



- 收藏
- 加入书签

云计算环境下大数据处理与存储优化策略研究
 打开文本图片集
打开文本图片集
摘要:在云计算环境中,有效的大数据处理与存储优化策略对于提高性能和降低成本至关重要。本文针对不同数据访问模式和存储需求,探讨了数据分区、分层存储、压缩编码、备份恢复、数据加密和访问控制等关键策略。通过案例研究和性能分析,展示了如何通过这些策略最大化云存储资源的利用率,确保数据安全性和系统可靠性,以及提升数据处理效率和用户体验。
关键词:云计算环境;大数据处理;存储优化
1引言
在当今信息技术快速发展的背景下,云计算和大数据技术成为了现代信息处理的核心。云计算环境提供了高效的计算和存储资源,为大数据处理提供了广阔的空间和可能性。然而,随着数据规模的迅速增长,如何在云计算环境下实现有效的大数据处理与存储优化成为了一个重要课题。本文旨在探讨在云计算环境下的大数据处理与存储优化策略,通过分析现有的技术和方法,提出适应云计算特点的创新解决方案。研究将聚焦于优化大数据存储结构、提高数据处理效率、降低成本以及保障数据安全等方面,旨在为提升大数据在云计算平台上的应用效果和性能提供理论支持和实践指导。
2云计算环境下大数据处理与存储技术分析
2.1 大数据处理技术
云计算环境下的大数据通常采用分布式存储系统,如Hadoop的HDFS(Hadoop Distributed File System)和亚马逊的S3(Simple Storage Service)。这些系统通过将数据分布存储在多个节点上,实现了数据的高可靠性和扩展性。大数据处理涉及到批处理和流式处理两种主要模式。批处理通常用于离线数据处理,例如MapReduce模型,适用于大规模数据的分布式计算;而流式处理则支持实时数据处理,如Apache Kafka和Apache Flink等技术,能够实时处理数据流并产生实时结果。除了Hadoop,Spark等大数据处理框架也在云计算环境中得到广泛应用。Spark具有内存计算能力,能够加速大数据处理过程,同时提供了丰富的API支持,使得复杂的数据分析任务得以实现[1]。
2.2 大数据存储技术
2.2.1 分布式文件系统
在云计算环境下,大数据存储技术的核心之一是分布式文件系统。分布式文件系统通过将大数据分布存储在多个节点上,提供高可靠性、高性能和可扩展性,以应对大规模数据处理的需求。
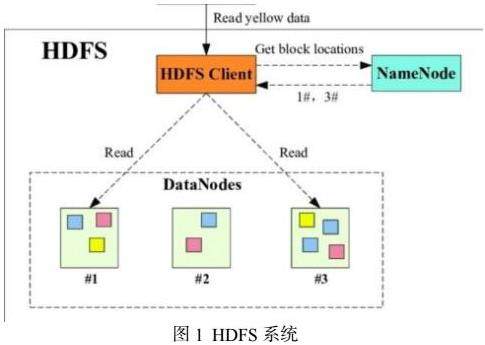
如图1,HDFS是Apache Hadoop生态系统的一部分,专为大规模数据处理而设计。它将大文件分割成多个数据块,并存储在多个节点上,保证数据的冗余和可靠性。同时,GFS是Google开发的分布式文件系统,与HDFS类似,但在设计上有一些差异。它也采用分块存储和数据冗余来提高可靠性。
2.2.2 NoSQL数据库
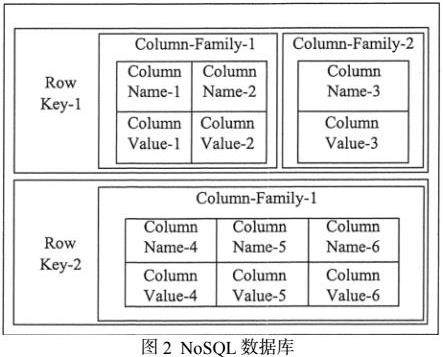
NoSQL数据库是为了应对大规模、高并发以及非结构化数据而设计的数据库系统。主要类型包括键值存储,以键和对应的值进行数据管理。
如Redis和DynamoDB;列族存储,适合大量数据的快速读取,如图2,比如Cassandra和HBase;文档型数据库,以灵活的文档形式存储数据,如MongoDB和Couchbase;以及图形数据库,用于复杂关系的图数据处理,如Neo4j和ArangoDB。这些数据库类型各有特点,能够在不同的数据处理场景中发挥优势,例如在云计算、大数据分析和实时数据处理中,提供了高性能、高可扩展性以及灵活的数据模型。选择适合的NoSQL数据库取决于应用的具体需求,包括数据结构、访问模式和数据一致性要求等因素。
2.2.3 NewSQL数据库
NewSQL数据库是一种相对较新的数据库技术,旨在兼顾传统关系型数据库(如MySQL、PostgreSQL)的ACID事务特性和NoSQL数据库的分布式架构和横向扩展能力。这些数据库试图解决传统关系型数据库在处理大规模数据和高并发访问时的性能瓶颈。与传统关系型数据库一样,NewSQL数据库提供了强一致性的ACID事务,确保数据的完整性和可靠性。NewSQL数据库通过分布式的架构来实现横向扩展,能够处理大规模数据集和高并发请求。通过并行处理和优化的数据存储和查询引擎,NewSQL数据库能够实现较高的性能水平,满足现代应用对响应时间和吞吐量的要求[2]。
3云计算环境下大数据处理与存储优化策略
3.1 数据处理优化策略
使用云计算平台提供的分布式计算框架(如Hadoop、Spark),充分利用云上的计算资源进行并行处理。通过将大数据集分割成小块,并在多个计算节点上同时处理,可以显著缩短处理时间。对于大数据集,采用有效的压缩算法(如Snappy、Gzip)减少数据存储空间和传输成本。选择适当的数据编码方式(如Parquet、Avro)可以提高数据读取效率。对于需要实时响应的应用场景,使用流式处理框架(如Apache Kafka、Flink)进行实时数据处理和分析。这些框架可以有效地处理持续生成的数据流,实现低延迟的数据处理[3]。通过自动化扩展(如AWS Auto Scaling、Azure Autoscale),根据实际需求动态调整计算资源,提高系统的弹性和稳定性。
3.2 数据存储优化策略
根据数据的访问模式和要求,选择适合的云存储服务。例如,对于需要高可用性和耐久性的数据,可以选择AWS S3、Azure Blob Storage等对象存储服务;对于需要低延迟和高吞吐量的应用,可以考虑使用AWS EBS、Azure Disk等块存储服务。将数据按照访问频率、重要性等因素进行分区和分层存储。将经常访问的热数据存储在高性能存储介质上,如SSD,而较少访问的冷数据则可以存储在低成本的存储介质上,如标准硬盘或云归档存储服务(如AWS Glacier、Azure Archive Storage),以降低存储成本。
总结
在云计算时代,有效的大数据处理与存储优化策略是企业实现竞争优势和业务创新的关键。本文深入探讨了数据分区、分层存储、压缩编码、备份恢复、数据加密和访问控制等策略在云环境中的应用和效果。通过研究和实证分析,证明了这些策略对于提升性能、降低成本、增强数据安全性至关重要。未来,随着云技术的进一步演进和数据量的持续增长,继续优化和创新这些策略将是研究和实践的重要方向,实现更高效、更安全的大数据处理与存储管理,推动云计算技术在各行各业的广泛应用与进步。
参考文献
[1] 李德刚,王成威,于振,等.云计算环境下大数据的大规模任务处理研究[J].通信电源技术, 2023, 40(15):109-111.
[2] 苏兆兆,杨兆龙,苏婧琼,等.大数据和云计算环境下网络安全分析与解决方案研究[J].信息系统工程, 2023(2):72-74.
[3] 周雪芳,刘树龙,周海龙.复杂环境中高可用船舶AIS大数据信息处理方法[J].舰船科学技术, 2022, 44(6):4.DOI:10.3404/j.issn.1672-7649.2022.06.028.

 京公网安备 11011302003690号
京公网安备 11011302003690号


