



- 收藏
- 加入书签

基于机器学习算法的新零售系统虚假流水识别模型构建探析
——以莆田烟草推广运用的新零售虚假流水识别模型为例
摘要:近年新零售终端扫码系统普及,零售数据以千万/ 月递增,但虚假扫码频发。科学监测庞大数据并精准识别虚假流水成工作难点。本文以莆田烟草虚假流水识别模型为例,基于时间序列分析与统计机器学习算法,探析模型构建,以推动客户真实扫码,提升系统数据质量,优化数据应用基础。
关键词:新零售;虚假流水识别;机器学习算法
1 引 言
2021 年11 月,福建省政府印发“十四五”数字福建专项规划,明确未来 5 年建成数字中国建设样板区的目标。在全社会数字化转型浪潮下,福建烟草加快建设智能营销“数据增值服务工程”,积极推进商业数字化转型,提出“数据一切化、一切数据化”要求。原始数据的真实性与准确性是数字化转型的“地基”,“地基不牢、地动山摇”,缺乏真实准确的原始数据,后续数据分析与应用将无从谈起。
2 把脉问诊探究新零售数据监测短板
“E 福通”是福建烟草主要的数据采集渠道,其终端销售数据质量对卷烟经济数字化、智慧化意义重大。但当前“E 福通”数据监测体系存在三项短板,大量店铺虚假刷码难精准识别,导致销售数据失真,影响上层决策可信度。
2.1 识别虚假扫码行为的成本过高
现有监测方法无法识别客户有意虚假扫码,判断依赖实地盘点库存与人工查流水,人力成本高。随着系统推广,客户数量增加,人工方式难度剧增,亟需机器自动识别以降本提效。
2.2 识别规则容易被破解
现有判断规则简单,易被客户测试破解。虚假扫码成本低、代价小,且成功后能享优惠、收益高,理性零售客户无论本性如何,都有强烈动机实施虚假扫码。
2.3 判断阈值设定不够智能
以往判断阈值仅靠人工凭业务经验设定,缺乏合理性,且无法根据数据特征与变化趋势实时自动更新,智能化不足,导致识别准确率低,影响精准度与公平性。
3 对症下药构建虚假流水识别模型
3.1“四步走”的总体思路
第一步,搭建流水数据库。从“E 福通”系统后台采集关联性高的相关数据字段,完成数据源的构建,并汇集至数据库管理软件中。第二步,设计识别指标。寻找和分析虚假扫码行为反映出的业务数据表现,并根据业务特征,设计、提取并聚合的一系列描述性统计指标。第三步,进行实时数据运算。依据设计出的识别指标,使用机器学习算法计算各店铺的数据特征离群度,并进行异常值检测,从而识别出疑似虚假扫码的店铺和对应流水。第四步,核验识别结果。对虚假扫码识别结果进行验证,并不断改进并优化模型。
3.2 精细化的模型实证构建
3.2.1 使用 MySQL 数据库进行数据源集成
深入分析虚假扫码行为表现和虚假流水数据特征,并充分考虑指标数据的可获得性和针对性,罗列出能反映虚假扫码行为的重要流水字段并进行合并整理及归纳,最终形成数据源和一系列原始变量。包括:订单 ID、店铺 ID、许可证 ID、店铺名称、店铺业态、订单时间、订单日期、商品ID、商品名称、商品包装单位、商品类型、支付账号、成交量、商品单价、成交金额、支付方式等,并将以上销售流水数据通过自动化数据集成写入 MySQL 数据库中。MySQL数据库管理软件可同时适配“E 福通”系统和烟草营销商业系统,支持大多数主流操作系统且可免费使用,兼顾了适配性、兼容性和成本低的优点。
3.2.2 运用业务直觉和数据驱动结合的方法设计识别指标清单
首先,基于数据特征分析,对数据源进行清洗,在不同时空粒度下进行统计聚合,可视化分析。随后,结合业务经验直觉,设计出一系列描述性统计指标,并计算指标阈值,用于后续的异常值检测。
3.2.3 运用孤立森林算法进行虚假流水识别计算
3.2.3.1 筛选“离群”店铺
虚假流水识别计算整体识别逻辑是:每家店铺的近期刷码流水数据将形成一系列的描述性统计指标。如果:由某家店铺刷码流水所产生的统计指标明显地偏离了绝大多数店铺所遵从的群体规律,称为“离群”。那么有理由怀疑,这家店铺近期可能存在虚假扫码行为。虚假扫码的具体表现由离群的统计指标的含义决定。利用机器学习的一种异常检测算法——孤立森林算法,可以检测出离群的店铺。孤立森林算法是一种基于集成学习的异常检测方法,具有精准度高、处理大数据时速度快的优良特性。
3.2.3.2 创建“孤立树”
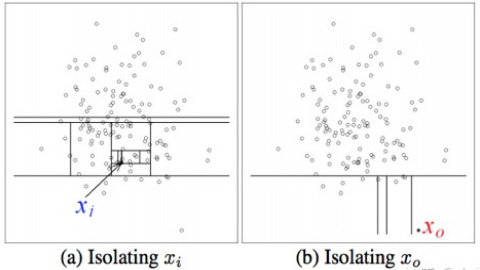
从训练数据中随机选择 Ψ 个点作为子样本,放入一棵孤立树的根节点;随机指定一个维度,在当前节点数据范围内,随机产生一个切割点 p,切割点产生于当前节点数据中指定维度的最大值与最小值之间;此切割点的选取生成了一个超平面,将当前节点数据空间切分为 2 个子空间:把当前所选维度下小于 p 的点放在当前节点的左分支,把大于等于 p 的点放在当前节点的右分支;在节点的左分支和右分支节点递归步骤 2、3,不断构造新的叶子节点,直到叶子节点上只有一个数据(无法再继续切割)或树已经生长到了所设定的高度 。直观理解:如下图所示,在这样的分割下,相比于群体内的正常店铺 x1,异常离群店铺 Δx0 会被更早地孤立出来,因而该树也被称为孤立树。孤立树是孤立森林的基础,孤立森林算法就是基于多棵孤立树的识别结果,集成学习这些结果,最终对“某家店铺是否在某指标上存在异常行为”这一问题进行研判。
图1 孤立树运算示意图
3.2.3.3 孤立森林计算异常得分
使用上述切割方法,获得 t 个孤立树。对于每家店铺的每个指标 x,综合计算其每棵树的结果,得到该店铺该指标的异常得分。异常得分使用下式计算:
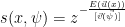
其中, 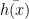 为 x 在每棵孤立树中所在的高度,
为 x 在每棵孤立树中所在的高度, 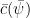 是店铺总数为 Ψ 时路径长度的平均值。
是店铺总数为 Ψ 时路径长度的平均值。
直观理解为:平均地,若店铺 x 在各孤立树中都能很早地就被孤立出来,那么它在每棵孤立树中的高度就会比较低,按公式计算,其异常分数就会很高。由于指数函数的特性,随着店铺 x 在每课树孤立树中的高度越来越低,孤立森林算法对它怀疑度的增加速度将会越来越大。
3.2.4 运用数据可视化和人工验证结合方法进行识别结果核验
对于上一步运算得出的虚假流水识别结果,先经过数据可视化分析,验证相应指标是否能准确标记前期人工已标记的少量虚假扫码店铺,再经人工调取流水明细进行效果核验。下面以一个典型的虚假扫码行为识别指标为例,展示数据可视化核验和人工核验的过程:
表2 典型虚假流水识别指标举例

识别结果可视化如下图所示:
图2 识别结果可视化展示图
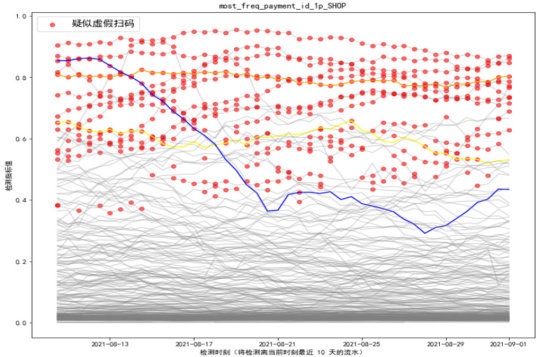
每条半透明灰线代表一家店铺。每 12 个小时检测一次,同一家店的所有时刻检测结果就连成了一条灰线。深灰色区域反映了绝大多数店铺在该统计指标上存在着群体规律。有少量的灰线明显地远离深灰色区域,这些异常会被机器学习算法识别并标注出来(半透明红点),说明这些点对应的店铺和时段存在疑似虚假刷码的行为。同时,根据离群程度的大小,即每个红点到深灰色区域的不同距离,算法可以得到不同的“怀疑度”。经人工标记的、存在虚假扫码行为的店铺,用蓝色、橙色、黄色等不同颜色折线绘制。由此可见,疑似存在虚假扫码的店铺及流水数据均可被模型完整识别出来。
4 去疴除弊优化模型应用效果
优化后的模型可有效弥补新零售数据监测中识别成本高、规则易破解、阈值不够智能的短板。
4.1 自动识别作业降低时间及人力成本
采用机器自动识别监测“E 福通”虚假流水,替代以往单纯人工作业模式,平均单户作业耗时缩减至 1.94 分钟,大幅降低时间与人力成本,显著提升虚假流水识别效率。
4.2 合理设置规则提高识别准确率
模型试运行期间,通过调整监测指标及计算标准验证实际效用,选取全市“E 福通”终端流水数据实证核验,对异常客户名单开展数据可视化与人工复核,识别准确率稳定在 85% 以上。
4.3 科学设置阈值实现智能化质量评估
评估负向指标运算公式、判断阈值和权重配置均由机器学习定义,并通过系统进行自动运算,有效规避人工操作的主观性,实现对数据质量的客观评价。
5 结 语
随着福建“E 福通”系统推广,零售数据量将几何式增长,保障数据质量、识别虚假流水势在必行。本文结合莆田烟草实例,基于机器学习分析模型构建路径,具借鉴推广价值。未来可积累数据与经验,挖掘更多识别指标优化模型,推动客户真实扫码,提升数据质量,为卷烟行业数字化转型护航。
参考文献:
[1] 王燕晋,易忠林,郑思达,刘岩,孙海涛 . 基于孤立森林算法的电力用户数据异常快速识别研究 [J]. 电子设计工程 .2022(03):11-14.
[2] 林国顺,王野 . 基于自编码器 - 孤立森林的网购消费者异常行为检测 [J]. 计算机应用与软件 .2022(02):253-258.
[3] 蔡伟钊 . 数字化转型中卷烟零售终端的新零售应用探讨 [J]. 现代商贸工业 .2022(15):47-49.
作者简介:陈小燕(出生年份:1979 年7 月28 日),性别:女,民族:汉,籍贯:福建省福清市,职务:科员,职称:助理工程师,学历:本科,单位:,研究方向:数字分析与应用。

 京公网安备 11011302003690号
京公网安备 11011302003690号


