



- 收藏
- 加入书签

基于图像序列数据的驾驶员动态情绪识别方法
 打开文本图片集
打开文本图片集

摘 要:【目的】驾驶员状态(如疲劳、分心、情绪等)识别是一类面向微观层面的用户行为模式识别问题,目前普遍认为,驾驶员情绪是影响驾驶安全性的一个重要因素,本文旨在建立融合面部表情和头部姿态的驾驶员动态情绪识别模型以及基于情绪诱发及实车条件下的驾驶情绪识别算法的研究。【方法】对驾驶员面部表情和动态情绪图像采集,设计深度迁移学习的情绪识别模型和数据处理算法。【结果】与单模态识别模型相比,基于多模态融合的情感识别准确率高达 92.79%,远高于单独的面部特征情感识别准确率87.96%和头部姿态情感识别准确率66.37%,基于多模态融合的情感识别优势明显。【结论】为基于视觉图像的情绪识别算法用于情绪判断、面部特征分类、驾驶体验,产品服务创新研究提供理论参考。
关键词:;深度学习;情绪识别;多模态;智能网联汽车
引言
情感计算最早由 MIT 媒体实验室的 Picard 教授[1]于1977年提出,她认为情感计算源于情感,与情感相关或对情感能够施加影响的计算。中国学者胡包刚[2]对情感计算进行了大量研究,提出情感计算的最终目的是为了赋予计算机感知、理解和适应人的情感的能力。在人-车-环境交通系统中,驾驶员在驾车行驶过程中面对实时多变的车辆状态及外部道路环境刺激时情绪状态也在实时变化。
当前,对于驾驶员情绪识别的研究主要停留在人工评估阶段。因此,基于非接触式检测的驾驶员情绪识别,值得更深入研究。然而,当前针对基于机器视觉的驾驶员情绪识别问题,研究者大多采用基于面部表情的单模态情感识别模型,情绪识别准确率较低。研究表明,身体姿态信号是人类交流情感的重要载体之一,它在有效地协同或补充着情感信息[3],本实验主要在多模态下的情绪识别研究。
1 多模态融合和深度学习的动态情绪识别模型设计
1.1 CNN+LSTM 的面部表情识别模型设计
利用CNN+LSTM网络进行驾驶员面部表情图像序列数据处理识别动态情绪的模型架构:首先经过预处理得到的面部表情图像序列数据被输入给经过预训练的CNN网络,利用CNN模型依次提取图像序列中情感相关的空间特征;然后将提取到的空间特征按帧次序输入到LSTM网络,利用LSTM模型依次提取图像序列中情感相关的时域特征,同时将时域特征输出到全连接层进行特征重组;最后利用分类层实现情绪识别,并输出相应的驾驶员情绪标签。
1.1.1 CNN 网络结构设计
使用人脸识别模型VGGFace[4]模型作为迁移学习的预训练模型,将VGGFace模型卷积模块的网络参数直接作为面部表情识别 CNN 网络卷积层参数进行情感相关的空间特征提取。
VGGFace是由牛津大学在 VGG16的网络结构上,通过人脸数据集 LFW 训练得到的人脸识别模型,整个模型由5个卷积模块构成,每个卷积模块包括2-3个卷积层和1个最大池化层,激活单元为ReLU函数。输入的图片数据经过5个卷积模块提取图像视觉特征后通过3个全连接层与1个SoftMax层进行分类。本实验将预训练得到的深度人脸识别模型 VGGFace网络参数迁移到驾驶员面部情绪识别任务中,移除VGGFace网络的全连接层及SoftMax层,将剩余的卷积神经网络参数直接作为面部情绪识别CNN网络卷积层参数进行情感相关的空间特征提取。
1.1.2 LSTM 网络结构设计
CNN网络从每张人脸图像中提取到了情感相关的空间特征,但是无法提取人脸的时域特征,因此需要利用 LSTM 网络提取人脸的时域特征。考虑到用于面部情绪识别的数据集样本量较小,训练过程中为避免出现过拟合,本实验LSTM 网络设置1层,LSTM 网络单元数T 。其中,网络单元数T 由输入到面部表情识别模型的图像数列帧数量决定。从驾驶员面部表情图像序列中经过CNN网络提取得到的情感相关的空间特征向量序列为x1x2 x3...xT ,输入到LSTM网络得到的最终输出状态转移向量序列为h1h2h3...hT ,状态转移向量的维数取决于LSTM单元的隐藏节点数H,本章中H设定为 128。LSTM 层之后增加一个全连接层,由 LSTM每个时序输出的信息拼接而成,全连接层输入向量维度为T×H ,输出维度为K,K是驾驶员情绪的类别数,在本章中K=3,驾驶员情绪类别为积极情绪、中性情绪和消极情绪。在LSTM 网络全连接层之后,会连接一个SoftMax层,计算输出各情绪的概率。
1.2 基于迁移学习的 3DCNN 网络结构设计
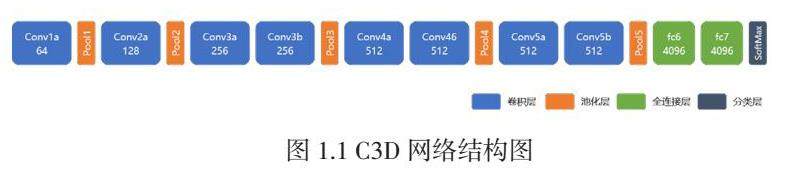
C3D网络是由Du Tran等人[5]在 2015ICCV 会议上提出的3D卷积网络,其网络结构如图1.1所示:C3D网络包含5个卷积模块,2个全连接层和1个SoftMax分类层,前面2个卷积模块各包含1个卷积层和1个最大池化层,后面3个卷积模块各包含2个卷积层和1个最大池化层。其中卷积核的尺寸和卷积步长分别都是3×3×3和1×1×1,第1~8个卷积层的卷积核个数分别是64、128、256、256、256、256、256、256。第1个池化层的采样窗口和采样步长大小分别是1×2×2和1×2×2,其余4个池化层的采样窗口和采样步长大小分别都是2×2×2和2×2×2,这样可以帮助网络能更早提取并保留住时间特征信息。
2 实验与分析
2.1 数据采集设备介绍
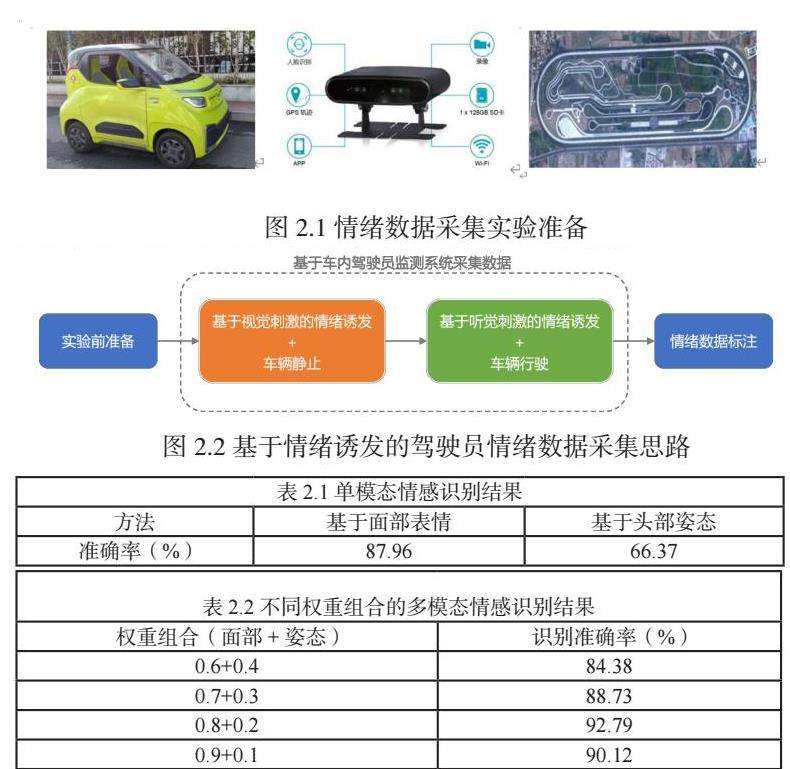
本实验选用上汽通用五菱汽车股份有限公司的宝骏E200电动汽车作为实验车辆,广州敏视数的驾驶员监测设备作为数据采集装置,封闭实验道路作为实验场地,如图2.1所示。
2.2 数据采集流程
整体思路如图2.2所示,将情感色彩材料呈现给驾驶员,从而诱发驾驶员的相应情绪,在特定情绪持续的一段时间内,利用车内驾驶员监测系统采集驾驶员在车辆静止及车辆行驶状态下的包含面部表情和头部姿态的图像序列数据,跟驾驶员确认情绪诱发效果确定数据是否被采纳,若被采纳,则对采集到的图像序列进行绪标注。
2.3 实验平台及数据参数
本实验采用开源的深度学习框架Tensorflow完成,模型训练的硬件环境如下:CPU为Intel i7-7700K,内存64G,显存8G,GPU 为 Nvidia GTX1080,通过Python3.6完成模型性能测试。
2.4 实验结果及分析
从上表可知,面部特征对情绪识别有重要意义,基于面部特征的情绪识别准确率高达87.96%,而基于头部姿态的情绪识别准确率只有 66.37%,远低于面部表情,即不同特征感知情绪的能力不同。
本实验采用的是多模态决策层融合策略,需要多不同模态的权重进行确定。本节分别选取0.6+0.4、0.7+0.3、0.8+0.2、0.9+0.1的不同权重组合(面部特征+头部姿态)进行分析,其情绪识别结果见表2.2
从上表可知,面部情感特征的权重要高于头部姿态权重,面部表情是在表达人的情感方面最重要的通道。但其权重也不是越高越好,说明人的情感表达还是要依赖多通道的融合。本实验选取 0.8+0.2 的权重组合进行后续的研究。
通过对比表2.1和表2.2 可知,基于多模态融合的情感识别准确率高达92.79%,远高于单独的面部特征情感识别准确率87.96%和头部姿态情感识别准确率66.37%,基于多模态融合的情感识别优势明显。
从表2.3可以发现:当两个通道融合时,面部感知“消极”情绪的局限和头部姿态感知“积极”情绪的局限得到互补改进,“中性”情绪的识别率提高,从而获得整体识别正确率的提高,说明面部表情和头部姿态都对情绪识别有所贡献,并且表达的信息可有效地互补,融合面部特征和头部姿态能显著提高识别情绪状态的能力和可靠性。
3 结论
本实验以驾驶员情绪的动态变化为分析对象:首先提出了一种基于智能网联汽车图像序列数据的融合面部表情和头部姿态的驾驶员情绪识别方法,通过CNN+LSTM网络提取面部情感,通过3DCNN提取头部姿态情感,然后基于决策层融合识别出驾驶员情感;其次设计了基于情绪诱发的驾驶员情绪数据采集方案,在车辆停止时用视觉刺激诱发被试情绪,车型行驶状态下用声音刺激诱发被试情绪,采集的驾驶情绪数据集为情绪识别模型的训练奠定了基础;然后,基于单模态及多模态分析的准确性做了讨论,验证了模型的有效性;最后重点分析了人在不同驾驶情境下的情绪变化特点,其多模态融合下的情感识别能够显著提高识别情绪状态的能力和可靠性。驾驶员情绪是一种重要的微观行为,直接决定了到用户驾驶体验,对其变化特点进行分析可为产品服务创新提供重要的洞察。
参考文献
[1]Picard R W. Affective computing: challenges[J]. International Journal of HumanComputer Studies, 2003,59(1-2): 55-64.
[2]巨晓正. 基于特征融合的语音情感识别方法的研究[D].东南大学, 2016.
[3]Ambady N, Rosenthal R. Thin slices of expressive behavior as predictors of interpersonal consequences: A meta-analysis[J]. Psychological bulletin, 1992,111(2): 256.
[4]Wang M, Deng W. Deep face recognition: A survey[J]. Neurocomputing, 2021,429:215-244.
[5]Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3dconvolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015:4489-4497.
作者简介:胡朝辉(1981.12),男,汉,博士,湖南大学机械与运载工程学院,副研究员,主要研究方向:汽车轻量化技术、数字孪生
作者简介:杨光德(1981.06),男,汉,硕士,广西柳州联耕科技有限公司,总工,主要研究方向:汽车整车集成、底盘结构及性能设计
作者简介:甘强(1974.10),男,汉,硕士,广西玉柴新能源汽车有限公司,技术部长,主要研究方向:汽车整车集成、电气控制
基金项目:广西创新驱动 桂科(AA21077019)新一代智能物流车架构共用型电子电气控制关键技术开发与应用; 广东省重点领域研发计划项目(2022B0909070001)新能源汽车铝合金超大型结构件制造成型技术

 京公网安备 11011302003690号
京公网安备 11011302003690号


