



- 收藏
- 加入书签

基于地区人均消费水平的聚类分析
 打开文本图片集
打开文本图片集
作者简介:黄镓成(1999-),男,汉族,浙江绍兴人,应用统计硕士,单位:浙江财经大学应用统计专业,研究方向:混合模型及聚类分析
摘要:不同地区居民人均消费水平受经济发展因素的影响表现出差异性。但不同地区经济发展水平也有相似性,本文结合居民人均消费数据,完成居民消费数据的描述性和探索性数据分析,同时对不同领域消费水平的相关性分析,基于主成分分析对数据进行降维,并对31省市进行了聚类分析,研究了不同省份居民人均消费水平的相似性和差异性。通过聚类分析,我们发现不同地区的消费模式呈现出明显的差异和相似性,这些差异可能受到地理、文化、政策等多方面因素的影响。最后,针对聚类结果,本文提出了相应的政策建议。
关键词:居民人均消费;数据挖掘;数据分析;聚类分析
一、描述性分析
描述性统计是指运用制表和分类,图形以及计算概括性数据来描述数据特征的各项活动。描述性统计分析要对调查总体所有变量的有关数据进行统计性描述,主要包括数据的频数分析、集中趋势分析、离散程度分析、分布以及一些基本的统计图形。本次分析主要基于居民人均消费,涉及不同地区在食品烟酒,衣着, 居住,生活用品,交通通信, 教育文化娱乐, 医疗保健, 其他用品及服务[1]。
(一)统计分析
从数据类型看,地区为字符型数据,其他为数值型数据。不同行业人均消费水平表现不同。从均值看,食品烟酒类最高、居住其次。
(二)数据分布
数据分布根据数据类型可分为离散变量概率分布和连续变量概率分布。其中离散变量概率分布有二项分布、伯努利分布、泊松分布。连续变量概率分布有均匀分布、正态分布、指数分布、伽玛分布、偏态分布、贝塔分布、威布尔分布、卡方分布、F分布。本文主要研究的是连续变量,其中正态分布是比较常见的分布类型。
正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution),最早由棣莫弗(Abraham de Moivre)在求二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。
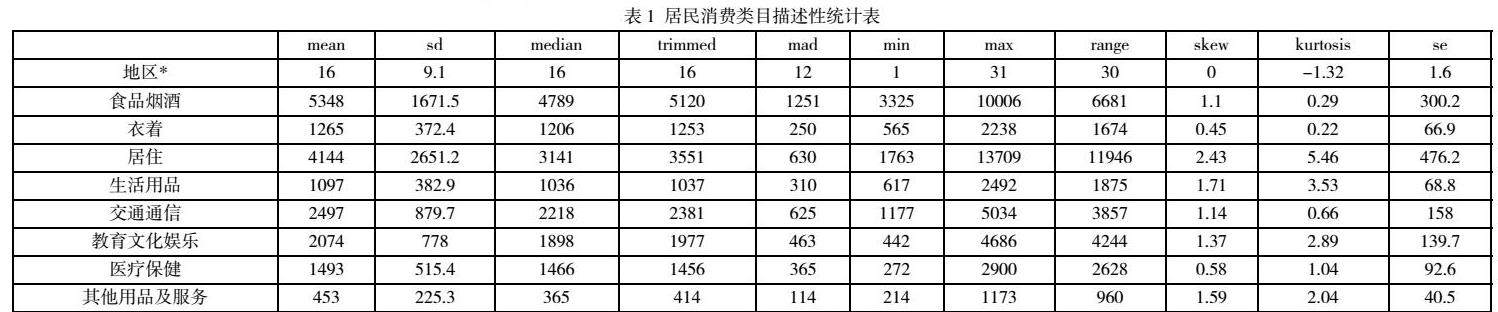
另外的,在统计学中,QQ图是一个用于比较两个概率分布的图形方法。如果这两个分布进行比较相似,QQ图的点会在45度线左右。如果两个分布是线性的关系,QQ图的点出会大约在一条线左右,但不一定是45度线。QQ图图形化地显示出如位置、规模、性质及偏类的不同。QQ图可以用来比较采集的数据 或理论分布的。用QQ图来比较两个数据样本可以被视为一种非参数的比较概率分布的方法。
判断数据是否正态分布,QQ图上的点是否近似地在一条直线附近,图形是直线说明是正态分布,而且该直线的斜率为标准差,截距为均值,用QQ图还可获得样本偏度和峰度的粗略信息。从分布图上看,居住明显不服从正态分布,呈现偏态分布。
(三)箱线图分析
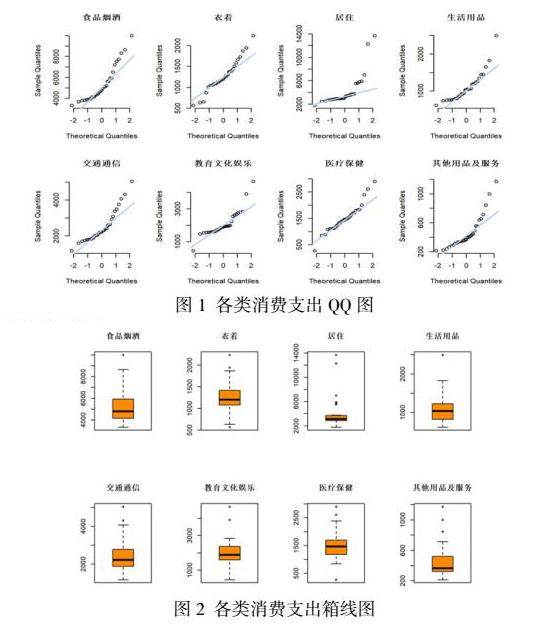
箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。在各种领域也经常被使用,常见于品质管理。它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较。
箱线图的绘制方法是:先找出一组数据的上边缘、下边缘、中位数和两个四分位数;然后, 连接两个四分位数画出箱体;再将上边缘和下边缘与箱体相连接,中位数在箱体中间。从箱线图上可以看出,所有的数值型数据均存在异常点。
(四)相关性分析
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
相关性不等于因果性,也不是简单的个性化,相关性所涵盖的范围和领域几乎覆盖了我们所见到的方方面面,相关性在不同的学科里面的定义也有很大的差异。
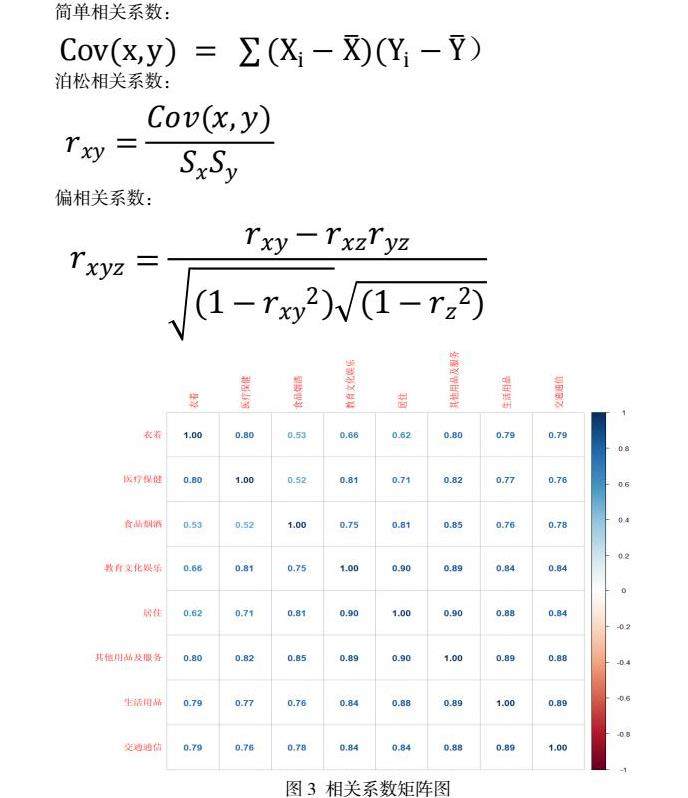
相关系数是最早由统计学家皮尔逊设计的统计指标,是研究变量之间线性相关程度的量,一般用字母 r 表示。由于研究对象的不同,相关系数有多种定义方式,较为常用的是皮尔逊相关系数。相关表和相关图可反映两个变量之间的相互关系及其相关方向,但无法确切地表明两个变量之间相关的程度。相关系数是用以反映变量之间相关关系密切程度的统计指标。
相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。需要说明的是,皮尔逊相关系数并不是唯一的相关系数,但是最常见的相关系数,以下解释都是针对皮尔逊相关系数。依据相关现象之间的不同特征,其统计指标的名称有所不同。如将反映两变量间线性相关关系的统计指标称为相关系数(相关系数的平方称为判定系数);将反映两变量间曲线相关关系的统计指标称为非线性相关系数、非线性判定系数;将反映多元线性相关关系的统计指标称为复相关系数、复判定系数等。
从相关性来看,居民人均消费在不同领域的有一定的相关性,例如居住和其他用品及服务达到相关系数达到0.9,生活用品和交通通信也达到了0.89,因此在做其他分析的时候需要考虑相关关系[4]。
二、主成分分析
我们在作数据分析处理时,数据往往包含多个变量,而较多的变量会带来分析问题的复杂性。主成分分析(Principal components analysis,以下简称PCA)是一种通过降维技术把多个变量化为少数几个主成分的统计方法,是最重要的降维方法之一。它可以对高维数据进行降维减少预测变量的个数,同时经过降维除去噪声,其最直接的应用就是压缩数据,具体的应用有:信号处理中降噪,数据降维后可视化等。
PCA的主要目标是将特征维度变小,同时尽量减少信息损失。就是对一个样本矩阵,一是换特征,找一组新的特征来重新表示;二是减少特征,新特征的数目要远小于原特征的数目。
通过PCA将n维原始特征映射到维(k<n)上,称这k维特征为主成分。需要强调的是,不是简单地从n 维特征中去除其余n- k维特征,而是重新构造出全新的k维正交特征,且新生成的k维数据尽可能多地包含原来n维数据的信息。例如,使用PCA将20个相关的特征转化为5个无关的新特征,并且尽可能保留原始数据集的信息。PCA是一种线性降维方法,即通过某个投影矩阵将高维空间中的原始样本点线性投影到低维空间,以达到降维的目的,线性投影就是通过矩阵变换的方式把数据映射到最合适的方向。
主成分涉及的主要问题:
(1)对实对称方阵,可以正交对角化,分解为特征向量和特征值,不同特征值对应的特征向量之间止交,即线性无关。特征值表示对应的特征向量的重要程度,特征值越大,代表包含的信息量越多,特征值越小,说明其信息量越少。
(2)方差相当于特征的辨识度,其值越大越好。方差很小,则意味着该特征的取值大部分相同,即该特征不带有效信息,没有区分度;方差很大,则意味着该特征带有大量信息,有区分度。
(3)协方差表示不同特征之间的相关程序,例如,考察特征x和y的协方差,如果是正值,则表明x和y正相关,即x和y的变化趋势相同,越大y越大;如果是负值,则表明x和y负相关,即x和y的变化趋势相反,x越小y越大;如果是零,则表明x和y没有关系,是相互独立的。
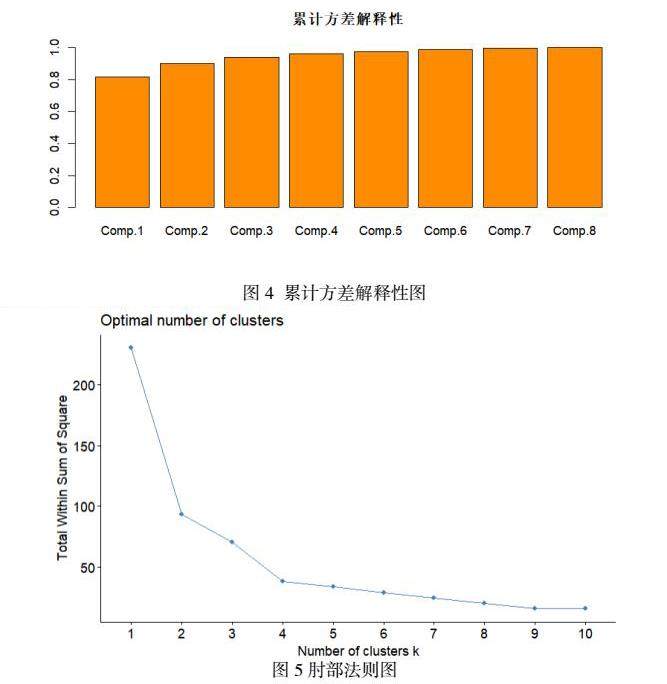
结合前面的相关性分析,因为有的领域的平均消费水平相关性较高,对居民消费数据做主成分分析的目的是进行降维,首先对数据进行标准化处理,可以看出第一主成分方差解释在0.8以上,后续逐渐减少,到第四个主成分的时候基本在一个水平,并且前四个主成分的累计方差解释性达到96%,因此本次主成分分析设置n_components = 4[5]
三、聚类分析
为了挖掘不同案例之间的共性,本文基于聚类算法进行挖掘分析。聚类分析通常使用数据集中对象之间的相似性度量来评估聚类的质量,轮廓系数(silhouette coefficient)就是这种相似性度量,是簇的密集与分散程度的评价指标。轮廓系数的值在-1和1之间,该值越接近1,簇越紧凑,聚类越好。当轮廓系数接近1时,簇内紧凑,并远离其他簇。如果轮廓系数sil接近1,则说明样本聚类合理;如果轮廓系数sil 接近-1,则说明样本i更应该分类到另外的簇;如果轮廓系数sil近似为0,则说明样本i在两个簇的边界上。所有样本的轮廓系数 sil的均值称为聚类结果的轮廓系数,是该聚类是否合理、有效的度量[2]。
(一)均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
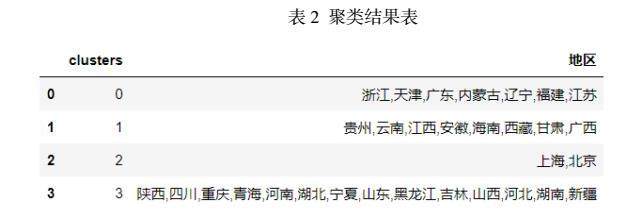
基于主成分的结果对不同地区的进行聚类分析,可以知道哪些地区在消费水平上较为接近,哪些差距较大。聚类分析要先确定聚类个数,本次分析采用肘部法确定聚类个数,肘部法将簇间误差平方和看成是类簇数量k的函数。随着k的增加,每个类簇内的离散程度越小,总距离平方和也就在不断减小,并且减小的程度越来越不明显。极限情况是当k=N时,每个类簇只有一个点,这时总的误差平方和为0。当k继续增大时,总误差平方和减少的趋势不再明显,也就是“拐点”处。上图可以看出拐点在K=4。
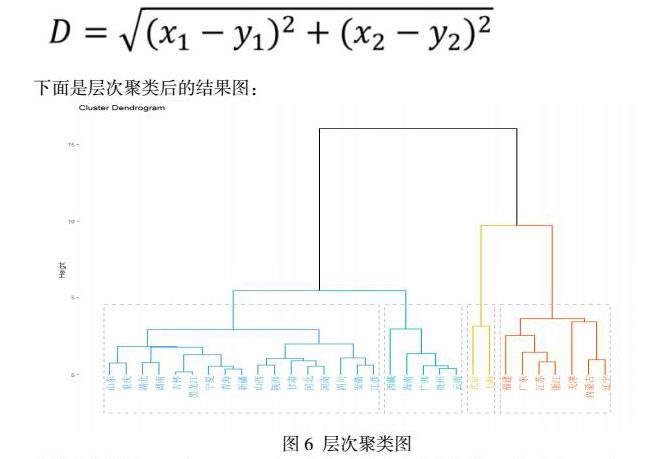
(二)层次聚类(Hierarchical Clustering)是通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。层次聚类算法分为两类:自上而下和自下而上。自下而上的算法在一开始就将每个数据点视为一个单一的聚类,然后依次合并类,直到所有类合并成一个包含所有数据点的单一聚类。计算过程为首先将每个数据点作为一个单个类,然后根据选择的度量方法计算两聚类之间的距离。然后对所有数据点中最为相似的两个数据点进行组合,形成具有最小平均连接的组。最后重复迭代步骤2直到只有一个包含所有数据点的聚类为止。层次聚类的合并算法通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程。简单的说层次聚类的合并算法是通过计算每一个类别的数据点与所有数据点之间的距离来确定它们之间的相似性,距离越小,相似度越高。并将距离最近的两个数据点或类别进行组合,生成聚类树[3]。层次聚类使用欧式距离来计算不同类别数据点间的距离(相似度)。我们在前面的几篇文章中都曾经介绍过欧氏距离的计算方法,本篇文章将通过创建一个欧式距离矩阵来计算和对比不同类别数据点间的距离,并对距离值最小的数据点进行组合。以下是欧式距离的计算公式:
下面是层次聚类后的结果图:
均值聚类结果可以看出,基于居民人均消费的聚类分析将31省市分了4类,上海和北京两个经济发达的地区归为了一类,江苏、浙江、广东、天津、福建等沿海省份归为了一类,其他内陆地区也相应的都各自归类,聚类结果比较符合我们的认知。层次聚类分析的结果与均值聚类的结果基本一致。
四、总结与讨论
(一)全文总结
本文通过分析不同地区居民人均消费数据,结合统计分析和数据挖掘了不同地区居民人均消费特征。不同的地区在不同领域的平均消费水平上表现出差异性,因此本文在此基础上,考虑了对地区进行聚类分析,在不同领域消费水平上表现近似的地区可归为一类。
本文尝试了两种聚类方式,即均值聚类和层次聚类。首先基于肘部图分析做确定最佳聚类个数为4类,然后分别进行均值和层次聚类。结果显示,均值聚类和层次聚类的结果基本一致。聚类算法将上海和北京两个经济发达的地区归为了一类,江苏、浙江、广东、天津、福建等沿海省份归为了一类,其他内陆地区也相应的都各自归类,聚类结果比较符合我们的认知。
(二)政策建议
对于消费水平较低的地区,实施教育和培训计划,提高劳动力技能水平,以促进就业和收入增长,这有助于创造更多的机会,提高人们的生活水平;为那些有创业意愿的人提供创业支持和资源,帮助他们开展经济活动;其次,教育部门对消费者加强教育,提高他们的金融素养和消费理念,鼓励理性消费和储蓄,这可以帮助避免不必要的浪费和债务问题;政府部门应建立健全的社会保障和福利政策,为弱势群体提供基本保障,减轻社会不平等问题。对于消费水平较高的地区,推动可持续发展和环保措施,鼓励绿色消费和资源的有效利用,以减少对环境的负面影响。总而言之,政策制定者应该考虑每个地区的独特性,制定具有针对性的政策措施,以适应不同地区的发展需求。
参考文献:
[1]城镇居民消费支出影响因素的计量分析[J].化丽娜.现代经济信息.2017(01)
[2]基于聚类分析的我国城镇居民消费结构差异化研究[J].罗甜甜,龚日朝,马霖源.南华大学学报(自然科学版).2016(02)
[3]聚类分析在我国城镇居民消费结构研究中的应用[J].张月,张金凤,王泓娜,关静.辽宁大学学报(自然科学版).2004(01)
[4]城镇居民人均可支配收入对人均消费支出的影响研究——基于凯恩斯消费函数的实证分析[J]. 童百利,杨贤传,李国安.长春大学学报.2012(11)
[5]基于非参数面板数据模型的我国城镇居民消费与收人关系的区域差异性实证分析[J].武新乾,司福宁,田萍.数理统计与管理.2016(04)

 京公网安备 11011302003690号
京公网安备 11011302003690号


