研究综述[J].中文信息学报,2023,37(07):1-12.
[8]Steven Y. Feng, Aaron W. Li, and Jesse Hoey. 2019.Keep calm and switch on! Preserving sentiment and fluency in semantic text exchange. In Proceeding of the 2019 Conference on Empirical Methods inNatural Language Processing and the 9th Interna-tional Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2701–2711, Hong Kong, China. Association for Computational Linguistics.
[9]Pan J J, Wang J, Li G. Survey of Vector Database Management Systems[J]. arxiv preprint arxiv:2310.14021, 2023.
[10]党浩予.基于Python爬虫技术的网页内容文本大数据提取方法研究[J].电脑与电信,2023(08):90-93.DOI:10.15966/j.cnki.dnydx.2023.08.019.
[11]Yoo K M, Park D, Kang J, et al. GPT3Mix: Leveraging large-scale language models for text augmentation[J]. arxiv preprint arxiv:2104.08826, 2021.
[12]文心一言官方网站[EB/OL][2023-05-31].https:/hiyan.baidu.com/.
[13]智谱清言官方网站[EB/OL][2024-01-4].智谱AI (zhipuai.cn)
[14]General Language Model Pretraining with Autoregressive Blank Infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335, Dublin, Ireland. Association for Computational Linguistics.
[15]Hu E J, Shen Y, Wallis P, et al. Lora: Low-rank adaptation of large language models[J]. arxiv preprint arxiv:2106.09685, 2021.
[16]冯钧,李艳,杭婷婷.问答系统中复杂问题分解方法研究综述[J].计算机工程与应用,2022,58(17):23-33.
[17]Zhao Z, Chen H, Zhang J, et al. UER: An open-source toolkit for pre-training models[J]. arxiv preprint arxiv:1909.05658, 2019.
作者简介:孔令飞(1997—),男,安徽亳州人,硕士研究生,主要研究方向为自然语言处理,人工智能。田晓钰(2004—),女,内蒙古呼和浩特市人,本科在读,研究方向为老年社会工作。冯文慧(1992—),女,内蒙古呼和浩特人,硕士研究生,主要研究方向为大学生思想政治教育及创新创业。张斌斌(1991—),男,内蒙古呼和浩特人,硕士研究生,主要研究方向为思政教育。
项目名称:内蒙古自治区残疾人事业发展研究课题项目;项目编号:NMGZZOCL-2023-KTYJ-08

 京公网安备 11011302003690号
京公网安备 11011302003690号


